Version 1.4.0¶
We are happy to announce the AutoGluon 1.4.0 release!
AutoGluon 1.4.0 introduces massive new features and improvements to both tabular and time series modules. In particular, we introduce the extreme preset to TabularPredictor, which sets a new state of the art for predictive performance by a massive margin on datasets with fewer than 30000 samples. We have also added 5 new tabular model families in this release: RealMLP, TabM, TabPFNv2, TabICL, and Mitra. We also release MLZero 1.0, aka AutoGluon-Assistant, an end-to-end automated data science agent that brings AutoGluon from 3 lines of code to 0. For more details, refer to the highlights section below.
This release contains 69 commits from 18 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/1.3.1…1.4.0
Join the community: 

This release supports Python versions 3.9, 3.10, 3.11, and 3.12. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.4.0.
Spotlight¶
AutoGluon Tabular Extreme Preset¶
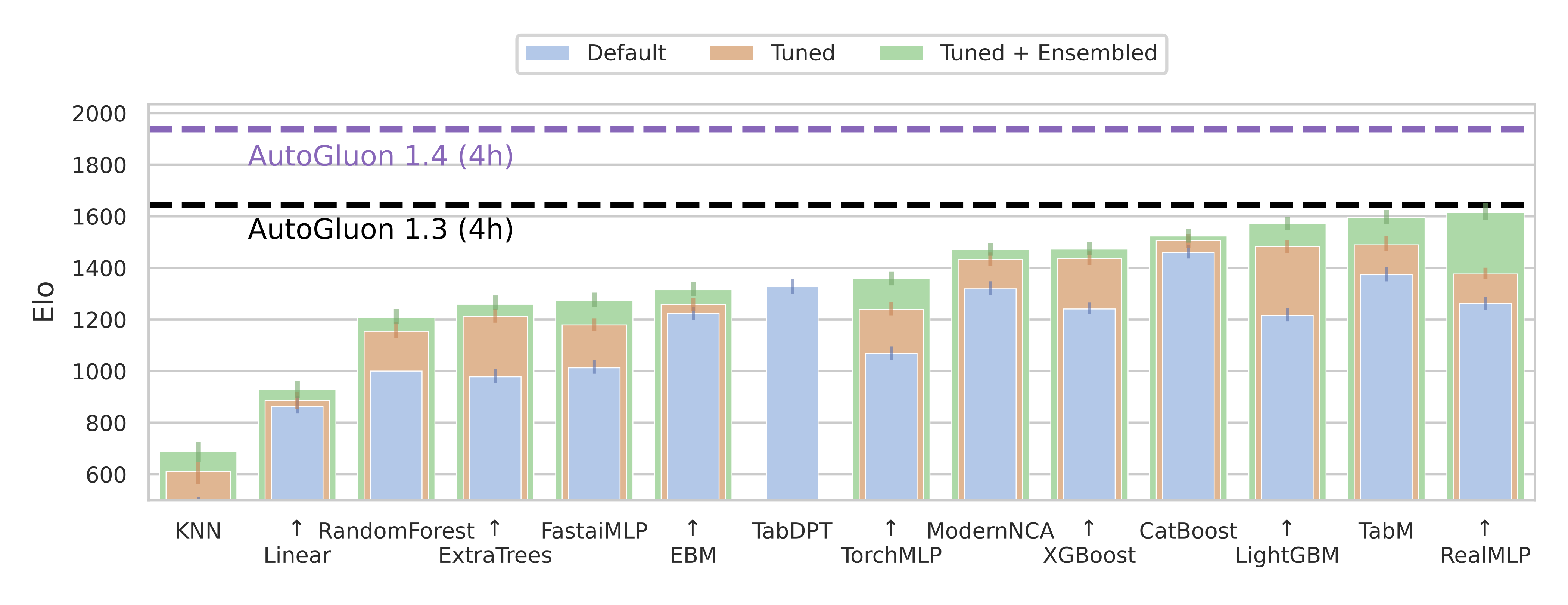
AutoGluon 1.4.0 introduces a new tabular preset, extreme_quality aka extreme.
AutoGluon’s extreme preset is the largest singular improvement to AutoGluon’s predictive performance in the history of the package, even larger than the improvement seen in AutoGluon 1.0 compared to 0.8.
This preset achieves an 88% win-rate vs Autogluon 1.3 best_quality for datasets with fewer than 10000 samples, and a 290 Elo improvement overall on TabArena (shown in the figure above).
Try it out in 3 lines of code:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label="class").fit("train.csv", presets="extreme")
predictions = predictor.predict("test.csv")
The extreme preset leverages a new model portfolio, which is an improved version of the TabArena ensemble shown in Figure 6a of the TabArena paper.
It consists of many new model families added in this release: TabPFNv2, TabICL, Mitra, TabM, as well as tree methods: CatBoost, LightGBM, XGBoost.
This preset is not only more accurate, it also requires much less training time. AutoGluon’s extreme preset in 5 minutes is able to outperform best ran for 4 hours.
In order to get the most out of the extreme preset, a CUDA compatible GPU is required, ideally with 32+ GB vRAM.
Note that inference time can be longer than best, but with a GPU it is very reasonable.
The extreme portfolio is only leveraged for datasets with at most 30000 samples. For larger datasets, we continue to use the best_quality portfolio.
The preset requires downloading foundation model weights for TabPFNv2, TabICL, and Mitra during fit. If you don’t have an internet connection,
ensure that you pre-download the weights of the models to be able to use them during fit.
This preset is considered experimental for this release, and may change without warning in a future release.
TabArena and new models: TabPFNv2, TabICL, TabM, RealMLP¶
🚨What is SOTA on tabular data, really? We are excited to introduce TabArena, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard accepting submissions
📑 carefully curated datasets (real, predictive, tabular, IID, permissive license)
📈 strong tree-based, deep learning, and foundation models
⚙️ best practices for evaluation (inner CV, outer CV, early stopping)
ℹ️ 𝐎𝐯𝐞𝐫𝐯𝐢𝐞𝐰
Leaderboard: https://tabarena.ai
Paper: https://arxiv.org/abs/2506.16791
Code: https://tabarena.ai/code
💡 𝐌𝐚𝐢𝐧 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬:
➡️ Recent deep learning models, RealMLP and TabM, have marginally overtaken boosted trees with weighted ensembling, although they have slower train+inference times. With defaults or regular tuning, CatBoost takes the #1 spot.
➡️ Foundation models TabPFNv2 and TabICL are only applicable to a subset of datasets, but perform very strongly on these. They have a large inference time and still need tuning/ensembling to get the top spot (for TabPFNv2).
➡️ The winner does NOT take it all. By using a weighted ensemble of different model types from TabArena, we can significantly outperform the current state of the art on tabular data, AutoGluon 1.3.
➡️ These insights have been directly incorporated into the AutoGluon 1.4 release with the extreme preset, dramatically advancing the state of the art!
➡️ The models TabPFNv2, TabICL, TabM, and RealMLP have been added to AutoGluon! To use them, run pip install autogluon[tabarena] and use the extreme preset.
🎯TabArena is a living benchmark. With the community, we will continually update it!
TabArena Authors: Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, Frank Hutter
AutoGluon Assistant (MLZero)¶
Multi-Agent System Powered by LLMs for End-to-end Multimodal ML Automation
We are excited to present the AutoGluon Assistant 1.0 release. Level up from v0.1: v1.0 expands beyond tabular data to robustly support any and many modalities, including image, text, tabular, audio and mixed-data pipelines. This aligns precisely with the MLZero vision of comprehensive, modality-agnostic ML automation.
AutoGluon Assistant v1.0 is now synonymous with “MLZero: A Multi-Agent System for End-to-end Machine Learning Automation” (arXiv:2505.13941), the end-to-end, zero-human-intervention AutoML agent framework for multimodal data. Built on a novel multi-agent architecture using LLMs, MLZero handles perception, memory (semantic & episodic), code generation, execution, and iterative debugging — seamlessly transforming raw multimodal inputs into high-quality ML/DL pipelines.
No-code: Users define tasks purely through natural language (“classify images of cats vs dogs with custom labels”), and MLZero delivers complete solutions with zero manual configuration or technical expertise required.
Built on proven foundations: MLZero generates code using established, high-performance ML libraries rather than reinventing the wheel, ensuring robust solutions while maintaining the flexibility to easily integrate new libraries as they emerge.
Research-grade performance: MLZero is extensively validated across 25 challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6%) and an average rank of 2.42.
Dataset |
Ours |
Codex CLI |
Codex CLI (+reasoning) |
AIDE |
DS-Agent |
AK |
|---|---|---|---|---|---|---|
Avg. Rank ↓ |
2.42 |
8.04 |
5.76 |
6.16 |
8.26 |
8.28 |
Rel. Time ↓ |
1.0 |
0.15 |
0.23 |
2.83 |
N/A |
4.82 |
Success ↑ |
92.0% |
14.7% |
69.3% |
25.3% |
13.3% |
14.7% |
Modular and extensible architecture: We separate the design and implementation of each agent and prompts for different purposes, with a centralized manager coordinating them. This makes adding or editing agents, prompts, and workflows straightforward and intuitive for future development.
We’re also excited to introduce the newly redesigned WebUI in v1.0, now with a streamlined chatbot-style interface that makes interacting with MLZero intuitive and engaging. Furthermore, we’re also bringing MCP (Model Control Protocol) integration to MLZero, enabling seamless remote orchestration of AutoML pipelines through a standardized protocol。
AutoGluon Assistant is supported on Python 3.8 - 3.11 and is available on Linux.
Installation:
pip install uv
uv pip install autogluon.assistant>=1.0
To use CLI:
mlzero -i <input_data_dir>
To use webUI:
mlzero-backend # command to start backend
mlzero-frontend # command to start frontend on 8509 (default)
To use MCP:
# server
mlzero-backend # command to start backend
bash ./src/autogluon/mcp/server/start_services.sh # This will start the service—run it in a new terminal.
# client
python ./src/autogluon/mcp/client/server.py
MLZero Authors: Haoyang Fang, Boran Han, Steven Shen, Nick Erickson, Xiyuan Zhang, Su Zhou, Anirudh Dagar, Jiani Zhang, Ali Caner Turkmen, Cuixiong Hu, Huzefa Rangwala, Ying Nian Wu, Bernie Wang, George Karypis
Mitra¶
🚀 Mitra is a new state-of-the-art tabular foundation model developed by the AutoGluon team, natively supported in AutoGluon with just three lines of code via predictor.fit(train_data, hyperparameters={"MITRA": {}}). Built on the in-context learning paradigm and pretrained exclusively on synthetic data, Mitra introduces a principled pretraining approach by carefully selecting and mixing diverse synthetic priors to promote robust generalization across a wide range of real-world tabular datasets. Mitra is incorporated into the new extreme preset.
📊 Mitra achieves state of the art performance on major benchmarks including TabRepo, TabZilla, AMLB, and TabArena, especially excelling on small tabular datasets with fewer than 5,000 samples and 100 features, for both classification and regression tasks.
🧠 Mitra supports both zero-shot and fine-tuning modes and runs seamlessly on both GPU and CPU. Its weights are fully open-sourced under the Apache-2.0 license, making it a privacy-conscious and production-ready solution for enterprises concerned about data sharing and hosting.
🔗 Learn more by reading the Mitra release blog post and on HuggingFace:
Classification model: autogluon/mitra-classifier
Regression model: autogluon/mitra-regressor
We welcome community feedback for future iterations. Give us a like on HuggingFace if you want to see more cutting-edge foundation models for structured data!
Mitra Authors: Xiyuan Zhang, Danielle Robinson, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, Bernie Wang
General¶
Add CPU utility functions for better CPU detection in restrained env such as docker and slurm cluster. @tonyhoo (#5197)
Use joblib instead of loky for cpu detection. @shchur (#5215)
Support Apple Silicon and log it in the system info. @tonyhoo (#5141)
Add load pickle from url support, fix save_str if root path. @Innixma (#5142)
Use pyarrow by default, remove fastparquet. @Innixma (#5150)
Resolve AttributeError in LinearModel when using RAPIDS cuML models. @tonyhoo (#5157)
prioritize the CUDA libraries from PyTorch wheel instead of the system/DLC. @FireballDWF (#5163)
update numpy cap, thus 2.3.0 is allowed. @FireballDWF (#5170)
Replace pkg_resources.parse_version with packaging.version.parse. @shchur (#5182)
Update pandas, scikit-learn, and scipy version caps in setup utils. @tonyhoo (#5194)
Enhance spunge_augment and munge_augment functions for model distillation. @tonyhoo (#5208)
Increase pytorch cap to 2.8 to enable 2.7. @FireballDWF (#5089)
Resolve datetime deprecation warnings. @emmanuel-ferdman (#5069)
Tabular¶
New Presets¶
Add extreme preset with meta-learned TabArena portfolio. @Innixma (#5211)
The
extremepreset is the largest singular improvement to AutoGluon’s predictive performance in the history of the package, even larger than the improvement seen in AutoGluon 1.0 compared to 0.8.For more information, refer to the highlights section above.
New Models¶
Mitra¶
TabPFNv2¶
Add TabPFNv2 Model (key:
"TABPFNV2"). @LennartPurucker, @Innixma (#5191)Install via
pip install autogluon.tabular[all,tabpfn](orpip install autogluon[tabarena])Paper: Accurate predictions on small data with a tabular foundation model
TabICL¶
Add TabICL Model (key:
"TABICL"). @LennartPurucker, @Innixma (#5193)Install via
pip install autogluon.tabular[all,tabicl](orpip install autogluon[tabarena])Paper: TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
RealMLP¶
Add RealMLP Model (key:
"REALMLP"). @dholzmueller, @Innixma, @LennartPurucker (#5190)-Install via
pip install autogluon.tabular[all,realmlp](orpip install autogluon[tabarena])Paper: Better by Default: Strong Pre-Tuned MLPs and Boosted Trees on Tabular Data
TabM¶
Add TabM Model (key:
"TABM"). @LennartPurucker, @dholzmueller, @Innixma (#5196)Install via
pip install autogluon.tabular[all,tabm](and natively inpip install autogluon)Paper: TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
Removals¶
Fixes and Improvements¶
Respect num_cpus/num_gpus in sequential_local fit. @Innixma (#5203)
Switch to loky for get_cpu_count in all places. @Innixma (#5204)
Add support for max_rows, max_features, max_classes, problem_types. @Innixma (#5181)
Fix CatBoost crashing for problem_type=”quantile” if len(quantile_levels) == 1. @shchur (#5201)
Add tabular foundational model cache from s3 to benchmark to avoid rate limit issue from HF. @tonyhoo (#5214)
Fix default loss_function for CatBoostModel with problem_type=’regression’. @shchur (#5216)
Minor enhancements and fixes. @adibiasio, @Innixma (#5158)
TimeSeries¶
Highlights¶
Major efficiency improvements to the core
TimeSeriesDataFramemethods, resulting in up to 7x lower end-to-endpredictor.fit()andpredict()time when working with large datasets (>10M rows).New tabular forecasting model
PerStepTabularthat fits a separate tabular regression model for each time step in the forecast horizon. Both fitting and inference for the model are parallelized across cores, resulting in one of the most efficient and accurate implementations of this model among open-source Python packages.
API Changes and Deprecations¶
DirectTabularandRecursiveTabularmodels: hyperparameterstabular_hyperparametersandtabular_fit_kwargsare now deprecated in favor ofmodel_nameandmodel_hyperparameters.These models now fit a single regression model from
autogluon.tabularunder the hood instead of creating an entireTabularPredictor. This results in lower disk usage and API better aligned with the rest of thetimeseriesmodule.Details and example usage
# New API: >= v1.4.0 predictor.fit( ..., hyperparameters={ "RecursiveTabular": {"model_name": "CAT", "model_hyperparameters": {"iterations": 100}} } ) # Old API: <= v1.3.1 predictor.fit( ..., hyperparameters={ "RecursiveTabular": {"tabular_hyperparameters": {"CAT": {"iterations": 100}}} } )
If you provide
tabular_hyperparameterswith a single model in v1.4.0, a warning will be logged and the parameter will be automatically converted to match the new API.If you provide
tabular_hyperparameterswith >=2 models in v1.4.0, an error will be raised since it cannot automatically be converted to the new API.Chronosmodel: Hyperparameteroptimization_strategy(deprecated in v1.3.0) has been removed in v1.4.0.
New Features¶
Add
PerStepTabularmodel that fits a separate tabular regression model for each step in the forecast horizon. @shchur (#5189, #5213)Improve heuristic for long-term forecast unrolling (
prediction_length > 64) for Chronos-Bolt. @abdulfatir (#5177)RecursiveTabularmodel now supports thelag_transformshyperparameter. @shchur (#5184)
Fixes and Improvements¶
Improve the runtime of various
TimeSeriesDataFrameoperations by replacinggroupbywith efficient alternatives based onindptr. @shchur (#5159)Refactor
DirectTabularandRecursiveTabularmodels to use a single tabular model under the hood instead of aTabularPredictor. (#5212)Reorganize
autogluon.timeseries.models.gluontsnamespace. @canerturkmen (#5104)Log the full stack trace in case of individual model failures during training. @shchur (#5178)
Deprecate the
optimization_strategyhyperparameter for the Chronos (classic) model. @shchur (#5202)Fix incompatibility with python 3.9. @prateekdesai04 (#5220)
Refactor the implementation of
RecursiveTabularandDirectTabularmodels. @shchur (#5184, #5206)Fix typos and layout issues in the documentation. @shchur (#5225)
Fix refit_full failing during ensemble prediction if quantile_levels=[]. @shchur (#5242)
Multimodal¶
Documentation and CI¶
Special Thanks¶
Lennart Purucker and David Holzmüller for helping to implement TabPFNv2, TabICL, RealMLP and TabM, along with providing improved memory estimate logic for the models.
Steven Shen for implementing the front-end web UI and MCP backend for MLZero.
Atharva Rajan Kale for helping to automate and streamline our DLC release process.
Contributors¶
Full Contributor List (ordered by # of commits):
@shchur @Innixma @tonyhoo @prateekdesai04 @FireballDWF @canerturkmen @abdulfatir @rsj123 @xiyuanzh @mwhol @daradib @emmanuel-ferdman @adibiasio @LennartPurucker @dholzmueller