How It Works¶
AutoML is usually associated with Hyperparameter Optimization (HPO) of one or multiple models. Or with the automatic selection of models based on the given problem. In fact, most AutoML frameworks do this.
AutoGluon is different because it doesn’t rely on HPO to achieve great performance[1]. It’s based on three main principles: (1) training a variety of different models, (2) using bagging when training those models, and (3) stack-ensembling those models to combine their predictive power into a “super” model. The following sections describe these concepts in more detail.
Bagging¶
Bagging (Bootstrap Aggregation) is a technique used in Machine Learning to improve the stability and accuracy of algorithms. The key idea is that combining multiple models usually leads to better performance than any single model because it reduces overfitting and adds robustness to the prediction.
In general, the bootstrap portion of bagging involves taking many random sub-samples (with replacement, i.e. the same data point can appear more than once in a sample) from the training dataset. And then training different models on the bootstrapped samples.
However, AutoGluon performs bagging in a different way by combining it with cross-validation. In addition to the benefits of bagging, cross-validation allows us to train and validate multiple models using all the training data. This also increases our confidence in the scores of the trained models. Here’s how the technique works:
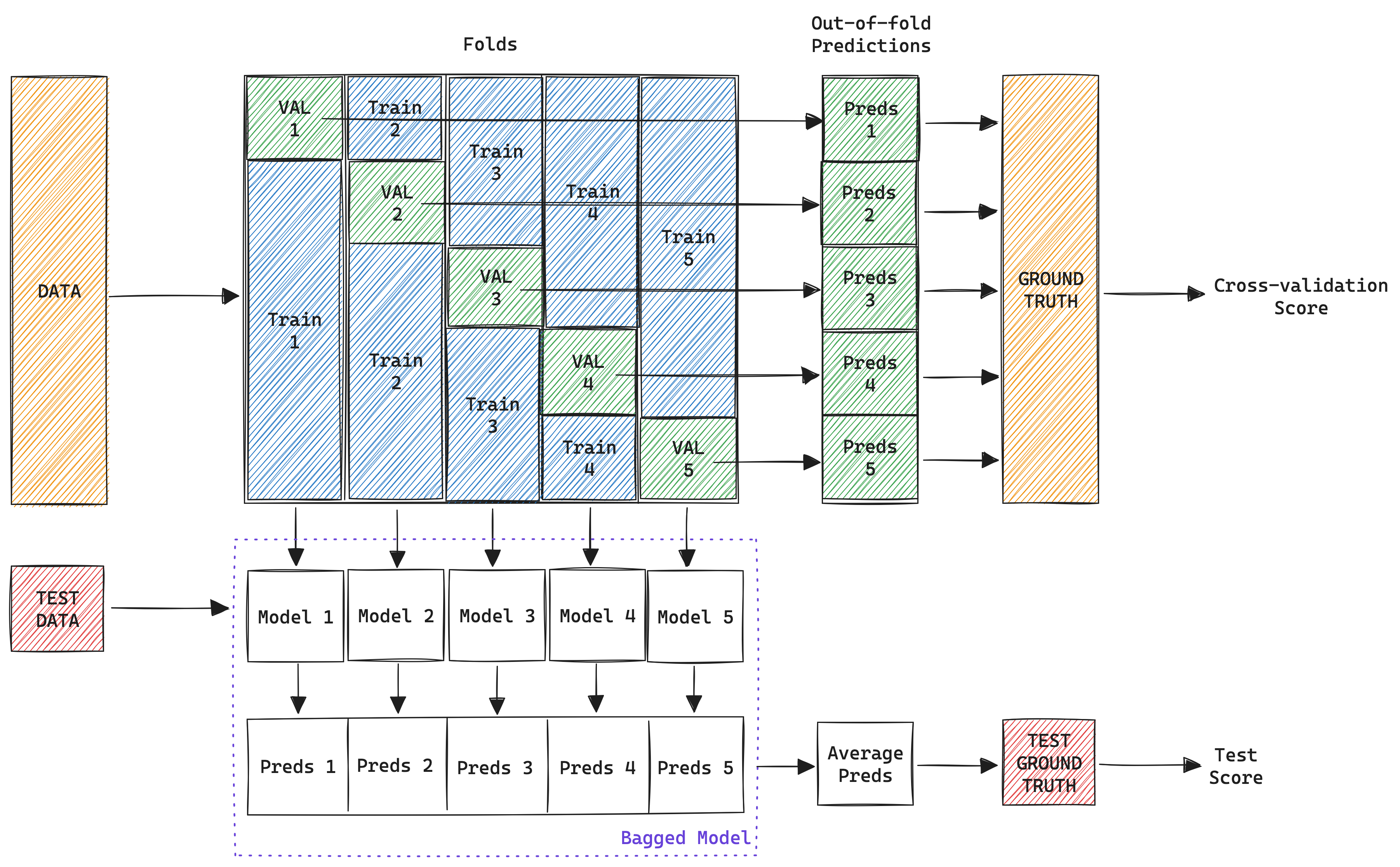
Partitioning: The training data is partitioned into K folds (or subsets of the dataset)[2].
Model Training: For each of the folds, a model is trained using all the data except the fold. This means we train K separate model instances with different portions of the data. This is known as a bagged model.
Cross-validation: Each model instance is evaluated against the hold-out fold that wasn’t used during training. We then concatenate the predictions[3] from the folds to create the out-of-fold (OOF) predictions. We calculate the final model cross-validation score by computing the evaluation metric using the OOF predictions and the target ground truth. Make sure to form a solid understanding of what out-of-fold (OOF) predictions are, as they are the most critical component to making stack ensembling work (see below).
Aggregation: At prediction time, bagging takes all these individual models and averages their predictions to generate a final answer (e.g. the class in the case of classification problems).
This same process is repeated for each of the models that AutoGluon uses. Thus, the number of models that AutoGluon trains during this process is N x K, where N is the number of models and K is the number of folds.
Stacked Ensembling¶
In the most general sense, ensembling is another technique used in Machine Learning to improve the accuracy of predictions by combining the strengths of multiple models. There are multiple ways to perform ensembling[4] and this guide is a great introduction to many of them.
AutoGluon, in particular, uses stack ensembling. At a high level, stack ensembling is a technique that leverages the predictions of models as extra features in the data. Here’s how the technique works:
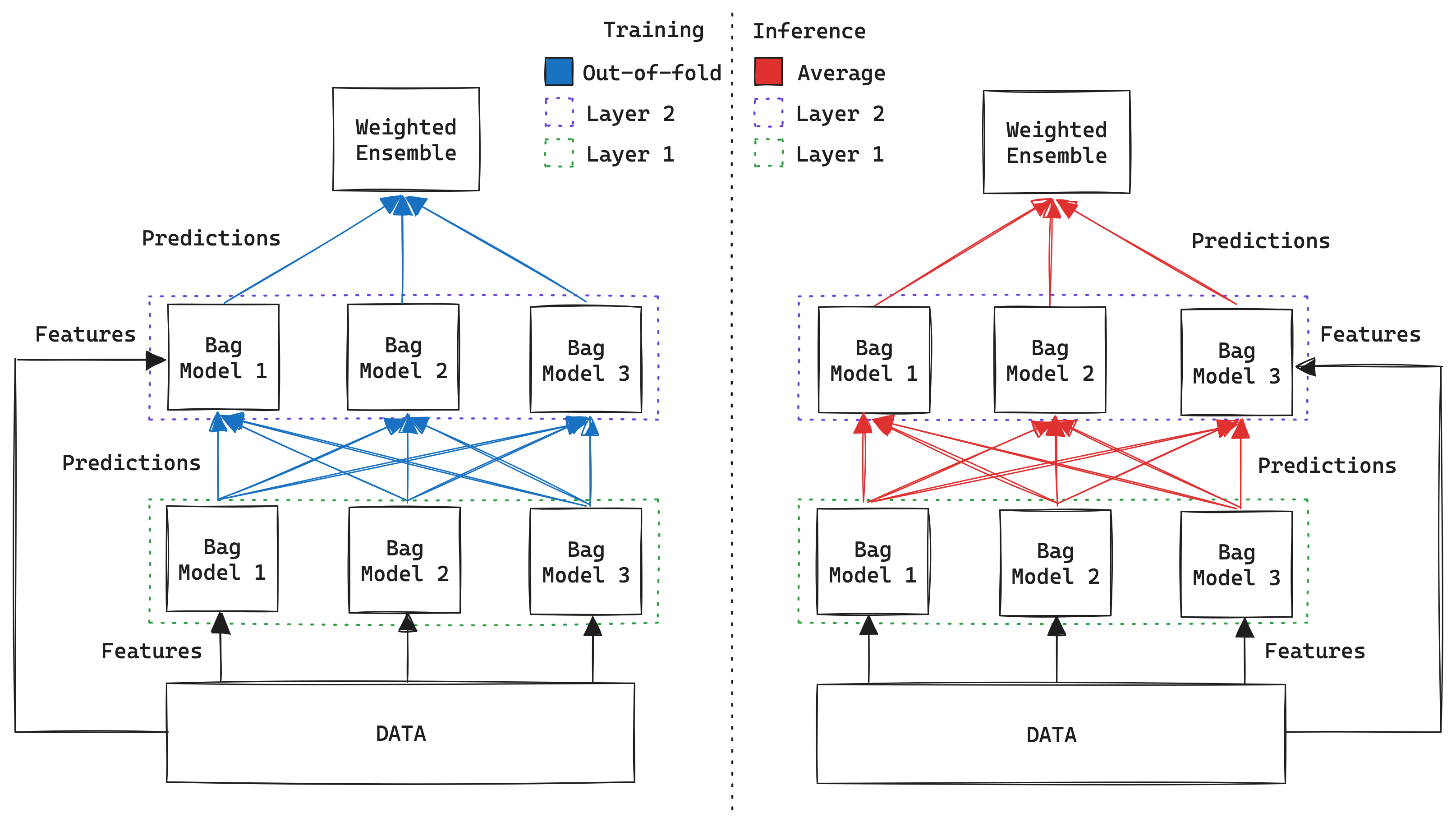
Layer(s) of Models: Stacked ensembling is like a multi-layer cake. Each layer consists of several different bagged models (see above) that use the predictions from the previous layer as inputs (features) in addition to the original features from the training data (akin to a skip connection). The first layer (also known as the base) uses only the original features from the training data.
Weighted Ensemble: The last layer consists of a single “super” model that combines the predictions from the second to last layer[5]. The job of this model, commonly known as the meta-model, is to learn how to combine the outputs from all previous models to make a final prediction. Think of this model as a leader who makes a final decision by weighting everyone else’s inputs. In fact, that is exactly what AutoGluon does: it uses a Greedy Weighted Ensemble algorithm to produce the final meta-model.
Residual Connections: Note that the structure of stacked ensembling resembles that of a Neural Network. Therefore, advanced techniques (e.g. dropout, skip connections, etc.) used for Neural Networks could also be applied here as well.
How to Train: During training time it is critical to avoid data leakage, and therefore we use the out-of-fold (OOF) predictions of each bag model instead of predicting directly on the train data with the bagged model. By using out-of-fold predictions, we ensure that each instance in the training dataset has a corresponding prediction that was generated by a model that did not train on that instance. This setup mirrors how the final ensemble model will operate on new, unseen data.
How to Infer: During inference time, we don’t need to worry about data leakage, and we simply average the predictions of all models in a bag to generate its predictions.
Considering both bagging and stacked ensembling, the final number of models that AutoGluon trains is M x N x K + 1, where:
M is the number of layers in the ensemble, including the base and excluding the last layer
N is the number of models per layer
K is the number of folds for bagging
1 is the final meta-model (weighted ensemble)
What Models To Use¶
One key part of this whole process is deciding which models to train and ensemble. Although ensembling, in general, is a very powerful technique; choosing the right models can be the difference between mediocre and excellent performance.
To answer this question, we evaluated 1,310 models on 200 distinct datasets to compare the performance of different combinations of algorithms and hyperparameter configurations. The evaluation is available in this repository.
With the results of this extensive evaluation, we chose a set of pre-defined configurations to use in AutoGluon by default[6] based on the desired performance (e.g. “best quality”, “medium quality”, etc.). These presets even define the order in which models should be trained to maximize the use of training time.