AutoGluon Time Series - Forecasting Quick Start¶
![]()

Via a simple fit() call, AutoGluon can train and tune
simple forecasting models (e.g., ARIMA, ETS, Theta),
powerful deep learning models (e.g., DeepAR, Temporal Fusion Transformer),
tree-based models (e.g., LightGBM),
an ensemble that combines predictions of other models
to produce multi-step ahead probabilistic forecasts for univariate time series data.
This tutorial demonstrates how to quickly start using AutoGluon to generate hourly forecasts for the M4 forecasting competition dataset.
Loading time series data as a TimeSeriesDataFrame¶
First, we import some required modules
import pandas as pd
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
To use autogluon.timeseries, we will only need the following two classes:
TimeSeriesDataFramestores a dataset consisting of multiple time series.TimeSeriesPredictortakes care of fitting, tuning and selecting the best forecasting models, as well as generating new forecasts.
We load a subset of the M4 hourly dataset as a pandas.DataFrame
df = pd.read_csv("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/train.csv")
df.head()
| item_id | timestamp | target | |
|---|---|---|---|
| 0 | H1 | 1750-01-01 00:00:00 | 605.0 |
| 1 | H1 | 1750-01-01 01:00:00 | 586.0 |
| 2 | H1 | 1750-01-01 02:00:00 | 586.0 |
| 3 | H1 | 1750-01-01 03:00:00 | 559.0 |
| 4 | H1 | 1750-01-01 04:00:00 | 511.0 |
AutoGluon expects time series data in long format. Each row of the dataframe contains a single observation (timestep) of a single time series represented by
unique ID of the time series (
"item_id") as int or strtimestamp of the observation (
"timestamp") as apandas.Timestampor compatible formatnumeric value of the time series (
"target")
The raw dataset should always follow this format with at least three columns for unique ID, timestamp, and target value, but the names of these columns can be arbitrary.
It is important, however, that we provide the names of the columns when constructing a TimeSeriesDataFrame that is used by AutoGluon.
AutoGluon will raise an exception if the data doesn’t match the expected format.
train_data = TimeSeriesDataFrame.from_data_frame(
df,
id_column="item_id",
timestamp_column="timestamp"
)
train_data.head()
| target | ||
|---|---|---|
| item_id | timestamp | |
| H1 | 1750-01-01 00:00:00 | 605.0 |
| 1750-01-01 01:00:00 | 586.0 | |
| 1750-01-01 02:00:00 | 586.0 | |
| 1750-01-01 03:00:00 | 559.0 | |
| 1750-01-01 04:00:00 | 511.0 |
We refer to each individual time series stored in a TimeSeriesDataFrame as an item.
For example, items might correspond to different products in demand forecasting, or to different stocks in financial datasets.
This setting is also referred to as a panel of time series.
Note that this is not the same as multivariate forecasting — AutoGluon generates forecasts for each time series individually, without modeling interactions between different items (time series).
TimeSeriesDataFrame inherits from pandas.DataFrame, so all attributes and methods of pandas.DataFrame are available in a TimeSeriesDataFrame.
It also provides other utility functions, such as loaders for different data formats (see TimeSeriesDataFrame for details).
Training time series models with TimeSeriesPredictor.fit¶
To forecast future values of the time series, we need to create a TimeSeriesPredictor object.
Models in autogluon.timeseries forecast time series multiple steps into the future.
We choose the number of these steps — the prediction length (also known as the forecast horizon) — depending on our task.
For example, our dataset contains time series measured at hourly frequency, so we set prediction_length = 48 to train models that forecast up to 48 hours into the future.
We instruct AutoGluon to save trained models in the folder ./autogluon-m4-hourly.
We also specify that AutoGluon should rank models according to mean absolute scaled error (MASE), and that data that we want to forecast is stored in the column "target" of the TimeSeriesDataFrame.
predictor = TimeSeriesPredictor(
prediction_length=48,
path="autogluon-m4-hourly",
target="target",
eval_metric="MASE",
)
predictor.fit(
train_data,
presets="medium_quality",
time_limit=600,
)
Beginning AutoGluon training... Time limit = 600s
AutoGluon will save models to '/home/ci/autogluon/docs/tutorials/timeseries/autogluon-m4-hourly'
=================== System Info ===================
AutoGluon Version: 1.5.0b20251219
Python Version: 3.12.10
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Wed Mar 12 14:53:59 UTC 2025
CPU Count: 8
Pytorch Version: 2.9.1+cu128
CUDA Version: 12.8
GPU Memory: GPU 0: 14.57/14.57 GB
Total GPU Memory: Free: 14.57 GB, Allocated: 0.00 GB, Total: 14.57 GB
GPU Count: 1
Memory Avail: 28.76 GB / 30.95 GB (92.9%)
Disk Space Avail: 204.19 GB / 255.99 GB (79.8%)
===================================================
Setting presets to: medium_quality
Fitting with arguments:
{'enable_ensemble': True,
'eval_metric': MASE,
'hyperparameters': 'light',
'known_covariates_names': [],
'num_val_windows': 1,
'prediction_length': 48,
'quantile_levels': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],
'random_seed': 123,
'refit_every_n_windows': 1,
'refit_full': False,
'skip_model_selection': False,
'target': 'target',
'time_limit': 600,
'verbosity': 2}
Inferred time series frequency: 'h'
Provided train_data has 148060 rows, 200 time series. Median time series length is 700 (min=700, max=960).
Provided data contains following columns:
target: 'target'
AutoGluon will gauge predictive performance using evaluation metric: 'MASE'
This metric's sign has been flipped to adhere to being higher_is_better. The metric score can be multiplied by -1 to get the metric value.
===================================================
Starting training. Start time is 2025-12-19 22:49:49
Models that will be trained: ['SeasonalNaive', 'RecursiveTabular', 'DirectTabular', 'ETS', 'Theta', 'Chronos2', 'TemporalFusionTransformer']
Training timeseries model SeasonalNaive. Training for up to 74.7s of the 597.7s of remaining time.
-1.2169 = Validation score (-MASE)
0.06 s = Training runtime
2.27 s = Validation (prediction) runtime
Training timeseries model RecursiveTabular. Training for up to 85.1s of the 595.4s of remaining time.
-0.9339 = Validation score (-MASE)
10.02 s = Training runtime
0.52 s = Validation (prediction) runtime
Training timeseries model DirectTabular. Training for up to 97.5s of the 584.8s of remaining time.
-1.3729 = Validation score (-MASE)
4.63 s = Training runtime
0.36 s = Validation (prediction) runtime
Training timeseries model ETS. Training for up to 116.0s of the 579.8s of remaining time.
-1.9661 = Validation score (-MASE)
0.06 s = Training runtime
25.58 s = Validation (prediction) runtime
Training timeseries model Theta. Training for up to 138.5s of the 554.1s of remaining time.
-2.1426 = Validation score (-MASE)
0.06 s = Training runtime
1.61 s = Validation (prediction) runtime
Training timeseries model Chronos2. Training for up to 184.1s of the 552.4s of remaining time.
-0.8778 = Validation score (-MASE)
3.82 s = Training runtime
0.59 s = Validation (prediction) runtime
Training timeseries model TemporalFusionTransformer. Training for up to 274.0s of the 548.0s of remaining time.
Warning: Exception caused TemporalFusionTransformer to fail during training... Skipping this model.
Traceback (most recent call last):
File "/home/ci/autogluon/timeseries/src/autogluon/timeseries/trainer/trainer.py", line 353, in _train_and_save
model.fit(
File "/home/ci/autogluon/timeseries/src/autogluon/timeseries/models/abstract/abstract_timeseries_model.py", line 529, in fit
self._fit(
File "/home/ci/autogluon/timeseries/src/autogluon/timeseries/models/multi_window/multi_window_model.py", line 141, in _fit
model.fit(
File "/home/ci/autogluon/timeseries/src/autogluon/timeseries/models/abstract/abstract_timeseries_model.py", line 529, in fit
self._fit(
File "/home/ci/autogluon/timeseries/src/autogluon/timeseries/models/gluonts/abstract.py", line 426, in _fit
self.gts_predictor = estimator.train(
^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/gluonts/torch/model/estimator.py", line 246, in train
return self.train_model(
^^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/gluonts/torch/model/estimator.py", line 209, in train_model
trainer.fit(
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/trainer/trainer.py", line 560, in fit
call._call_and_handle_interrupt(
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/trainer/call.py", line 49, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/trainer/trainer.py", line 598, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/trainer/trainer.py", line 987, in _run
self.strategy.setup(self)
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/strategies/strategy.py", line 155, in setup
self.model_to_device()
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/pytorch/strategies/single_device.py", line 79, in model_to_device
self.model.to(self.root_device)
File "/home/ci/opt/venv/lib/python3.12/site-packages/lightning/fabric/utilities/device_dtype_mixin.py", line 55, in to
return super().to(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1371, in to
return self._apply(convert)
^^^^^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 930, in _apply
module._apply(fn)
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 930, in _apply
module._apply(fn)
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 930, in _apply
module._apply(fn)
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/rnn.py", line 291, in _apply
self._init_flat_weights()
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/rnn.py", line 215, in _init_flat_weights
self.flatten_parameters()
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/nn/modules/rnn.py", line 247, in flatten_parameters
or not torch.backends.cudnn.is_acceptable(fw)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/backends/cudnn/__init__.py", line 120, in is_acceptable
if not _init():
^^^^^^^
File "/home/ci/opt/venv/lib/python3.12/site-packages/torch/backends/cudnn/__init__.py", line 74, in _init
raise RuntimeError(
RuntimeError: cuDNN version incompatibility: PyTorch was compiled against (9, 8, 0) but found runtime version (9, 7, 1). PyTorch already comes bundled with cuDNN. One option to resolving this error is to ensure PyTorch can find the bundled cuDNN. one possibility is that there is a conflicting cuDNN in LD_LIBRARY_PATH.
Fitting 1 ensemble(s), in 1 layers.
Training ensemble model WeightedEnsemble. Training for up to 547.1s.
Ensemble weights: {'Chronos2': 0.62, 'DirectTabular': 0.03, 'ETS': 0.01, 'RecursiveTabular': 0.32, 'SeasonalNaive': 0.01, 'Theta': 0.01}
-0.8356 = Validation score (-MASE)
0.79 s = Training runtime
30.95 s = Validation (prediction) runtime
Training complete. Models trained: ['SeasonalNaive', 'RecursiveTabular', 'DirectTabular', 'ETS', 'Theta', 'Chronos2', 'WeightedEnsemble']
Total runtime: 51.99 s
Best model: WeightedEnsemble
Best model score: -0.8356
<autogluon.timeseries.predictor.TimeSeriesPredictor at 0x7f1c008e5ee0>
Here we used the "medium_quality" presets and limited the training time to 10 minutes (600 seconds).
The presets define which models AutoGluon will try to fit.
For medium_quality presets, these are
simple baselines (Naive, SeasonalNaive),
statistical models (ETS, Theta),
tree-based models based on LightGBM (RecursiveTabular, DirectTabular),
a deep learning model TemporalFusionTransformer,
and a weighted ensemble combining these.
Other available presets for TimeSeriesPredictor are "fast_training", "high_quality" and "best_quality".
Higher quality presets will usually produce more accurate forecasts but take longer to train.
Inside fit(), AutoGluon will train as many models as possible within the given time limit.
Trained models are then ranked based on their performance on an internal validation set.
By default, this validation set is constructed by holding out the last prediction_length timesteps of each time series in train_data.
Generating forecasts with TimeSeriesPredictor.predict¶
We can now use the fitted TimeSeriesPredictor to forecast the future time series values.
By default, AutoGluon will make forecasts using the model that had the best score on the internal validation set.
The forecast always includes predictions for the next prediction_length timesteps, starting from the end of each time series in train_data.
predictions = predictor.predict(train_data)
predictions.head()
Model not specified in predict, will default to the model with the best validation score: WeightedEnsemble
| mean | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| item_id | timestamp | ||||||||||
| H1 | 1750-01-30 04:00:00 | 624.792403 | 607.437237 | 613.349341 | 617.137737 | 620.966310 | 624.792403 | 628.720104 | 632.994113 | 637.589308 | 644.310311 |
| 1750-01-30 05:00:00 | 561.789597 | 540.126119 | 548.054324 | 553.322302 | 557.765235 | 561.789597 | 565.999261 | 570.860546 | 576.200349 | 583.976258 | |
| 1750-01-30 06:00:00 | 520.179527 | 494.338108 | 503.661816 | 509.937924 | 515.203537 | 520.179527 | 525.340077 | 530.666613 | 537.312951 | 546.119995 | |
| 1750-01-30 07:00:00 | 488.432027 | 460.632039 | 470.066303 | 477.086859 | 482.734525 | 488.432027 | 494.201282 | 500.364586 | 507.383185 | 516.589395 | |
| 1750-01-30 08:00:00 | 466.483634 | 435.533881 | 445.805793 | 453.529231 | 459.882070 | 466.483634 | 473.190788 | 480.262978 | 488.032776 | 497.725799 |
AutoGluon produces a probabilistic forecast: in addition to predicting the mean (expected value) of the time series in the future, models also provide the quantiles of the forecast distribution.
The quantile forecasts give us an idea about the range of possible outcomes.
For example, if the "0.1" quantile is equal to 500.0, it means that the model predicts a 10% chance that the target value will be below 500.0.
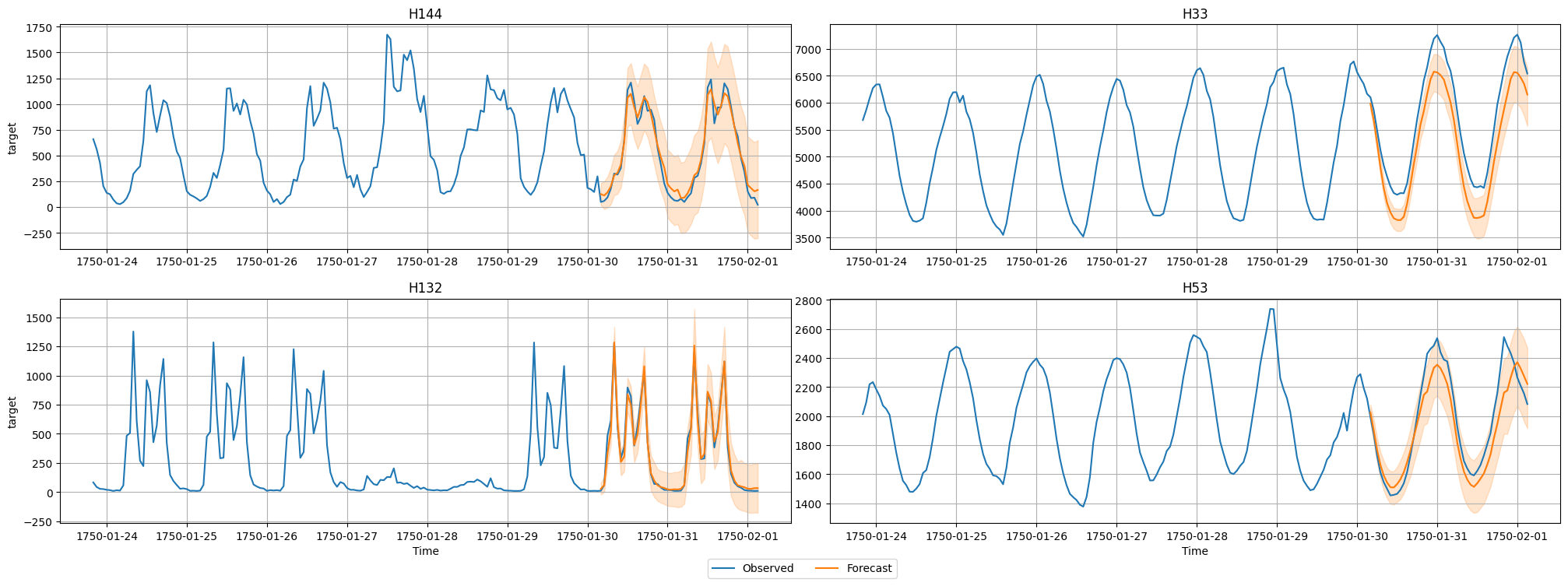
We will now visualize the forecast and the actually observed values for one of the time series in the dataset. We plot the mean forecast, as well as the 10% and 90% quantiles to show the range of potential outcomes.
import matplotlib.pyplot as plt
# TimeSeriesDataFrame can also be loaded directly from a file
test_data = TimeSeriesDataFrame.from_path("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/test.csv")
# Plot 4 randomly chosen time series and the respective forecasts
predictor.plot(test_data, predictions, quantile_levels=[0.1, 0.9], max_history_length=200, max_num_item_ids=4);
Loaded data from: https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/test.csv | Columns = 3 / 3 | Rows = 157660 -> 157660
Evaluating the performance of different models¶
We can view the performance of each model AutoGluon has trained via the leaderboard() method.
We provide the test data set to the leaderboard function to see how well our fitted models are doing on the unseen test data.
The leaderboard also includes the validation scores computed on the internal validation dataset.
Note the test data includes both the forecast horizon (last prediction_length values of each time series) as well as the historical data (all except the last prediction_last values).
In AutoGluon leaderboards, higher scores always correspond to better predictive performance.
Therefore our MASE scores are multiplied by -1, such that higher “negative MASE”s correspond to more accurate forecasts.
# The test score is computed using the last
# prediction_length=48 timesteps of each time series in test_data
predictor.leaderboard(test_data)
Additional data provided, testing on additional data. Resulting leaderboard will be sorted according to test score (`score_test`).
| model | score_test | score_val | pred_time_test | pred_time_val | fit_time_marginal | fit_order | |
|---|---|---|---|---|---|---|---|
| 0 | WeightedEnsemble | -0.734876 | -0.835553 | 34.945320 | 30.946521 | 0.794332 | 7 |
| 1 | Chronos2 | -0.765236 | -0.877750 | 0.571086 | 0.589838 | 3.819334 | 6 |
| 2 | RecursiveTabular | -0.862797 | -0.933874 | 0.565285 | 0.517951 | 10.023332 | 2 |
| 3 | SeasonalNaive | -1.022854 | -1.216909 | 2.633806 | 2.270832 | 0.063278 | 1 |
| 4 | DirectTabular | -1.648202 | -1.372871 | 0.439131 | 0.359798 | 4.632590 | 3 |
| 5 | ETS | -1.806136 | -1.966098 | 28.863584 | 25.581664 | 0.055819 | 4 |
| 6 | Theta | -1.905367 | -2.142551 | 1.860885 | 1.613884 | 0.055881 | 5 |
Summary¶
We used autogluon.timeseries to make probabilistic multi-step forecasts on the M4 Hourly dataset.
Check out Forecasting Time Series - In Depth to learn about the advanced capabilities of AutoGluon for time series forecasting.