What’s New¶
Here you can find the release notes for current and past releases of AutoGluon.
v1.5.0
Version 1.5.0
We are happy to announce the AutoGluon 1.5.0 release!
AutoGluon 1.5.0 introduces new features and major improvements to both tabular and time series modules.
This release contains 131 commits from 17 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/1.4.0…1.5.0
Join the community: 

This release supports Python versions 3.10, 3.11, 3.12 and 3.13. Support for Python 3.13 is currently experimental, and some features might not be available when running Python 3.13 on Windows. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.5.0.
Spotlight
Chronos-2
AutoGluon v1.5 adds support for Chronos-2, our latest generation of foundation models for time series forecasting. Chronos-2 natively handles all types of dynamic covariates, and performs cross-learning from items in the batch. It produces multi-step quantile forecasts and is designed for strong out-of-the-box performance on new datasets.
Chronos-2 achieves state-of-the-art zero-shot accuracy among public models on major benchmarks such as fev-bench and GIFT-Eval, making it a strong default choice when little or no task-specific training data is available.
In AutoGluon, Chronos-2 can be used in zero-shot mode or fine-tuned on custom data. Both LoRA fine-tuning and full fine-tuning are supported. Chronos-2 integrates into the standard TimeSeriesPredictor workflow, making it easy to backtest, compare against classical and deep learning models, and combine with other models in ensembles.
from autogluon.timeseries import TimeSeriesPredictor
predictor = TimeSeriesPredictor(...)
predictor.fit(train_data, presets="chronos2") # zero-shot mode
More details on zero-shot usage, fine-tuning and ensembling are available in the updated tutorial.
AutoGluon Tabular
AutoGluon 1.5 Extreme sets a new state-of-the-art on TabArena, with a 60 Elo improvement over AutoGluon 1.4 Extreme. On average, AutoGluon 1.5 Extreme trains in half the time, has 50% faster inference speed, a 70% win-rate, and 2.8% less relative error compared to AutoGluon 1.4 Extreme. Whereas 1.4 used a mixed portfolio that changed depending on data size, 1.5 uses a single fixed portfolio for all datasets.
Notable Improvements:
Added TabDPT model, a tabular foundation model pre-trained exclusively on real data.
Added TabPrep-LightGBM, a LightGBM model with custom preprocessing logic including target mean encoding and feature crossing.
Added early stopping logic for the portfolio which stops training early for small datasets to mitigate overfitting and reduce training time.
AutoGluon 1.5 Extreme uses exclusively open and permissively licensed models, making it suitable for production and commercial use-cases.
To use AutoGluon 1.5 Extreme, you will need a GPU, ideally with at least 20 GB of VRAM to ensure stability. Performance gains are primarily on datasets with up to 100k training samples.
# pip install autogluon.tabular[tabarena] # <-- Required for TabDPT, TabICL, TabPFN, and Mitra
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(...).fit(train_data, presets="extreme") # GPU required
| TabArena All (51 datasets) | ||||
|---|---|---|---|---|
| Model | Elo [⬆️] | Improvability (%) [⬇️] | Train Time (s/1K) [⬇️] | Predict Time (s/1K) [⬇️] |
| AutoGluon 1.5 (extreme, 4h) | 1736 | 3.498 | 289.07 | 4.031 |
| AutoGluon 1.4 (extreme, 4h) | 1675 | 6.381 | 582.21 | 6.116 |
| AutoGluon 1.4 (best, 4h) | 1536 | 9.308 | 1735.72 | 2.559 |
| Pareto Frontier (Elo) | Pareto Frontier (Improvability) |
|---|---|
|
|
|
New Model: RealTabPFN-2.5
Tech Report: TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
AutoGluon 1.5 adds support for fitting the RealTabPFN-2.5 model, the current strongest individual model on TabArena. Unlike TabPFN-2 which has a permissive license, RealTabPFN-2.5 comes with a non-commercial license and requires the user to authenticate with HuggingFace and accept a terms of use agreement before being able to download the weights. The user will be automatically prompted to perform these steps during AutoGluon’s fit call if RealTabPFN-2.5 is specified, and the model will be skipped until the weights have been downloaded by the user. RealTabPFN-2.5 is not currently used in any AutoGluon preset, and must be manually specified.
All TabPFN user telemetry is disabled when used with AutoGluon.
To use RealTabPFN-2.5 (non-commercial use only):
# pip install autogluon.tabular[all,tabpfn]
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(...).fit(
train_data,
hyperparameters={"REALTABPFN-V2.5": [{}]},
) # GPU required, non-commercial
To use RealTabPFN-2 (permissive license):
# pip install autogluon.tabular[all,tabpfn]
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(...).fit(train_data, hyperparameters={"REALTABPFN-V2": [{}]}) # GPU required
For users who previously were using "TABPFNV2", we strongly recommend switching to "REALTABPFN-V2" to avoid breaking changes in the latest TabPFN releases.
New Model: TabDPT
Paper: TabDPT: Scaling Tabular Foundation Models on Real Data
To use TabDPT (permissive license):
# pip install autogluon.tabular[all,tabdpt]
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(...).fit(train_data, hyperparameters={"TABDPT": [{}]}) # GPU recommended
New Model: TabPrep-LightGBM
TabPrep-LightGBM is an experimental model that uses a custom data preprocessing pipeline to enhance the performance of LightGBM. It represents a working snapshot of an in-progress research effort. Further details will be shared as part of an upcoming paper.
TabPrep-LightGBM achieves a new state-of-the-art for model performance on TabArena’s 15 largest datasets (10k - 100k training samples), exceeding RealTabPFN-2.5 by 100 Elo while fitting 3x faster using just 8 CPU cores. TabPrep-LightGBM is also incorporated into the AutoGluon 1.5 extreme preset.
TabArena Medium (10k - 100k samples, 15 datasets)
Model |
Elo [⬆️] |
Imp (%) [⬇️] |
Train Time (s/1K) [⬇️] |
Predict Time (s/1K) [⬇️] |
|---|---|---|---|---|
AutoGluon 1.5 (extreme, 4h) |
1965 |
1.876 |
191.18 |
2.207 |
AutoGluon 1.4 (extreme, 4h) |
1813 |
3.016 |
289.53 |
3.187 |
AutoGluon 1.4 (best, 4h) |
1794 |
3.122 |
432.35 |
4.085 |
TabPrep-LightGBM (tuned + ensembled) |
1787 |
3.573 |
256.12 |
2.281 |
RealTabPFN-v2.5 (tuned + ensembled) |
1680 |
5.818 |
735.58 |
11.736 |
RealMLP (tuned + ensembled) |
1649 |
6.102 |
1719.82 |
1.675 |
ModernNCA (tuned + ensembled) |
1636 |
6.189 |
2526.28 |
6.013 |
CatBoost (tuned + ensembled) |
1616 |
6.011 |
777.59 |
0.25 |
LightGBM (tuned + ensembled) |
1598 |
7.77 |
131.56 |
2.639 |
To use TabPrep-LightGBM, we recommend trying the presets it is used in: "extreme", "best_v150", "high_v150". Fitting TabPrep-LightGBM outside of the use of presets is currently complicated.
General
Dependencies
Update torch to
>=2.6,<2.10@FANGAreNotGnu @shchur (#5270) (#5425)Update ray to
>=2.43.0,<2.53@shchur @prateekdesai04 (#5442) (#5312)Update lightning to
>=2.5.1,<2.6@canerturkmen (#5432)Update scikit-learn-intelex to
2025.0,<2025.10@Innixma (#5434)Add experimental support for Python 3.13 @shchur @shou10152208 (#5073) (#5423)
Fixes and Improvements
Minor typing fixes. @canerturkmen (#5292)
Fix conda install instructions for ray version. @Innixma (#5323)
Remove LICENSE and NOTICE files from common. @prateekdesai04 (#5396)
Fix upload python package. @prateekdesai04 (#5397)
Change build order. @prateekdesai04 (#5398)
Decouple and enable module-wise installation. @prateekdesai04 (#5399)
Fix get_smallest_valid_dtype_int for negative values. @Innixma (#5421)
Tabular
AutoGluon-Tabular v1.5 introduces several improvements focused on accuracy, robustness, and usability. The release adds new foundation models, updates the feature preprocessing pipeline, and improves GPU stability and memory estimation. New model portfolios are provided for both CPU and GPU workloads.
Highlights
New models: RealTabPFN-2, RealTabPFN-2.5, TabDPT, TabPrep-LightGBM, and EBM are now available in AutoGluon-Tabular.
Updated preprocessing pipeline with more consistent feature handling across models.
Improved GPU stability and more reliable memory estimation during training.
New CPU and GPU portfolios tuned for better performance across a wide range of datasets:
"extreme", "best_v150", "high_v150".Stronger benchmark results: with the new presets, AutoGluon-Tabular v1.5 Extreme achieves a 70% win rate over AutoGluon v1.4 Extreme on the 51 TabArena datasets, with a 2.8% reduction in mean relative error.
New Features
New preprocessors for tabular data. @atschalz @Innixma (#5441)
New model: Explainable Boosting Machine. @paulbkoch (#4480)
Fixes and Improvements
Fix bug if pred is inf and weight is 0 in weighted ensemble. @Innixma (#5317)
Default TabularPredictor.delete_models dry_run=False. @Innixma (#5260)
Support different random seeds per fold. @LennartPurucker (#5267)
Changing the default output dir’s base path. @LennartPurucker (#5285)
Ensure compatibility of flash attention unpad_input. @xiyuanzh (#5298)
Refactor of validation technique selection. @LennartPurucker (#4585)
MakeOneFeatureGenerator pass check_is_fitted test. @betatim (#5386)
Enable CPU loading of models trained on GPU @Innixma (#5403) (#5434)
Remove unused variable val_improve_epoch in TabularNeuralNetTorchModel. @celestinoxp (#5466)
Fix memory estimation for RF/XT in parallel mode. @celestinoxp (#5467)
Pass label cleaner to model for semantic encodings. @LennartPurucker (#5482)
Fix time_epoch_average calculation in TabularNeuralNetTorch. @celestinoxp (#5484)
GPU optimization, scheduling for parallel_local fitting strategy. @prateekdesai04 (#5388)
Fix XGBoost crashing on eval metric name in HPs. @LennartPurucker (#5493)
TimeSeries
AutoGluon v1.5 introduces substantial improvements to the time series module, with clear gains in both accuracy and usability. Across our benchmarks, v1.5 achieves up to an 80% win rate compared to v1.4. The release adds new models, more flexible ensembling options, and numerous bug fixes and quality-of-life improvements.
Highlights
Chronos-2 is now available in AutoGluon, with support for zero-shot inference as well as full and LoRA fine-tuning (tutorial).
Customizable ensembling logic: Adds item-level ensembling, multi-layer stack ensembles, and other advanced forecast combination methods (documentation).
New presets leading to major gains in accuracy & efficiency. AG-TS v1.5 achieves up to 80% win rate over v1.4 on point and probabilistic forecasting tasks. With just a 10 minute time limit, v1.5 outperforms v1.4 running for 2 hours.
Usability improvements: Automatically determine an appropriate backtesting configuration by setting
num_val_windows="auto"andrefit_every_n_windows="auto". Easily access the validation predictions and perform rolling evaluation on custom data with new predictor methodsbacktest_predictionsandbacktest_targets.
New Features
Add multi-layer stack ensembling support @canerturkmen (#5459) (#5472) (#5463) (#5456) (#5436) (#5422) (#5391)
Add new advanced ensembling methods @canerturkmen @shchur (#5465) (#5420) (#5401) (#5389) (#5376)
Add Chronos-2 model. @abdulfatir @canerturkmen (#5427) (#5447) (#5448) (#5449) (#5454) (#5455) (#5450) (#5458) (#5492) (#5495) (#5487) (#5486)
Update Chronos-2 tutorial. @abdulfatir (#5481)
Add Toto model. @canerturkmen (#5321) (#5390) (#5475)
Fine-tune Chronos-Bolt on user-provided
quantile_levels. @shchur (#5315)Add backtesting methods for the TimeSeriesPredictor. @shchur (#5356)
API Changes and Deprecations
Remove outdated presets related to the original Chronos model:
chronos,chronos_large,chronos_base,chronos_small,chronos_mini,chronos_tiny,chronos_ensemble. We recommend to use the new presetschronos2,chronos2_smallandchronos2_ensembleinstead.
Fixes and Improvements
Replace
infvalues withNaNinside_check_and_prepare_data_frame. @shchur (#5240)Add model registry and fix presets typing. @canerturkmen (#5100)
Move ITEMID and TIMESTAMP to dataset namespace. @canerturkmen (#5363)
Replace Chronos code with a dependency on
chronos-forecasting@canerturkmen (#5380) (#5383)Avoid errors if date_feature clashes with known_covariates. @shchur (#5414)
Make
rayan optional dependency forautogluon.timeseries. @shchur (#5430)Minor fixes and improvements @shchur @abdulfatir @canerturkmen (#5489) (#5452) (#5444) (#5416) (#5413) (#5410) (#5406)
Code Quality
Refactor trainable model set build logic. @canerturkmen (#5297)
Typing improvements to multiwindow model. @canerturkmen (#5308)
Move prediction cache out of trainer. @canerturkmen (#5313)
Refactor trainer methods with ensemble logic. @canerturkmen (#5375)
Use builtin generics for typing, remove types in internal docstrings. @canerturkmen (#5300)
Reorganize ensembles, add base class for array-based ensemble learning. @canerturkmen (#5332)
Separate ensemble training logic from trainer. @canerturkmen (#5384)
Clean up typing and documentation for Chronos. @canerturkmen (#5392)
Add timer utility, fix time limit in ensemble regressors, clean up tests. @canerturkmen (#5393)
upgrade type annotations to Python3.10. @canerturkmen (#5431)
Multimodal
Fixes and Improvements
Bug Fix and Update AutoMM Tutorials. @FANGAreNotGnu (#5167)
Fix Focal Loss. @FANGAreNotGnu (#5496)
Fix false positive document detection for images with incidental text. @FANGAreNotGnu (#5469)
Documentation and CI
[Test] Fix CI + Upgrade Ray. @prateekdesai04 (#5306)
Fix notebook build failures. @prateekdesai04 (#5348)
ci: scope down GitHub Token permissions. @AdnaneKhan (#5351)
[CI] Fix docker build. @prateekdesai04 (#5402)
remove ROADMAP.md. @canerturkmen (#5405)
[docs] Add citations for Chronos-2 and multi-layer stacking for TS. @shchur (#5412)
Revert “Fix permissions for platform_tests action”. @shchur (#5419)
Contributors
Full Contributor List (ordered by # of commits):
@shchur @canerturkmen @Innixma @prateekdesai04 @abdulfatir @LennartPurucker @celestinoxp @FANGAreNotGnu @xiyuanzh @nathanaelbosch @betatim @AdnaneKhan @paulbkoch @shou10152208 @ryuichi-ichinose @atschalz @colesussmeier
New Contributors
@AdnaneKhan made their first contribution in (#5351)
@paulbkoch made their first contribution in (#4480)
@shou10152208 made their first contribution in (#5073)
@ryuichi-ichinose made their first contribution in (#5458)
@colesussmeier made their first contribution in (#5452)
v1.4.0
Version 1.4.0
We are happy to announce the AutoGluon 1.4.0 release!
AutoGluon 1.4.0 introduces massive new features and improvements to both tabular and time series modules. In particular, we introduce the extreme preset to TabularPredictor, which sets a new state of the art for predictive performance by a massive margin on datasets with fewer than 30000 samples. We have also added 5 new tabular model families in this release: RealMLP, TabM, TabPFNv2, TabICL, and Mitra. We also release MLZero 1.0, aka AutoGluon-Assistant, an end-to-end automated data science agent that brings AutoGluon from 3 lines of code to 0. For more details, refer to the highlights section below.
This release contains 69 commits from 18 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/1.3.1…1.4.0
Join the community:
This release supports Python versions 3.9, 3.10, 3.11, and 3.12. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.4.0.
Spotlight
AutoGluon Tabular Extreme Preset
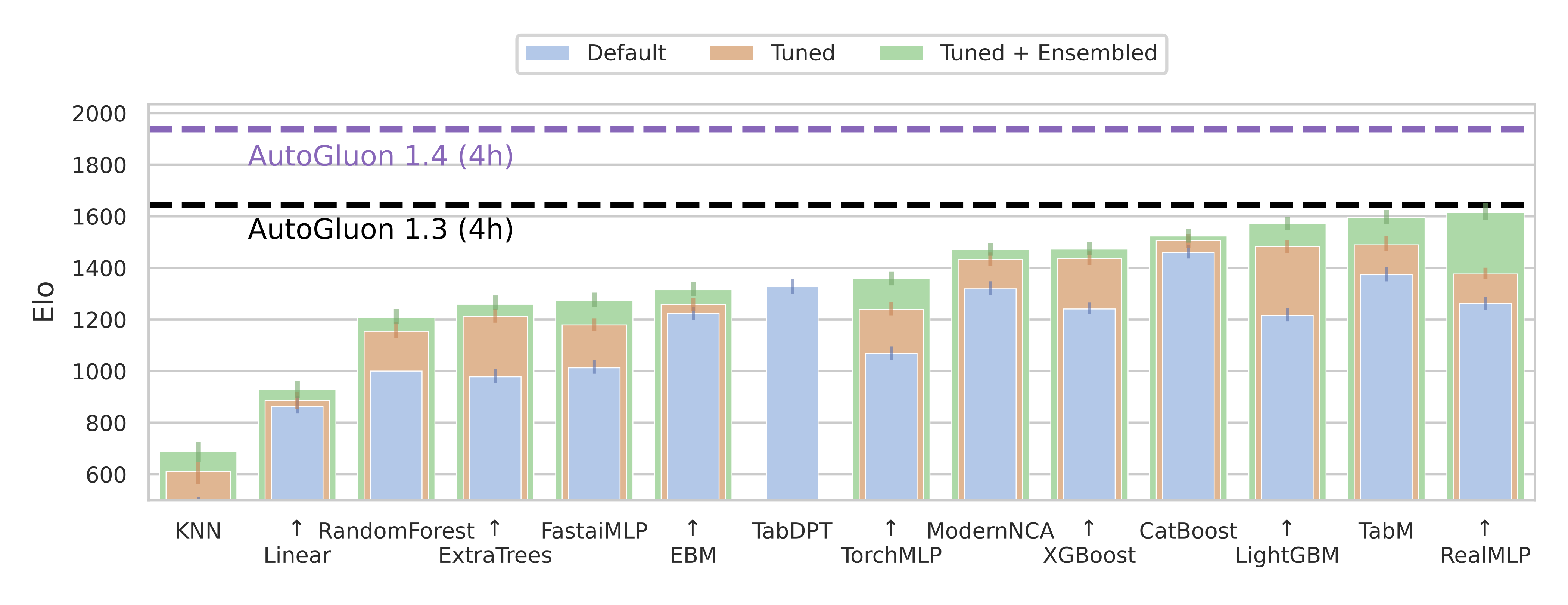
AutoGluon 1.4.0 introduces a new tabular preset, extreme_quality aka extreme.
AutoGluon’s extreme preset is the largest singular improvement to AutoGluon’s predictive performance in the history of the package, even larger than the improvement seen in AutoGluon 1.0 compared to 0.8.
This preset achieves an 88% win-rate vs Autogluon 1.3 best_quality for datasets with fewer than 10000 samples, and a 290 Elo improvement overall on TabArena (shown in the figure above).
Try it out in 3 lines of code:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label="class").fit("train.csv", presets="extreme")
predictions = predictor.predict("test.csv")
The extreme preset leverages a new model portfolio, which is an improved version of the TabArena ensemble shown in Figure 6a of the TabArena paper.
It consists of many new model families added in this release: TabPFNv2, TabICL, Mitra, TabM, as well as tree methods: CatBoost, LightGBM, XGBoost.
This preset is not only more accurate, it also requires much less training time. AutoGluon’s extreme preset in 5 minutes is able to outperform best ran for 4 hours.
In order to get the most out of the extreme preset, a CUDA compatible GPU is required, ideally with 32+ GB vRAM.
Note that inference time can be longer than best, but with a GPU it is very reasonable.
The extreme portfolio is only leveraged for datasets with at most 30000 samples. For larger datasets, we continue to use the best_quality portfolio.
The preset requires downloading foundation model weights for TabPFNv2, TabICL, and Mitra during fit. If you don’t have an internet connection,
ensure that you pre-download the weights of the models to be able to use them during fit.
This preset is considered experimental for this release, and may change without warning in a future release.
TabArena and new models: TabPFNv2, TabICL, TabM, RealMLP
🚨What is SOTA on tabular data, really? We are excited to introduce TabArena, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard accepting submissions
📑 carefully curated datasets (real, predictive, tabular, IID, permissive license)
📈 strong tree-based, deep learning, and foundation models
⚙️ best practices for evaluation (inner CV, outer CV, early stopping)
ℹ️ 𝐎𝐯𝐞𝐫𝐯𝐢𝐞𝐰
Leaderboard: https://tabarena.ai
Paper: https://arxiv.org/abs/2506.16791
Code: https://tabarena.ai/code
💡 𝐌𝐚𝐢𝐧 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬:
➡️ Recent deep learning models, RealMLP and TabM, have marginally overtaken boosted trees with weighted ensembling, although they have slower train+inference times. With defaults or regular tuning, CatBoost takes the #1 spot.
➡️ Foundation models TabPFNv2 and TabICL are only applicable to a subset of datasets, but perform very strongly on these. They have a large inference time and still need tuning/ensembling to get the top spot (for TabPFNv2).
➡️ The winner does NOT take it all. By using a weighted ensemble of different model types from TabArena, we can significantly outperform the current state of the art on tabular data, AutoGluon 1.3.
➡️ These insights have been directly incorporated into the AutoGluon 1.4 release with the extreme preset, dramatically advancing the state of the art!
➡️ The models TabPFNv2, TabICL, TabM, and RealMLP have been added to AutoGluon! To use them, run pip install autogluon[tabarena] and use the extreme preset.
🎯TabArena is a living benchmark. With the community, we will continually update it!
TabArena Authors: Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, Frank Hutter
AutoGluon Assistant (MLZero)
Multi-Agent System Powered by LLMs for End-to-end Multimodal ML Automation
We are excited to present the AutoGluon Assistant 1.0 release. Level up from v0.1: v1.0 expands beyond tabular data to robustly support any and many modalities, including image, text, tabular, audio and mixed-data pipelines. This aligns precisely with the MLZero vision of comprehensive, modality-agnostic ML automation.
AutoGluon Assistant v1.0 is now synonymous with “MLZero: A Multi-Agent System for End-to-end Machine Learning Automation” (arXiv:2505.13941), the end-to-end, zero-human-intervention AutoML agent framework for multimodal data. Built on a novel multi-agent architecture using LLMs, MLZero handles perception, memory (semantic & episodic), code generation, execution, and iterative debugging — seamlessly transforming raw multimodal inputs into high-quality ML/DL pipelines.
No-code: Users define tasks purely through natural language (“classify images of cats vs dogs with custom labels”), and MLZero delivers complete solutions with zero manual configuration or technical expertise required.
Built on proven foundations: MLZero generates code using established, high-performance ML libraries rather than reinventing the wheel, ensuring robust solutions while maintaining the flexibility to easily integrate new libraries as they emerge.
Research-grade performance: MLZero is extensively validated across 25 challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6%) and an average rank of 2.42.
Dataset |
Ours |
Codex CLI |
Codex CLI (+reasoning) |
AIDE |
DS-Agent |
AK |
|---|---|---|---|---|---|---|
Avg. Rank ↓ |
2.42 |
8.04 |
5.76 |
6.16 |
8.26 |
8.28 |
Rel. Time ↓ |
1.0 |
0.15 |
0.23 |
2.83 |
N/A |
4.82 |
Success ↑ |
92.0% |
14.7% |
69.3% |
25.3% |
13.3% |
14.7% |
Modular and extensible architecture: We separate the design and implementation of each agent and prompts for different purposes, with a centralized manager coordinating them. This makes adding or editing agents, prompts, and workflows straightforward and intuitive for future development.
We’re also excited to introduce the newly redesigned WebUI in v1.0, now with a streamlined chatbot-style interface that makes interacting with MLZero intuitive and engaging. Furthermore, we’re also bringing MCP (Model Control Protocol) integration to MLZero, enabling seamless remote orchestration of AutoML pipelines through a standardized protocol。
AutoGluon Assistant is supported on Python 3.8 - 3.11 and is available on Linux.
Installation:
pip install uv
uv pip install autogluon.assistant>=1.0
To use CLI:
mlzero -i <input_data_dir>
To use webUI:
mlzero-backend # command to start backend
mlzero-frontend # command to start frontend on 8509 (default)
To use MCP:
# server
mlzero-backend # command to start backend
bash ./src/autogluon/mcp/server/start_services.sh # This will start the service—run it in a new terminal.
# client
python ./src/autogluon/mcp/client/server.py
MLZero Authors: Haoyang Fang, Boran Han, Steven Shen, Nick Erickson, Xiyuan Zhang, Su Zhou, Anirudh Dagar, Jiani Zhang, Ali Caner Turkmen, Cuixiong Hu, Huzefa Rangwala, Ying Nian Wu, Bernie Wang, George Karypis
Mitra
🚀 Mitra is a new state-of-the-art tabular foundation model developed by the AutoGluon team, natively supported in AutoGluon with just three lines of code via predictor.fit(train_data, hyperparameters={"MITRA": {}}). Built on the in-context learning paradigm and pretrained exclusively on synthetic data, Mitra introduces a principled pretraining approach by carefully selecting and mixing diverse synthetic priors to promote robust generalization across a wide range of real-world tabular datasets. Mitra is incorporated into the new extreme preset.
📊 Mitra achieves state of the art performance on major benchmarks including TabRepo, TabZilla, AMLB, and TabArena, especially excelling on small tabular datasets with fewer than 5,000 samples and 100 features, for both classification and regression tasks.
🧠 Mitra supports both zero-shot and fine-tuning modes and runs seamlessly on both GPU and CPU. Its weights are fully open-sourced under the Apache-2.0 license, making it a privacy-conscious and production-ready solution for enterprises concerned about data sharing and hosting.
🔗 Learn more by reading the Mitra release blog post and on HuggingFace:
Classification model: autogluon/mitra-classifier
Regression model: autogluon/mitra-regressor
We welcome community feedback for future iterations. Give us a like on HuggingFace if you want to see more cutting-edge foundation models for structured data!
Mitra Authors: Xiyuan Zhang, Danielle Robinson, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, Bernie Wang
General
Add CPU utility functions for better CPU detection in restrained env such as docker and slurm cluster. @tonyhoo (#5197)
Use joblib instead of loky for cpu detection. @shchur (#5215)
Support Apple Silicon and log it in the system info. @tonyhoo (#5141)
Add load pickle from url support, fix save_str if root path. @Innixma (#5142)
Use pyarrow by default, remove fastparquet. @Innixma (#5150)
Resolve AttributeError in LinearModel when using RAPIDS cuML models. @tonyhoo (#5157)
prioritize the CUDA libraries from PyTorch wheel instead of the system/DLC. @FireballDWF (#5163)
update numpy cap, thus 2.3.0 is allowed. @FireballDWF (#5170)
Replace pkg_resources.parse_version with packaging.version.parse. @shchur (#5182)
Update pandas, scikit-learn, and scipy version caps in setup utils. @tonyhoo (#5194)
Enhance spunge_augment and munge_augment functions for model distillation. @tonyhoo (#5208)
Increase pytorch cap to 2.8 to enable 2.7. @FireballDWF (#5089)
Resolve datetime deprecation warnings. @emmanuel-ferdman (#5069)
Tabular
New Presets
Add extreme preset with meta-learned TabArena portfolio. @Innixma (#5211)
The
extremepreset is the largest singular improvement to AutoGluon’s predictive performance in the history of the package, even larger than the improvement seen in AutoGluon 1.0 compared to 0.8.For more information, refer to the highlights section above.
New Models
Mitra
Add Mitra Model (key:
"MITRA"). @xiyuanzh, @dcmaddix, @junmingy, @Innixma, @tonyhoo (#5195, #5218, #5232, #5221)Install via
pip install autogluon.tabular[all,mitra](and natively inpip install autogluon)Blog Post: Mitra: Mixed synthetic priors for enhancing tabular foundation models
TabPFNv2
Add TabPFNv2 Model (key:
"TABPFNV2"). @LennartPurucker, @Innixma (#5191)Install via
pip install autogluon.tabular[all,tabpfn](orpip install autogluon[tabarena])Paper: Accurate predictions on small data with a tabular foundation model
TabICL
Add TabICL Model (key:
"TABICL"). @LennartPurucker, @Innixma (#5193)Install via
pip install autogluon.tabular[all,tabicl](orpip install autogluon[tabarena])Paper: TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
RealMLP
Add RealMLP Model (key:
"REALMLP"). @dholzmueller, @Innixma, @LennartPurucker (#5190)-Install via
pip install autogluon.tabular[all,realmlp](orpip install autogluon[tabarena])Paper: Better by Default: Strong Pre-Tuned MLPs and Boosted Trees on Tabular Data
TabM
Add TabM Model (key:
"TABM"). @LennartPurucker, @dholzmueller, @Innixma (#5196)Install via
pip install autogluon.tabular[all,tabm](and natively inpip install autogluon)Paper: TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
Removals
Removed TabPFNv1 model, as it is incompatible with TabPFNv2. @Innixma (#5191)
Removed KNN model from
best_qualityandhigh_qualitypreset portfolios, as it did not generally improve results. @Innixma (#5211)
Fixes and Improvements
Respect num_cpus/num_gpus in sequential_local fit. @Innixma (#5203)
Switch to loky for get_cpu_count in all places. @Innixma (#5204)
Add support for max_rows, max_features, max_classes, problem_types. @Innixma (#5181)
Fix CatBoost crashing for problem_type=”quantile” if len(quantile_levels) == 1. @shchur (#5201)
Add tabular foundational model cache from s3 to benchmark to avoid rate limit issue from HF. @tonyhoo (#5214)
Fix default loss_function for CatBoostModel with problem_type=’regression’. @shchur (#5216)
Minor enhancements and fixes. @adibiasio, @Innixma (#5158)
TimeSeries
Highlights
Major efficiency improvements to the core
TimeSeriesDataFramemethods, resulting in up to 7x lower end-to-endpredictor.fit()andpredict()time when working with large datasets (>10M rows).New tabular forecasting model
PerStepTabularthat fits a separate tabular regression model for each time step in the forecast horizon. Both fitting and inference for the model are parallelized across cores, resulting in one of the most efficient and accurate implementations of this model among open-source Python packages.
API Changes and Deprecations
DirectTabularandRecursiveTabularmodels: hyperparameterstabular_hyperparametersandtabular_fit_kwargsare now deprecated in favor ofmodel_nameandmodel_hyperparameters.These models now fit a single regression model from
autogluon.tabularunder the hood instead of creating an entireTabularPredictor. This results in lower disk usage and API better aligned with the rest of thetimeseriesmodule.Details and example usage
# New API: >= v1.4.0 predictor.fit( ..., hyperparameters={ "RecursiveTabular": {"model_name": "CAT", "model_hyperparameters": {"iterations": 100}} } ) # Old API: <= v1.3.1 predictor.fit( ..., hyperparameters={ "RecursiveTabular": {"tabular_hyperparameters": {"CAT": {"iterations": 100}}} } )
If you provide
tabular_hyperparameterswith a single model in v1.4.0, a warning will be logged and the parameter will be automatically converted to match the new API.If you provide
tabular_hyperparameterswith >=2 models in v1.4.0, an error will be raised since it cannot automatically be converted to the new API.Chronosmodel: Hyperparameteroptimization_strategy(deprecated in v1.3.0) has been removed in v1.4.0.
New Features
Add
PerStepTabularmodel that fits a separate tabular regression model for each step in the forecast horizon. @shchur (#5189, #5213)Improve heuristic for long-term forecast unrolling (
prediction_length > 64) for Chronos-Bolt. @abdulfatir (#5177)RecursiveTabularmodel now supports thelag_transformshyperparameter. @shchur (#5184)
Fixes and Improvements
Improve the runtime of various
TimeSeriesDataFrameoperations by replacinggroupbywith efficient alternatives based onindptr. @shchur (#5159)Refactor
DirectTabularandRecursiveTabularmodels to use a single tabular model under the hood instead of aTabularPredictor. (#5212)Reorganize
autogluon.timeseries.models.gluontsnamespace. @canerturkmen (#5104)Log the full stack trace in case of individual model failures during training. @shchur (#5178)
Deprecate the
optimization_strategyhyperparameter for the Chronos (classic) model. @shchur (#5202)Fix incompatibility with python 3.9. @prateekdesai04 (#5220)
Refactor the implementation of
RecursiveTabularandDirectTabularmodels. @shchur (#5184, #5206)Fix typos and layout issues in the documentation. @shchur (#5225)
Fix refit_full failing during ensemble prediction if quantile_levels=[]. @shchur (#5242)
Multimodal
Change multilingual preset to use FP32 to avoid DeBERTa BFloat16. @tonyhoo (#5139)
Update NLTK dependency constraint to <3.10 to address CVE-2024-39705. @tonyhoo (#5147)
Documentation and CI
Fix Python syntax in CUDA library path detection. @tonyhoo (#5166)
Show tabular model aliases in the documentation. @shchur (#5183)
Fix lint check. @prateekdesai04 (#5192)
Add time limit conversion to seconds in benchmark config script. @tonyhoo (#5224)
Special Thanks
Lennart Purucker and David Holzmüller for helping to implement TabPFNv2, TabICL, RealMLP and TabM, along with providing improved memory estimate logic for the models.
Steven Shen for implementing the front-end web UI and MCP backend for MLZero.
Atharva Rajan Kale for helping to automate and streamline our DLC release process.
Contributors
Full Contributor List (ordered by # of commits):
@shchur @Innixma @tonyhoo @prateekdesai04 @FireballDWF @canerturkmen @abdulfatir @rsj123 @xiyuanzh @mwhol @daradib @emmanuel-ferdman @adibiasio @LennartPurucker @dholzmueller
New Contributors
v1.3.1
Version 1.3.1
We are happy to announce the AutoGluon 1.3.1 release!
AutoGluon 1.3.1 contains several bug fixes and logging improvements for Tabular, TimeSeries, and Multimodal modules.
This release contains 9 commits from 5 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/1.3.0…1.3.1
Join the community:
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.3.1.
General
Tabular
Fixes and Improvements
Fix incorrect reference to positive_class in TabularPredictor constructor. @celestinoxp #5129
TimeSeries
Fixes and Improvements
Avoid masking the
scalerparam with the defaulttarget_scalervalue forDirectTabularandRecursiveTabularmodels. @shchur #5131Fix
FutureWarningin leaderboard and evaluate methods. @shchur #5126
Multimodal
Fixes and Improvements
Documentation and CI
Contributors
Full Contributor List (ordered by # of commits):
New Contributors
v1.3.0
Version 1.3.0
We are happy to announce the AutoGluon 1.3.0 release!
AutoGluon 1.3 focuses on stability & usability improvements, bug fixes, and dependency upgrades.
This release contains 144 commits from 20 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v1.2.0…v1.3.0
Join the community:
Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.3.
Highlights
AutoGluon-Tabular is the state of the art in the AutoML Benchmark 2025!
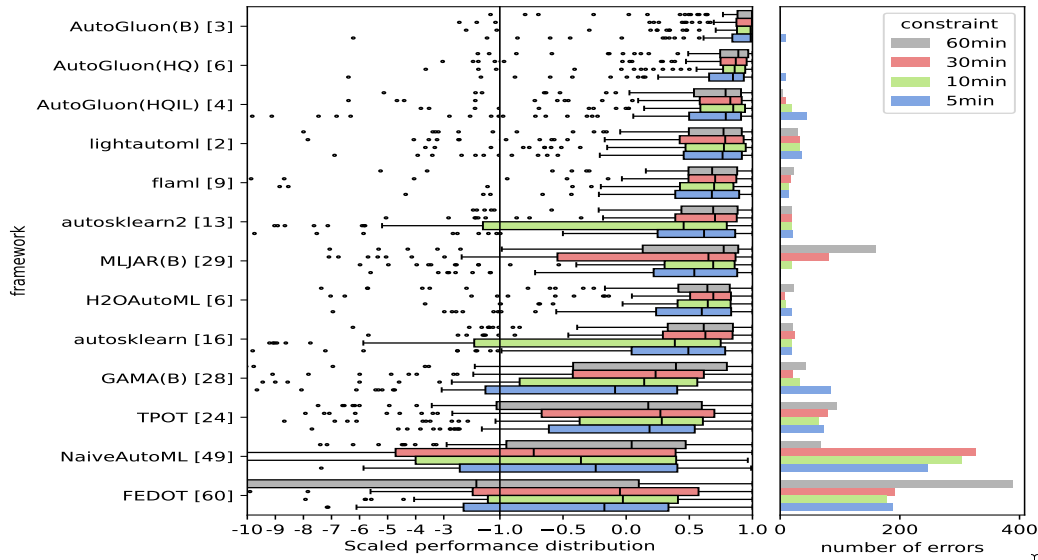
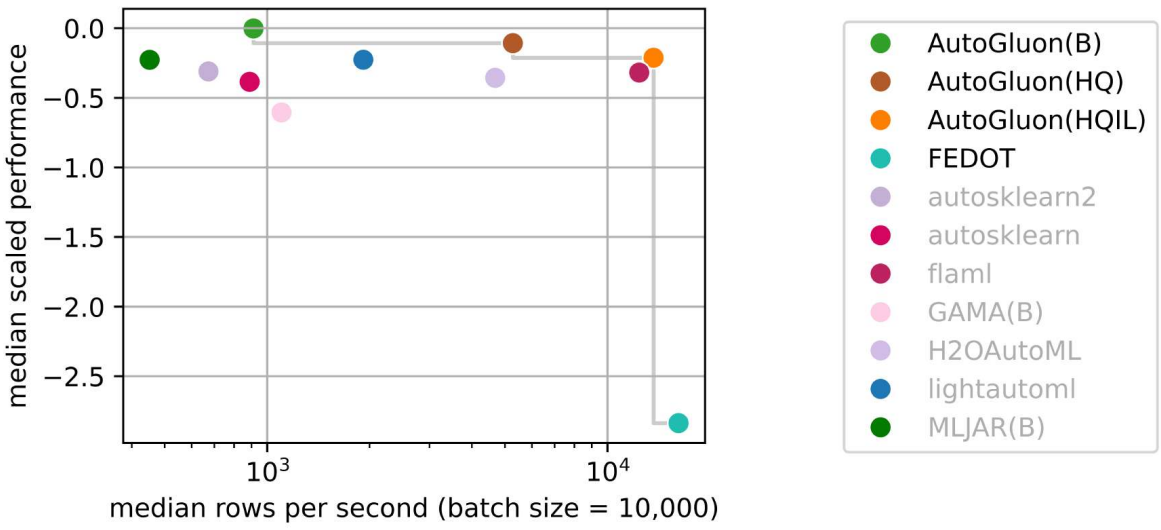
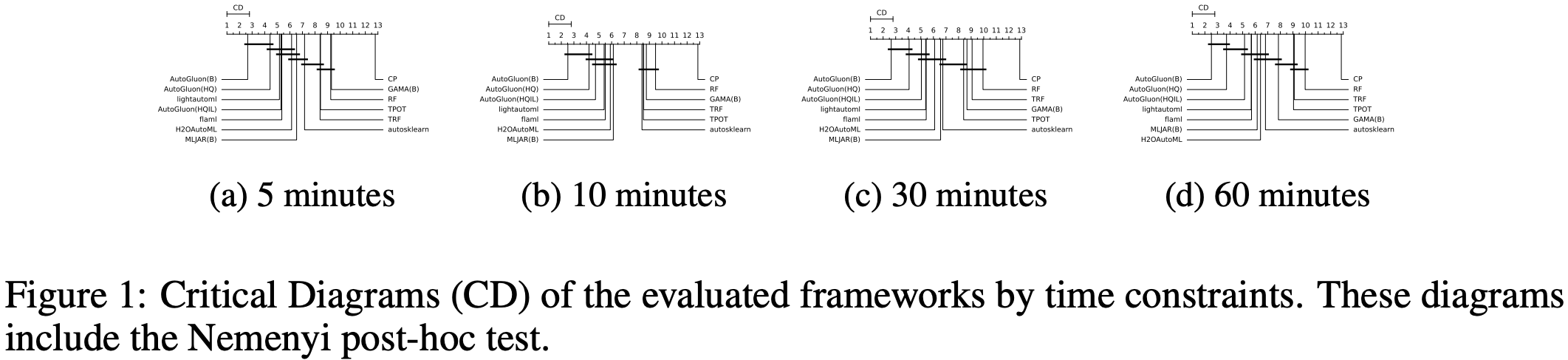
The AutoML Benchmark 2025, an independent large-scale evaluation of tabular AutoML frameworks, showcases AutoGluon 1.2 as the state of the art AutoML framework! Highlights include:
AutoGluon’s rank statistically significantly outperforms all AutoML systems via the Nemenyi post-hoc test across all time constraints.
AutoGluon with a 5 minute training budget outperforms all other AutoML systems with a 1 hour training budget.
AutoGluon is pareto efficient in quality and speed across all evaluated presets and time constraints.
AutoGluon with
presets="high", infer_limit=0.0001(HQIL in the figures) achieves >10,000 samples/second inference throughput while outperforming all methods.AutoGluon is the most stable AutoML system. For “best” and “high” presets, AutoGluon has 0 failures on all time budgets >5 minutes.
AutoGluon Multimodal’s “Bag of Tricks” Update
We are pleased to announce the integration of a comprehensive “Bag of Tricks” update for AutoGluon’s MultiModal (AutoMM). This significant enhancement substantially improves multimodal AutoML performance when working with combinations of image, text, and tabular data. The update implements various strategies including multimodal model fusion techniques, multimodal data augmentation, cross-modal alignment, tabular data serialization, better handling of missing modalities, and an ensemble learner that integrates these techniques for optimal performance.
Users can now access these capabilities through a simple parameter when initializing the MultiModalPredictor after following the instruction here to download the checkpoints:
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label="label", use_ensemble=True)
predictor.fit(train_data=train_data)
We express our gratitude to @zhiqiangdon, for this substantial contribution that enhances AutoGluon’s capabilities for handling complex multimodal datasets. Here is the corresponding research paper describing the technical details: Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data.
Deprecations and Breaking Changes
The following deprecated TabularPredictor methods have been removed in the 1.3.0 release (deprecated in 1.0.0, raise in 1.2.0, removed in 1.3.0). Please use the new names:
persist_models->persist,unpersist_models->unpersist,get_model_names->model_names,get_model_best->model_best,get_pred_from_proba->predict_from_proba,get_model_full_dict->model_refit_map,get_oof_pred_proba->predict_proba_oof,get_oof_pred->predict_oof,get_size_disk_per_file->disk_usage_per_file,get_size_disk->disk_usage,get_model_names_persisted->model_names(persisted=True)
The following logic has been deprecated starting in 1.3.0 and will log a FutureWarning. Functionality will be changed in a future release:
(FutureWarning)
TabularPredictor.delete_models()will default todry_run=Falsein a future release (currentlydry_run=True). Please ensure you explicitly specifydry_run=Truefor the existing logic to remain in future releases. @Innixma (#4905)
General
Improvements
(Major) Internal refactor of
AbstractTrainerclass to improve extensibility and reduce code duplication. @canerturkmen (#4804, #4820, #4851)
Dependencies
Update numpy to
>=1.25.0,<2.3.0. @tonyhoo, @Innixma, @suzhoum (#5020, #5056, #5072)Update scikit-learn to
>=1.4.0,<1.7.0. @tonyhoo, @Innixma (#5029, #5045)Update ray to
>=2.10.0,<2.45. @suzhoum, @celestinoxp, @tonyhoo (#4714, #4887, #5020)Update torch to
>=2.2,<2.7. @FireballDWF (#5000)Update lightning to
>=2.2,<2.7. @FireballDWF (#5000)Update torchmetrics to
>=1.2.0,<1.8. @zkalson, @tonyhoo (#4720, #5020)Update torchvision to
>=0.16.0,<0.22.0. @FireballDWF (#5000)Update accelerate to
>=0.34.0,<2.0. @FireballDWF (#5000)Update pytorch-metric-learning to
>=1.3.0,<2.9. @tonyhoo (#5020)
Documentation
Updating documented python version’s in CONTRIBUTING.md. @celestinoxp (#4796)
Refactored CONTRIBUTING.md to have up-to-date information. @Innixma (#4798)
Fix various typos. @celestinoxp (#4819)
Fixes and Improvements
Fix colab AutoGluon source install with
uv. @tonyhoo (#4943, #4964)Make
full_install.shuse the script directory instead of the working directory. @Innixma (#4933)Add
test_version.pyto ensure proper version format for releases. @Innixma (#4799)Ensure
setup_outputdiralways makes a new directory ifpath_suffix != Noneandpath=None. @Innixma (#4903)Check
cuda.is_available()before callingcuda.device_count()to avoid warnings. @Innixma (#4902)Log a warning if mlflow autologging is enabled. @shchur (#4925)
Fix rare ZeroDivisionError edge-case in
get_approximate_df_mem_usage. @shchur (#5083)Minor fixes & improvements. @suzhoum @Innixma @canerturkmen @PGijsbers @tonyhoo (#4744, #4785, #4822, #4860, #4891, #5012, #5047)
Tabular
Removed Models
Removed vowpalwabbit model (key:
VW) and optional dependency (autogluon.tabular[vowpalwabbit]), as the model implemented in AutoGluon was not widely used and was largely unmaintained. @Innixma (#4975)Removed TabTransformer model (key:
TRANSF), as the model implemented in AutoGluon was heavily outdated, unmaintained since 2020, and generally outperformed by FT-Transformer (key:FT_TRANSFORMER). @Innixma (#4976)Removed tabpfn from
autogluon.tabular[tests]install in preparation for futuretabpfn>=2.xsupport. @Innixma (#4974)
New Features
Add support for regression stratified splits via binning. @Innixma (#4586)
Add
TabularPredictor.model_hyperparameters(model)that returns the hyperparameters of a model. @Innixma (#4901)Add
TabularPredictor.model_info(model)that returns the metadata of a model. @Innixma (#4901)(Experimental) Add
plot_leaderboard.pyto visualize performance over training time of the predictor. @Innixma (#4907)(Major) Add internal
ag_model_registryto improve the tracking of supported model families and their capabilities. @Innixma (#4913, #5057, #5107)Add
raise_on_model_failureTabularPredictor.fitargument, default to False. If True, will immediately raise the original exception if a model raises an exception during fit instead of continuing to the next model. Setting to True is very helpful when using a debugger to try to figure out why a model is failing, as otherwise exceptions are handled by AutoGluon which isn’t desired while debugging. @Innixma (#4937, #5055)
Documentation
Fixes and Improvements
(Major) Ensure bagged refits in refit_full works properly (crashed in v1.2.0 due to a bug). @Innixma (#4870)
Improve XGBoost and CatBoost memory estimates. @Innixma (#5090)
Fixed balanced_accuracy metric edge-case exception + added unit tests to ensure future bugs don’t occur. @Innixma (#4775)
Fix crash when NN_TORCH trains with fewer than 8 samples. @Innixma (#4790)
Improve logging and documentation in CatBoost memory_check callback. @celestinoxp (#4802)
Improve code formatting to satisfy PEP585. @celestinoxp (#4823)
Remove deprecated TabularPredictor methods: @Innixma (#4906)
(FutureWarning)
TabularPredictor.delete_models()will default todry_run=Falsein a future release (currentlydry_run=True). Please ensure you explicitly specifydry_run=Truefor the existing logic to remain in future releases. @Innixma (#4905)Sped up tabular unit tests by 4x through various optimizations (3060s -> 743s). @Innixma (#4944)
Major tabular unit test refactor to avoid using fixtures. @Innixma (#4949)
Fix
TabularPredictor.refit_full(train_data_extra)failing when categorical features exist. @Innixma (#4948)Reduced memory usage of artifact created by
convert_simulation_artifacts_to_tabular_predictions_dictby 4x. @Innixma (#5024)Ensure that max model resources is respected during holdout model fit. @Innixma (#5067)
Remove unintended setting of global random seed during LightGBM model fit. @Innixma (#5095)
TimeSeries
The new v1.3 release brings numerous usability improvements and bug fixes to the TimeSeries module. Internally, we completed a major refactor of the core classes and introduced static type checking to simplify future contributions, accelerate development, and catch potential bugs earlier.
API Changes and Deprecations
As part of the refactor, we made several changes to the internal
AbstractTimeSeriesModelclass. If you maintain a custom model implementation, you will likely need to update it. Please refer to the custom forecasting model tutorial for details.No action is needed from the users that rely solely on the public API of the
timeseriesmodule (TimeSeriesPredictorandTimeSeriesDataFrame).
New Features
New tutorial on adding custom forecasting models by @shchur in #4749
Add
cutoffsupport inevaluateandleaderboardby @abdulfatir in #5078Add
horizon_weightsupport forTimeSeriesPredictorby @shchur in #5084Add
make_future_data_framemethod to TimeSeriesPredictor by @shchur in #5051Refactor ensemble base class and add new ensembles by @canerturkmen in #5062
Code Quality
Add static type checking for the
timeseriesmodule by @canerturkmen in #4712 #4788 #4801 #4821 #4969 #5086 #5085Refactor the
AbstractTimeSeriesModelclass by @canerturkmen in #4868 #4909 #4946 #4958 #5008 #5038Improvements to the unit tests by @canerturkmen in #4773 #4828 #4877 #4872 #4884 #4888
Fixes and Improvements
Allow using custom
distr_outputwith the TFT model by @shchur in #4899Update version ranges for
statsforecast&coreforecastby @shchur in #4745Fix feature importance calculation for models that use a
covariate_regressorby @canerturkmen in #4845Fix hyperparameter tuning for Chronos and other models by @abdulfatir @shchur in #4838 #5075 #5079
Fix frequency inference for
TimeSeriesDataFrameby @abdulfatir @shchur in #4834 #5066Update docs for custom
distr_outputby @Killer3048 in #5068Raise informative error message if invalid model name is provided by @shchur in #5004
Gracefully handle corrupted cached predictions by @shchur in #5005
Chronos-Bolt: Fix scaling that affects constant series by @abdulfatir in #5013
Fix deprecated
evaluation_strategykwarg intransformersby @abdulfatir in #5019Fix time_limit when val_data is provided #5046 by @shchur in #5059
Rename covariate metadata by @canerturkmen in #5064
Fix NaT timestamp values during resampling by @shchur in #5080
Fix typing compatibility for py39 by @suzhoum @shchur in #5094 #5097
Warn if an S3 path is provided to the
TimeSeriesPredictorby @shchur in #5091
Multimodal
New Features
AutoGluon’s MultiModal module has been enhanced with a comprehensive “Bag of Tricks” update that significantly improves performance when working with combined image, text, and tabular data through advanced fusion techniques, data augmentation, and an integrated ensemble learner now accessible via a simple use_ensemble=True parameter after following the instruction here to download the checkpoints.
[AutoMM] Bag of Tricks by @zhiqiangdon in #4737
Documentation
[Tutorial] categorical convert_to_text default value by @cheungdaven in #4699
[AutoMM] Fix and Update Object Detection Tutorials by @FANGAreNotGnu in #4889
Fixes and Improvements
Update s3 path to public URL for AutoMM unit tests by @suzhoum in #4809
Fix object detection tutorial and default behavior of predict by @FANGAreNotGnu in #4865
Fix NLTK tagger path in download function by @k-ken-t4g in #4982
Fix AutoMM model saving logic by capping transformer range by @tonyhoo in #5007
fix: account for distributed training in learning rate schedule by @tonyhoo in #5003
Special Thanks
Zhiqiang Tang for implementing “Bag of Tricks” for AutoGluon’s MultiModal, which significantly enhances the multimodal performance.
Caner Turkmen for leading the efforts on refactoring and improving the internal logic in the
timeseriesmodule.Celestino for providing numerous bug reports, suggestions, and code cleanup as a new contributor.
Contributors
Full Contributor List (ordered by # of commits):
@Innixma @shchur @canerturkmen @tonyhoo @abdulfatir @celestinoxp @suzhoum @FANGAreNotGnu @prateekdesai04 @zhiqiangdon @cheungdaven @LennartPurucker @abhishek-iitmadras @zkalson @nathanaelbosch @Killer3048 @FireballDWF @timostrunk @everdark @kbulygin @PGijsbers @k-ken-t4g
New Contributors
@celestinoxp made their first contribution in #4796
@PGijsbers made their first contribution in #4891
@k-ken-t4g made their first contribution in #4982
@FireballDWF made their first contribution in #5000
@Killer3048 made their first contribution in #5068
v1.2.0
Version 1.2.0
We’re happy to announce the AutoGluon 1.2.0 release.
AutoGluon 1.2 contains massive improvements to both Tabular and TimeSeries modules, each achieving a 70% win-rate vs AutoGluon 1.1. This release additionally adds support for Python 3.12 and drops support for Python 3.8.
This release contains 186 commits from 19 contributors! See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v1.1.1…v1.2.0
Join the community:
Get the latest updates:
Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.2.
For Tabular, we encompass the primary enhancements of the new TabPFNMix tabular foundation model and parallel fit strategy into the new "experimental_quality" preset to ensure a smooth transition period for those who wish to try the new cutting edge features. We will be using this release to gather feedback prior to incorporating these features into the other presets. We also introduce a new stack layer model pruning technique that results in a 3x inference speedup on small datasets with zero performance loss and greatly improved post-hoc calibration across the board, particularly on small datasets.
For TimeSeries, we introduce Chronos-Bolt, our latest foundation model integrated into AutoGluon, with massive improvements to both accuracy and inference speed compared to Chronos, along with fine-tuning capabilities. We also added covariate regressor support!
We are also excited to announce AutoGluon-Assistant (AG-A), our first venture into the realm of Automated Data Science.
See more details in the Spotlights below!
Spotlight
AutoGluon Becomes the Golden Standard for Competition ML in 2024
Before diving into the new features of 1.2, we would like to start by highlighting the wide-spread adoption AutoGluon has received on competition ML sites like Kaggle in 2024. Across all of 2024, AutoGluon was used to achieve a top 3 finish in 15 out of 18 tabular Kaggle competitions, including 7 first place finishes, and was never outside the top 1% of private leaderboard placements, with an average of over 1000 competing human teams in each competition. In the $75,000 prize money 2024 Kaggle AutoML Grand Prix, AutoGluon was used by the 1st, 2nd, and 3rd place teams, with the 2nd place team led by two AutoGluon developers: Lennart Purucker and Nick Erickson! For comparison, in 2023 AutoGluon achieved only 1 first place and 1 second place solution. We attribute the bulk of this increase to the improvements seen in AutoGluon 1.0 and beyond.

We’d like to emphasize that these results are achieved via human expert interaction with AutoGluon and other tools, and often includes manual feature engineering and hyperparameter tuning to get the most out of AutoGluon. To see a live tracking of all AutoGluon solution placements on Kaggle, refer to our AWESOME.md ML competition section where we provide links to all solution write-ups.
AutoGluon-Assistant: Automating Data Science with AutoGluon and LLMs
We are excited to share the release of a new AutoGluon-Assistant module (AG-A), powered by LLMs from AWS Bedrock or OpenAI. AutoGluon-Assistant empowers users to solve tabular machine learning problems using only natural language descriptions, in zero lines of code with our simple user interface. Fully autonomous AG-A outperforms 74% of human ML practitioners in Kaggle competitions and secured a live top 10 finish in the $75,000 prize money 2024 Kaggle AutoML Grand Prix competition as Team AGA 🤖!
TabularPredictor presets=”experimental_quality”
TabularPredictor has a new "experimental_quality" preset that offers even better predictive quality than "best_quality". On the AutoMLBenchmark, we observe a 70% winrate vs best_quality when running for 4 hours on a 64 CPU machine. This preset is a testing ground for cutting edge features and models which we hope to incorporate into best_quality for future releases. We recommend to use a machine with at least 16 CPU cores, 64 GB of memory, and a 4 hour+ time_limit to get the most benefit out of experimental_quality. Please let us know via a GitHub issue if you run into any problems running the experimental_quality preset.
TabPFNMix: A Foundation Model for Tabular Data
TabPFNMix is the first tabular foundation model created by the AutoGluon team, and was pre-trained exclusively on synthetic data. The model builds upon the prior work of TabPFN and TabForestPFN. TabPFNMix to the best of our knowledge achieves a new state-of-the-art for individual open source model performance on datasets between 1000 and 10000 samples, and also supports regression tasks! Across the 109 classification datasets with less than or equal to 10000 training samples in TabRepo, fine-tuned TabPFNMix outperforms all prior models, with a 64% win-rate vs the strongest tree model, CatBoost, and a 61% win-rate vs fine-tuned TabForestPFN.
The model is available via the TABPFNMIX hyperparameters key, and is used in the new experimental_quality preset. We recommend using this model for datasets smaller than 50,000 training samples, ideally with a large time limit and 64+ GB of memory. This work is still in the early stages, and we appreciate any feedback from the community to help us iterate and improve for future releases. You can learn more by going to our HuggingFace model page for the model (tabpfn-mix-1.0-classifier, tabpfn-mix-1.0-regressor). Give us a like on HuggingFace if you want to see more! A paper is planned in future to provide more details about the model.
fit_strategy=”parallel”
AutoGluon’s TabularPredictor now supports the new fit argument fit_strategy and the new "parallel" option, enabled by default in the new experimental_quality preset. For machines with 16 or more CPU cores, the parallel fit strategy offers a major speedup over the previous "sequential" strategy. We estimate with 64 CPU cores that most datasets will experience a 2-4x speedup, with the speedup getting larger as CPU cores increase.
Chronos-Bolt⚡: a 250x faster, more accurate Chronos model
Chronos-Bolt is our latest foundation model for forecasting that has been integrated into AutoGluon. It is based on the T5 encoder-decoder architecture and has been trained on nearly 100 billion time series observations. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the original Chronos models of the same size.
The following plot compares the inference time of Chronos-Bolt against the original Chronos models for forecasting 1024 time series with a context length of 512 observations and a prediction horizon of 64 steps.

Chronos-Bolt models are not only significantly faster but also more accurate than the original Chronos models. The following plot reports the probabilistic and point forecasting performance of Chronos-Bolt in terms of the Weighted Quantile Loss (WQL) and the Mean Absolute Scaled Error (MASE), respectively, aggregated over 27 datasets (see the Chronos paper for details on this benchmark). Remarkably, despite having no prior exposure to these datasets during training, the zero-shot Chronos-Bolt models outperform commonly used statistical models and deep learning models that have been trained on these datasets (highlighted by *). Furthermore, they also perform better than other FMs, denoted by a +, which indicates that these models were pretrained on certain datasets in our benchmark and are not entirely zero-shot. Notably, Chronos-Bolt (Base) also surpasses the original Chronos (Large) model in terms of the forecasting accuracy while being over 600 times faster.

Chronos-Bolt models are now available through AutoGluon in four sizes—Tiny (9M), Mini (21M), Small (48M), and Base (205M)—and can also be used on the CPU. With the addition of Chronos-Bolt models and other enhancements, AutoGluon v1.2 achieves a 70%+ win rate against the previous release!
In addition to the new Chronos-Bolt models, we have also added support for effortless fine-tuning of Chronos and Chronos-Bolt models. Check out the updated Chronos tutorial to learn how to use and fine-tune Chronos-Bolt models.
Time Series Covariate Regressors
We have added support for covariate regressors for all forecasting models. Covariate regressors are tabular regression models that can be combined with univariate forecasting models to incorporate exogenous information. These are particularly useful for foundation models like Chronos-Bolt, which rely solely on the target time series’ historical data and cannot directly use exogenous information (such as holidays or promotions). To improve the predictions of univariate models when covariates are available, a covariate regressor is first fit on the known covariates and static features to predict the target column at each time step. The predictions of the covariate regressor are then subtracted from the target column, and the univariate model then forecasts the residuals. The Chronos tutorial showcases how covariate regressors can be used with Chronos-Bolt.
General
Improvements
Update
full_install.shto install AutoGluon in parallel and to useuv, resulting in much faster source installation times. @Innixma (#4582, #4587, #4592)
Dependencies
Python 3.8 support dropped. @prateekdesai04 (#4512)
Update ray to
>=2.10.0,<2.40. @suzhoum, @Innixma (#4302, #4688)Update scikit-learn to
>=1.4.0,<1.5.3. @prateekdesai04 (#4420, #4570)Update pyarrow to
>=15.0.0. @prateekdesai04 (#4520)Update psutil to
>=5.7.3,<7.0.0. @prateekdesai04 (#4570)Update Pillow to
>=10.0.1,<12. @prateekdesai04 (#4570)Update xgboost to
>=1.6,<2.2. @prateekdesai04 (#4570)Update timm to
>=0.9.5,<1.0.7. @prateekdesai04 (#4580)Update accelerate to
>=0.34.0,<1.0. @cheungdaven @tonyhoo @shchur (#4596, #4612, #4676)Update scikit-learn-intelex to
>=2024.0,<2025.1. @Innixma (#4688)
Documentation
Update install instructions to use proper torch and ray versions. @Innixma (#4581)
Add SECURITY.md for vulnerability reporting. @tonyhoo (#4298)
Fixes and Improvements
Speed up DropDuplicatesFeatureGenerator fit time by 2x+. @shchur (#4543)
Add
compute_metricas a replacement forcompute_weighted_metricwith improved compatibility across the project. @Innixma (#4631)
Tabular
New Features
Add TabPFNMix model. Try it out with
presets="experimental". @xiyuanzh @Innixma (#4671, #4694)Parallel model fit support. Try it out with
fit_strategy="parallel". @LennartPurucker @Innixma (#4606)Learning curve generation feature. @adibiasio @Innixma (#4411, #4635)
Set
calibrate_decision_threshold="auto"by default, and improve decision threshold calibration. This dramatically improves results when the eval_metric isf1andbalanced_accuracyfor binary classification. @Innixma (#4632)Add support for custom memory (soft) limits. @LennartPurucker (#4333)
Add
ag.compilehyperparameter to models to enable compiling at fit time rather than withpredictor.compile. @Innixma (#4354)Add AdaptiveES support to NN_TORCH and increase max_epochs from 500 to 1000, enabled by default. @Innixma (#4436)
Add support for controlling repeated cross-validation behavior via
delay_bag_setsfit argument. Set default to False (previously True). @LennartPurucker (#4552)Make
positive_classan init argument of TabularPredictor. @Innixma (#4445)
Documentation
Added a tutorial with a deep dive on how AutoGluon works. @rey-allan (#4284)
Fixes and Improvements
(Major) Fix stacker max_models logic for a 3x inference speedup. @Innixma (#4290)
(Major) Speed up EnsembleSelection fitting speed by 2x+. @nathanaelbosch (#4367)
(Major) Dramatically improve temperature scaling performance by using the best iteration instead of the last iteration’s temperature. @LennartPurucker (#4396)
(Major) Automatically skip temperature scaling if negative temperature is found. @Innixma (#4397)
(Major) Fix
roc_aucmetric to usemacrofor multiclass instead ofweighted. @LennartPurucker (#4407)(Major) Ensure
refit_fullrespects user specifiednum_cpusandnum_gpus. @Innixma (#4495)(Major) Refactor TabularDataset. Now TabularDataset will always return a pandas DataFrame object when initialized, to simplify various documentation and improve IDE debugging visualization compatibility. @Innixma (#4613)
Fix bug where validation data is not used when in HPO mode when no search space is provided for the model. @echowve (#4667)
Set
num_bag_sets=1by default, to avoidnum_bag_sets>1being used if the user doesn’t use a preset and setsnum_bag_folds>=2. @Innixma (#4446)Fix FASTAI crash when a column contains only a single unique value + NaNs. @Innixma (#4584)
Fix torch seed accidentally being updated on model.score calls in NN_TORCH. @adibiasio (#4391)
Fix LightGBM predict_proba quantile output dtype. @Innixma (#4272)
Fix incorrect return type for
predict_multifor regression. @Innixma (#4450)Improved error messages when given invalid hyperparameters. @Innixma (#4258)
Improved user specified
num_cpusandnum_gpussanity checking. @Innixma (#4277)Add readable error message for invalid models in
predictor.persistcalls. @Innixma (#4285)Add toggle
raise_on_no_models_fittedto control if AutoGluon errors when no models are fit. @LennartPurucker (#4389)Make
raise_on_no_models_fitted=Trueby default. Was False in previous release. @Innixma (#4400)Add
valid_stackeranduse_orig_featuresmodel options. @Innixma (#4444)Improve reliability of
predictor.predict_proba_multiin edge-case scenarios. @Innixma (#4527)Fix edgecase crash during label column handling if it is a pandas category dtype with 0 instances of a category. @Innixma (#4583)
Enable aarch64 platform build. @abhishek-iitmadras (#4663)
Minor fixes. @Innixma @LennartPurucker @shchur @rsj123 (#4224, #4317, #4335, #4352, #4353, #4379, #4384, #4474, #4485, #4675, #4682, #4700)
Minor unit tests, documentation, and cleanup. @Innixma @abhishek-iitmadras (#4398, #4399, #4402, #4498, #4546, #4547, #4549, #4687, #4690, #4692)
TimeSeries
New Features
Add fine-tuning support for Chronos and Chronos-Bolt models @abdulfatir (#4608, #4645, #4653, #4655, #4659, #4661, #4673, #4677)
Add Chronos-Bolt @canerturkmen (#4625)
TimeSeriesPredictor.leaderboardnow can compute extra metrics and return hyperparameters for each model @shchur (#4481)Add
target_scalersupport for all forecasting models @shchur (#4460, #4644)Add
covariate_regressorsupport for all forecasting models @shchur (#4566, #4641)Add method to convert a TimeSeriesDataFrame to a regular pd.DataFrame @shchur (#4415)
[experimental] Add the weighted cumulative error forecasting metric @shchur (#4594)
[experimental] Allow custom ensemble model types for time series @shchur (#4662)
Fixes and Improvements
Update presets @canerturkmen @shchur (#4656, #4658, #4666, #4672)
Unify all Croston models into a single class @shchur (#4564)
Bump
statsforecastversion to 1.7 @canerturkmen @shchur (#4194, #4357)Fix deep learning models failing if item_ids have StringDtype @rsj123 (#4539)
Update logic for inferring the time series frequency @shchur (#4540)
Speed up and reduce memory usage of the
TimeSeriesFeatureGeneratorpreprocessing logic @shchur (#4557)Refactor GluonTS default parameter handling, update TiDE parameters @canerturkmen (#4640)
Move covariate scaling logic into a separate class @shchur (#4634)
Prune timeseries unit and smoke tests @canerturkmen (#4650)
Minor fixes @abdulfatir @canerturkmen @shchur (#4259, #4299, #4395, #4386, #4409, #4533, #4565, #4633, #4647)
Multimodal
Fixes and Improvements
Fix Missing Validation Metric While Resuming A Model Failed At Checkpoint Fusing Stage by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4449
Add coco_root for better support for custom dataset in COCO format. by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/3809
Add COCO Format Saving Support and Update Object Detection I/O Handling by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/3811
Skip MMDet Config Files While Checking with bandit by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4630
Fix Logloss Bug and Refine Compute Score Logics by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4629
Fix Index Typo in Tutorial by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4642
Fix Proba Metrics for Multiclass by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4643
Support torch 2.4 by @tonyhoo in https://github.com/autogluon/autogluon/pull/4360
Add Installation Guide for Object Detection in Tutorial by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4430
Add Bandit Warning Mitigation for Internal
torch.saveandtorch.loadUsage by @tonyhoo in https://github.com/autogluon/autogluon/pull/4502update accelerate version range by @cheungdaven in https://github.com/autogluon/autogluon/pull/4596
Bound nltk version to avoid verbose logging issue by @tonyhoo in https://github.com/autogluon/autogluon/pull/4604
Upgrade TIMM by @prateekdesai04 in https://github.com/autogluon/autogluon/pull/4580
Key dependency updates in _setup_utils.py for v1.2 release by @tonyhoo in https://github.com/autogluon/autogluon/pull/4612
Configurable Number of Checkpoints to Keep per HPO Trial by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4615
Refactor Metrics for Each Problem Type by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4616
Fix Torch Version and Colab Installation for Object Detection by @FANGAreNotGnu in https://github.com/autogluon/autogluon/pull/4447
Special Thanks
Xiyuan Zhang for leading the development of TabPFNMix!
The TabPFN author’s Noah Hollmann, Samuel Muller, Katharina Eggensperger, and Frank Hutter for unlocking the power of foundation models for tabular data, and the TabForestPFN author’s Felix den Breejen, Sangmin Bae, Stephen Cha, and Se-Young Yun for extending the idea to a more generic representation. Our TabPFNMix work builds upon the shoulders of giants.
Lennart Purucker for leading development of the parallel model fit functionality and pushing AutoGluon to its limits in the 2024 Kaggle AutoML Grand Prix.
Robert Hatch, Tilii, Optimistix, Mart Preusse, Ravi Ramakrishnan, Samvel Kocharyan, Kirderf, Carl McBride Ellis, Konstantin Dmitriev, and others for their insightful discussions and for championing AutoGluon on Kaggle!
Eddie Bergman for his insightful surprise code review of the tabular callback support feature.
Contributors
Full Contributor List (ordered by # of commits):
@Innixma @shchur @prateekdesai04 @tonyhoo @FangAreNotGnu @suzhoum @abdulfatir @canerturkmen @LennartPurucker @abhishek-iitmadras @adibiasio @rsj123 @nathanaelbosch @cheungdaven @lostella @zkalson @rey-allan @echowve @xiyuanzh
New Contributors
@nathanaelbosch made their first contribution in https://github.com/autogluon/autogluon/pull/4366
@adibiasio made their first contribution in https://github.com/autogluon/autogluon/pull/4391
@abdulfatir made their first contribution in https://github.com/autogluon/autogluon/pull/4608
@echowve made their first contribution in https://github.com/autogluon/autogluon/pull/4667
@abhishek-iitmadras made their first contribution in https://github.com/autogluon/autogluon/pull/4685
@xiyuanzh made their first contribution in https://github.com/autogluon/autogluon/pull/4694
v1.1.1
Version 1.1.1
We’re happy to announce the AutoGluon 1.1.1 release.
AutoGluon 1.1.1 contains bug fixes and logging improvements for Tabular, TimeSeries, and Multimodal modules, as well as support for PyTorch 2.2 and 2.3.
Join the community:
Get the latest updates:
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.1.1.
This release contains 52 commits from 10 contributors!
General
Add support for PyTorch 2.2. @prateekdesai04 (#4123)
Tabular
Note: Trying to load a TabularPredictor with a FastAI model trained on a previous AutoGluon release will raise an exception when calling predict due to a fix in the model-interals.pkl path. Please ensure matching versions.
Fix deadlock when
num_gpus>0and dynamic_stacking is enabled. @Innixma (#4208)Improve decision threshold calibration. @Innixma (#4136, #4137)
Fix regression metrics (other than RMSE and MSE) being calculated incorrectly for LightGBM early stopping. @Innixma (#4174)
Fix custom multiclass metrics being calculated incorrectly for LightGBM early stopping. @Innixma (#4250)
Fix HPO crashing with NN_TORCH and FASTAI models. @Innixma (#4232)
Disable sklearnex for linear models due to observed performance degradation. @Innixma (#4223)
Improve sklearnex logging verbosity in Kaggle. @Innixma (#4216)
Add AsTypeFeatureGenerator detailed exception logging. @Innixma (#4251, #4252)
TimeSeries
Ensure prediction_length is stored as an integer. @shchur (#4160)
Fix tabular model preprocessing failure edge-case. @shchur (#4175)
Fix loading of Tabular models failure if predictor moved to a different directory. @shchur (#4171)
Fix cached predictions error when predictor saved on-top of an existing predictor. @shchur (#4202)
Fix off-by-one bug in Chronos inference. @canerturkmen (#4205)
Use correct target and quantile_levels in fallback model for MLForecast. @shchur (#4230)
Multimodal
Fix bug in CLIP’s image feature normalization. @Harry-zzh (#4114)
Fix bug in text augmentation. @Harry-zzh (#4115)
Modify default fine-tuning tricks. @Harry-zzh (#4166)
Add PyTorch version warning for object detection. @FANGAreNotGnu (#4217)
Docs and CI
Add competition solutions to
AWESOME.md. @Innixma @shchur (#4122, #4163, #4245)Fix PDF classification tutorial. @zhiqiangdon (#4127)
Add AutoMM paper citation. @zhiqiangdon (#4154)
Add pickle load warning in all modules and tutorials. @shchur (#4243)
Various minor doc and test fixes and improvements. @tonyhoo @shchur @lovvge @Innixma @suzhoum (#4113, #4176, #4225, #4233, #4235, #4249, #4266)
Contributors
Full Contributor List (ordered by # of commits):
@Innixma @shchur @Harry-zzh @suzhoum @zhiqiangdon @lovvge @rey-allan @prateekdesai04 @canerturkmen @FANGAreNotGnu
New Contributors
@lovvge made their first contribution in https://github.com/autogluon/autogluon/commit/57a15fcfbbbc94514ff20ed2774cd447d9f4115f
@rey-allan made their first contribution in #4145
v1.1.0
Version 1.1.0
We’re happy to announce the AutoGluon 1.1 release.
AutoGluon 1.1 contains major improvements to the TimeSeries module, achieving a 60% win-rate vs AutoGluon 1.0 through the addition of Chronos, a pretrained model for time series forecasting, along with numerous other enhancements. The other modules have also been enhanced through new features such as Conv-LORA support and improved performance for large tabular datasets between 5 - 30 GB in size. For a full breakdown of AutoGluon 1.1 features, please refer to the feature spotlights and the itemized enhancements below.
Join the community:
Get the latest updates:
This release supports Python versions 3.8, 3.9, 3.10, and 3.11. Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.1.
This release contains 121 commits from 20 contributors!
Full Contributor List (ordered by # of commits):
@shchur @prateekdesai04 @Innixma @canerturkmen @zhiqiangdon @tonyhoo @AnirudhDagar @Harry-zzh @suzhoum @FANGAreNotGnu @nimasteryang @lostella @dassaswat @afmkt @npepin-hub @mglowacki100 @ddelange @LennartPurucker @taoyang1122 @gradientsky
Special thanks to @ddelange for their continued assistance with Python 3.11 support and Ray version upgrades!
Spotlight
AutoGluon Achieves Top Placements in ML Competitions!
AutoGluon has experienced wide-spread adoption on Kaggle since the AutoGluon 1.0 release. AutoGluon has been used in over 130 Kaggle notebooks and mentioned in over 100 discussion threads in the past 90 days! Most excitingly, AutoGluon has already been used to achieve top ranking placements in multiple competitions with thousands of competitors since the start of 2024:
Placement |
Competition |
Author |
Date |
AutoGluon Details |
Notes |
|---|---|---|---|---|---|
:3rd_place_medal: Rank 3/2303 (Top 0.1%) |
2024/03/31 |
v1.0, Tabular |
Kaggle Playground Series S4E3 |
||
:2nd_place_medal: Rank 2/93 (Top 2%) |
2024/03/21 |
v1.0, Tabular |
|||
:2nd_place_medal: Rank 2/1542 (Top 0.1%) |
2024/03/01 |
v1.0, Tabular |
|||
:2nd_place_medal: Rank 2/3746 (Top 0.1%) |
2024/02/29 |
v1.0, Tabular |
Kaggle Playground Series S4E2 |
||
:2nd_place_medal: Rank 2/3777 (Top 0.1%) |
2024/01/31 |
v1.0, Tabular |
Kaggle Playground Series S4E1 |
||
Rank 4/1718 (Top 0.2%) |
2024/01/01 |
v1.0, Tabular |
Kaggle Playground Series S3E26 |
We are thrilled that the data science community is leveraging AutoGluon as their go-to method to quickly and effectively achieve top-ranking ML solutions! For an up-to-date list of competition solutions using AutoGluon refer to our AWESOME.md, and don’t hesitate to let us know if you used AutoGluon in a competition!
Chronos, a pretrained model for time series forecasting
AutoGluon-TimeSeries now features Chronos, a family of forecasting models pretrained on large collections of open-source time series datasets that can generate accurate zero-shot predictions for new unseen data. Check out the new tutorial to learn how to use Chronos through the familiar TimeSeriesPredictor API.
General
Refactor project README & project Tagline @Innixma (#3861, #4066)
Add AWESOME.md competition results and other doc improvements. @Innixma (#4023)
PyTorch, CUDA, Lightning version upgrades. @prateekdesai04 @canerturkmen @zhiqiangdon (#3982, #3984, #3991, #4006)
Scikit-learn version upgrade. @prateekdesai04 (#3872, #3881, #3947)
Various dependency upgrades. @Innixma @tonyhoo (#4024, #4083)
TimeSeries
Highlights
AutoGluon 1.1 comes with numerous new features and improvements to the time series module. These include highly requested functionality such as feature importance, support for categorical covariates, ability to visualize forecasts, and enhancements to logging. The new release also comes with considerable improvements to forecast accuracy, achieving 60% win rate and 3% average error reduction compared to the previous AutoGluon version. These improvements are mostly attributed to the addition of Chronos, improved preprocessing logic, and native handling of missing values.
New Features
Add Chronos pretrained forecasting model (tutorial). @canerturkmen @shchur @lostella (#3978, #4013, #4052, #4055, #4056, #4061, #4092, #4098)
Measure the importance of features & covariates on the forecast accuracy with
TimeSeriesPredictor.feature_importance(). @canerturkmen (#4033, #4087)Native missing values support (no imputation required). @shchur (#3995, #4068, #4091)
Add support for categorical covariates. @shchur (#3874, #4037)
Improve inference speed by persisting models in memory with
TimeSeriesPredictor.persist(). @canerturkmen (#4005)Visualize forecasts with
TimeSeriesPredictor.plot(). @shchur (#3889)Add
RMSLEevaluation metric. @canerturkmen (#3938)Enable logging to file. @canerturkmen (#3877)
Add option to keep lightning logs after training with
keep_lightning_logshyperparameter. @shchur (#3937)
Fixes and Improvements
Automatically preprocess real-valued covariates @shchur (#4042, #4069)
Add option to skip model selection when only one model is trained. @shchur (#4002)
Ensure all metrics handle missing values in target @shchur (#3966)
Fix bug when loading a GPU trained model on a CPU machine @shchur (#3979)
Fix inconsistent random seed. @canerturkmen @shchur (#3934, #4099)
Fix leaderboard crash when no models trained. @shchur (#3849)
Add prototype TabRepo simulation artifact generation. @shchur (#3829)
Documentation improvements, hide deprecated methods. @shchur (#3764, #4054, #4098)
Minor fixes. @canerturkmen, @shchur, @AnirudhDagar (#4009, #4040, #4041, #4051, #4070, #4094)
AutoMM
Highlights
AutoMM 1.1 introduces the innovative Conv-LoRA, a parameter-efficient fine-tuning (PEFT) method stemming from our latest paper presented at ICLR 2024, titled “Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model”. Conv-LoRA is designed for fine-tuning the Segment Anything Model, exhibiting superior performance compared to previous PEFT approaches, such as LoRA and visual prompt tuning, across various semantic segmentation tasks in diverse domains including natural images, agriculture, remote sensing, and healthcare. Check out our Conv-LoRA example.
New Features
Added Conv-LoRA, a new parameter efficient fine-tuning method. @Harry-zzh @zhiqiangdon (#3933, #3999, #4007, #4022, #4025)
Added support for new column type: ‘image_base64_str’. @Harry-zzh @zhiqiangdon (#3867)
Added support for loading pre-trained weights in FT-Transformer. @taoyang1122 @zhiqiangdon (#3859)
Fixes and Improvements
Fixed bugs in semantic segmentation. @Harry-zzh (#3801, #3812)
Fixed bugs in PEFT methods. @Harry-zzh (#3840)
Accelerated object detection training by ~30% for the high_quality and best_quality presets. @FANGAreNotGnu (#3970)
Depreciated Grounding-DINO @FANGAreNotGnu (#3974)
Fixed lightning upgrade issues @zhiqiangdon (#3991)
Fixed using f1, f1_macro, f1_micro for binary classification in knowledge distillation. @nimasteryang (#3837)
Removed MyMuPDF from installation due to the license issue. Users need to install it by themselves to do document classification. @zhiqiangdon (#4093)
Tabular
Highlights
AutoGluon-Tabular 1.1 primarily focuses on bug fixes and stability improvements. In particular, we have greatly improved the runtime performance for large datasets between 5 - 30 GB in size through the usage of subsampling for decision threshold calibration and the weighted ensemble fitting to 1 million rows, maintaining the same quality while being far faster to execute. We also adjusted the default weighted ensemble iterations from 100 to 25, which will speedup all weighted ensemble fit times by 4x. We heavily refactored the fit_pseudolabel logic, and it should now achieve noticeably stronger results.
Fixes and Improvements
Fix return value in
predictor.fit_weighted_ensemble(refit_full=True). @Innixma (#1956)Enhance performance on large datasets through subsampling. @Innixma (#3977)
Refactor and enhance
.fit_pseudolabellogic. @Innixma (#3930)Fix crash in memory check during HPO for LightGBM, CatBoost, and XGBoost. @Innixma (#3931)
LightGBM version upgrade. @mglowacki100, @Innixma (#3427)
Fix memory-safe sub-fits being skipped if Ray is not initialized. @LennartPurucker (#3868)
Logging improvements. @AnirudhDagar (#3873)
Documentation improvements. @Innixma @AnirudhDagar (#2024, #3975, #3976, #3996)
Docs and CI
Add auto benchmarking report generation. @prateekdesai04 (#4038, #4039)
Fix hanging tabular unit tests. @prateekdesai04 (#4031)
Add package version comparison between CI runs @prateekdesai04 (#3962, #3968, #3972)
Update conf.py to reflect current year. @dassaswat (#3932)
Avoid redundant unit test runs. @prateekdesai04 (#3942)
Fix colab notebook links @prateekdesai04 (#3926)
v1.0.0
Version 1.0.0
Today is finally the day… AutoGluon 1.0 has arrived!! After over four years of development and 2061 commits from 111 contributors, we are excited to share with you the culmination of our efforts to create and democratize the most powerful, easy to use, and feature rich automated machine learning system in the world. AutoGluon 1.0 comes with transformative enhancements to predictive quality resulting from the combination of multiple novel ensembling innovations, spotlighted below. Besides performance enhancements, many other improvements have been made that are detailed in the individual module sections.
Note: Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.0.
This release supports Python versions 3.8, 3.9, 3.10, and 3.11.
This release contains 223 commits from 17 contributors!
Full Contributor List (ordered by # of commits):
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
Join the community:
Get the latest updates:
Spotlight
Tabular Performance Enhancements
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. To the best of our knowledge, AutoGluon 1.0 marks the largest leap forward in the state-of-the-art for tabular data since the original AutoGluon paper from March 2020. The enhancements come primarily from two features: Dynamic stacking to mitigate stacked overfitting, and a new learned model hyperparameters portfolio via Zeroshot-HPO, obtained from the newly released TabRepo ensemble simulation library. Together, they lead to a 75% win-rate compared to AutoGluon 0.8 with faster inference speed, lower disk usage, and higher stability.
AutoML Benchmark Results
OpenML released the official 2023 AutoML Benchmark results on November 16th, 2023. Their results show AutoGluon 0.8 as the state-of-the-art in AutoML systems across a wide variety of tasks: “Overall, in terms of model performance, AutoGluon consistently has the highest average rank in our benchmark.” We now showcase that AutoGluon 1.0 achieves far superior results even to AutoGluon 0.8!
Below is a comparison on the OpenML AutoML Benchmark across 1040 tasks. LightGBM, XGBoost, and CatBoost results were obtained via AutoGluon, and other methods are from the official AutoML Benchmark 2023 results. AutoGluon 1.0 has a 95%+ win-rate against traditional tabular models, including a 99% win-rate vs LightGBM and a 100% win-rate vs XGBoost. AutoGluon 1.0 has between an 82% and 94% win-rate against other AutoML systems. For all methods, AutoGluon is able to achieve >10% average loss improvement (Ex: Going from 90% accuracy to 91% accuracy is a 10% loss improvement). AutoGluon 1.0 achieves first place in 63% of tasks, with lightautoml having the second most at 12% (AutoGluon 0.8 previously took first place 48% of the time). AutoGluon 1.0 even achieves a 7.4% average loss improvement over AutoGluon 0.8!
Method |
AG Winrate |
AG Loss Improvement |
Rescaled Loss |
Rank |
Champion |
|---|---|---|---|---|---|
AutoGluon 1.0 (Best, 4h8c) |
- |
- |
0.04 |
1.95 |
63% |
lightautoml (2023, 4h8c) |
84% |
12.0% |
0.2 |
4.78 |
12% |
H2OAutoML (2023, 4h8c) |
94% |
10.8% |
0.17 |
4.98 |
1% |
FLAML (2023, 4h8c) |
86% |
16.7% |
0.23 |
5.29 |
5% |
MLJAR (2023, 4h8c) |
82% |
23.0% |
0.33 |
5.53 |
6% |
autosklearn (2023, 4h8c) |
91% |
12.5% |
0.22 |
6.07 |
4% |
GAMA (2023, 4h8c) |
86% |
15.4% |
0.28 |
6.13 |
5% |
CatBoost (2023, 4h8c) |
95% |
18.2% |
0.28 |
6.89 |
3% |
TPOT (2023, 4h8c) |
91% |
23.1% |
0.4 |
8.15 |
1% |
LightGBM (2023, 4h8c) |
99% |
23.6% |
0.4 |
8.95 |
0% |
XGBoost (2023, 4h8c) |
100% |
24.1% |
0.43 |
9.5 |
0% |
RandomForest (2023, 4h8c) |
97% |
25.1% |
0.53 |
9.78 |
1% |
Not only is AutoGluon more accurate in 1.0, it is also more stable thanks to our new usage of Ray subprocesses during low-memory training, resulting in 0 task failures on the AutoML Benchmark.
AutoGluon 1.0 is capable of achieving the fastest inference throughput of any AutoML system while still obtaining state-of-the-art results.
By specifying the infer_limit fit argument, users can trade off between accuracy and inference speed to meet their needs.
As seen in the below plot, AutoGluon 1.0 sets the Pareto Frontier for quality and inference throughput, achieving Pareto Dominance compared to all other AutoML systems. AutoGluon 1.0 High achieves superior performance to AutoGluon 0.8 Best with 8x faster inference and 8x less disk usage!
You can get more details on the results here.
We are excited to see what our users can accomplish with AutoGluon 1.0’s enhanced performance. As always, we will continue to improve AutoGluon in future releases to push the boundaries of AutoML forward for all.
AutoGluon Multimodal (AutoMM) Highlights in One Figure

AutoMM Uniqueness
AutoGluon Multimodal (AutoMM) distinguishes itself from other open-source AutoML toolboxes like AutosSklearn, LightAutoML, H2OAutoML, FLAML, MLJAR, TPOT and GAMA, which mainly focus on tabular data for classification or regression. AutoMM is designed for fine-tuning foundation models across multiple modalities—image, text, tabular, and document, either individually or combined. It offers extensive capabilities for tasks like classification, regression, object detection, named entity recognition, semantic matching, and image segmentation. In contrast, other AutoML systems generally have limited support for image or text, typically using a few pretrained models like EfficientNet or hand-crafted rules like bag-of-words as feature extractors. They often rely on traditional models or simple neural networks. AutoMM provides a uniquely comprehensive and versatile approach to AutoML, being the only AutoML system to support flexible multimodality and support for a wide range of tasks. A comparative table detailing support for various data modalities, tasks, and model types is provided below.
Data |
Task |
Model |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
image |
text |
tabular |
document |
any combination |
classification |
regression |
object detection |
semantic matching |
named entity recognition |
image segmentation |
traditional models |
deep learning models |
foundation models |
|
LightAutoML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
H2OAutoML |
✓ |
✓ |
✓ |
✓ |
||||||||||
FLAML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
MLJAR |
✓ |
✓ |
✓ |
✓ |
||||||||||
AutoSklearn |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||||
GAMA |
✓ |
✓ |
✓ |
✓ |
||||||||||
TPOT |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
||||||||
AutoMM |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
Special Thanks
We would like to conclude this spotlight by thanking Pieter Gijsbers, Sébastien Poirier, Erin LeDell, Joaquin Vanschoren, and the rest of the AutoML Benchmark authors for their key role in providing a shared and extensive benchmark to monitor the progress of the AutoML field. Their support has been invaluable to the AutoGluon project’s continued growth.
We would also like to thank Frank Hutter, who continues to be a leader within the AutoML field, for organizing the AutoML Conference in 2022 and 2023 to bring the community together to share ideas and align on a compelling vision.
Finally, we would like to thank Alex Smola and Mu Li for championing open source software at Amazon to make this project possible.
Additional Special Thanks
Special thanks to @LennartPurucker for leading development of dynamic stacking
Special thanks to @geoalgo for co-authoring TabRepo to enable Zeroshot-HPO
Special thanks to @ddelange for helping to add Python 3.11 support
Special thanks to @mglowacki100 for providing numerous feedback and suggestions
Special thanks to @Harry-zzh for contributing the new semantic segmentation problem type
General
Highlights
Other Enhancements
Dependency Updates
Upgraded torch to
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588)Upgraded numpy to
>=1.21,<1.29@prateekdesai04 (#3709)Upgraded Pandas to
>=2.0,<2.2@yinweisu @tonyhoo @shchur (#3498)Upgraded scikit-learn to
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498)Upgraded scipy to
>=1.5.4,<1.13@prateekdesai04 (#3709)Upgraded LightGBM to
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733)
Tabular
Highlights
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. Refer to the spotlight section above for more details!
New Features
Added
dynamic_stackingpredictor fit argument to mitigate stacked overfitting @LennartPurucker @Innixma (#3616)Added zeroshot-HPO learned portfolio as new hyperparameters for
best_qualityandhigh_qualitypresets. @Innixma @geoalgo (#3750)Added experimental scikit-learn API compatible wrappers to TabularPredictor. You can access them via
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor. @Innixma (#3769)Added enhanced FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
Added
predictor.simulation_artifact()to support integration with TabRepo @Innixma (#3555)
Performance Improvements
Enhanced FastAI model quality on regression via output clipping @LennartPurucker @Innixma (#3597)
Added Skip-connection Weighted Ensemble @LennartPurucker (#3598)
Fix memory leaks by using ray processes for sequential fitting @LennartPurucker (#3614)
Added dynamic parallel folds support to better utilize compute in low memory scenarios @yinweisu @Innixma (#3511)
Fixed linear model crashes during HPO and added search space for linear models @Innixma (#3571, #3720)
Other Enhancements
Multi-layer stacking now produces deterministic results @LennartPurucker (#3573)
Various model dependency updates @mglowacki100 (#3373)
Various code cleanup and logging improvements @Innixma (#3408, #3570, #3652, #3734)
Bug Fixes / Code and Doc Improvements
Fixed incorrect model memory usage calculation @Innixma (#3591)
Fixed
infer_limitbeing used incorrectly when bagging @Innixma (#3467)
AutoMM
AutoGluon Multimodal (AutoMM) is designed to simplify the fine-tuning of foundation models for downstream applications with just three lines of code. It seamlessly integrates with popular model zoos such as HuggingFace Transformers, TIMM, and MMDetection, providing support for a diverse range of data modalities, including image, text, tabular, and document data, whether used individually or in combination.
New Features
Semantic Segmentation
Introducing the new problem type
semantic_segmentation, for fine-tuning Segment Anything Model (SAM) with three lines of code. @Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728)Added comprehensive benchmarks from diverse domains, including natural images, agriculture, remote sensing, and healthcare.
Utilizing parameter-efficient finetuning (PEFT) LoRA, showcasing consistent superior performance over alternatives (VPT, adaptor, BitFit, SAM-adaptor, and LST) in the extensive benchmarks.
Added one semantic segmentation tutorial @zhiqiangdon (#3716).
Using SAM-ViT Huge by default (GPU memory > 25GB required).
Few Shot Classification
Added the new
few_shot_classificationproblem type for training few shot classifiers on images or texts. @zhiqiangdon (#3662, #3681, #3695)Leveraging image/text foundation models to extract features and train SVM classifiers.
Added one few shot classification tutorial. @zhiqiangdon (#3662)
Supported torch.compile for faster training (experimental and torch >=2.2 required) @zhiqiangdon (#3520).
Performance Improvements
Improved default image backbones, achieving a 100% win-rate on the image benchmark. @taoyang1122 (#3738)
Replaced MLPs with FT-Transformer as the default tabular backbones, resulting in a 67% win-rate on the text+tabular benchmark. @taoyang1122 (#3732)
Using both the improved default image backbones and FT-Transformer achieves a 62% win-rate on the text+tabular+image benchmark. @taoyang1122 (#3732, #3738)
Stability Enhancements
Enabled rigorous multi-GPU CI testing. @prateekdesai04 (#3566)
Fixed multi-GPU issues. @FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
Enhanced Usability
Supported custom evaluation metrics, which allows defining custom metric object and passing it to the
eval_metricargument. @taoyang1122 (#3548)Supported multi-GPU training in notebooks (experimental). @zhiqiangdon (#3484)
Improved logging with system info. @zhiqiangdon (#3735)
Improved Scalability
The introduction of the new learner class design facilitates easier support for new tasks and data modalities within AutoMM, enhancing overall scalability. @zhiqiangdon (#3650, #3685, #3735)
Other Enhancements
Added the option
hf_text.use_fastfor customizing fast tokenizer usage inhf_textmodels. @zhiqiangdon (#3379)Added fallback evaluation/validation metric, supporting
f1_macrof1_micro, andf1_weighted. @FANGAreNotGnu (#3696)Supported multi-GPU inference with the DDP strategy. @zhiqiangdon (#3445, #3451)
Upgraded torch to 2.0. @zhiqiangdon (#3404)
Upgraded lightning to 2.0 @zhiqiangdon (#3419)
Upgraded torchmetrics to 1.0 @zhiqiangdon (#3422)
Code Improvements
Refactored AutoMM with the learner class for improved design. @zhiqiangdon (#3650, #3685, #3735)
Refactored FT-Transformer. @taoyang1122 (#3621, #3700)
Refactored the visualizers of object detection, semantic segmentation, and NER. @zhiqiangdon (#3716)
Other code refactor/clean-up: @zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
Bug Fixes/Doc Improvements
Fixed one ONNX export issue. @AnirudhDagar (#3725)
Improved AutoMM introduction for clarity. @zhiqiangdon (#3388 #3726)
Improved AutoMM API doc. @zhiqiangdon @AnirudhDagar (#3772 #3777)
Other bug fixes @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
Other doc improvements @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
TimeSeries
Highlights
AutoGluon 1.0 features numerous usability and performance improvements to the TimeSeries module. These include automatic handling of missing data and irregular time series, new forecasting metrics (including custom metric support), advanced time series cross-validation options, and new forecasting models. AutoGluon produces state-of-the-art results in forecast accuracy, achieving 70%+ win rate compared to other popular forecasting frameworks.
New features
Support for custom forecasting metrics @shchur (#3760, #3602)
New forecasting metrics
WAPE,RMSSE,SQL+ improved documentation for metrics @melopeo @shchur (#3747, #3632, #3510, #3490)Improved robustness:
TimeSeriesPredictorcan now handle data with all pandas frequencies, irregular timestamps, or missing values represented byNaN@shchur (#3563, #3454)New models: intermittent demand forecasting models based on conformal prediction (
ADIDA,CrostonClassic,CrostonOptimized,CrostonSBA,IMAPA);WaveNetandNPTSfrom GluonTS; new baseline models (Average,SeasonalAverage,Zero) @canerturkmen @shchur (#3706, #3742, #3606, #3459)Advanced cross-validation options: avoid retraining the models for each validation window with
refit_every_n_windowsor adjust the step size between validation windows withval_step_sizearguments toTimeSeriesPredictor.fit@shchur (#3704, #3537)
Enhancements
Enable Ray Tune for deep-learning forecasting models @canerturkmen (#3705)
Support passing multiple evaluation metrics to
TimeSeriesPredictor.evaluate@shchur (#3646)Static features can now be passed directly to
TimeSeriesDataFrame.from_pathandTimeSeriesDataFrame.from_data_frameconstructors @shchur (#3635)
Performance improvements
Much more accurate forecasts at low time limits thanks to new presets and updated logic for splitting the training time across models @shchur (#3749, #3657, #3741)
Faster training and prediction + lower memory usage for
DirectTabularandRecursiveTabularmodels (#3740, #3620, #3559)Enable early stopping and improve inference speed for GluonTS models @shchur (#3575)
Reduce import time for
autogluon.timeseriesby moving import statements inside model classes (#3514)
Bug Fixes / Code and Doc Improvements
Add reference to the publication on AutoGluon-TimeSeries to README @shchur (#3482)
Align API of
TimeSeriesPredictorwithTabularPredictor, remove deprecated methods @shchur (#3714, #3655, #3396)General bug fixes and improvements @shchur(#3758, #3756, #3755, #3754, #3746, #3743, #3727, #3698, #3654, #3653, #3648, #3628, #3588, #3560, #3558, #3536, #3533, #3523, #3522, #3476, #3463)
EDA
The EDA module will be released at a later time, as it requires additional development effort before it is ready for 1.0.
We will make an announcement when EDA is ready for release. For now, please continue to use "autogluon.eda==0.8.2".
Deprecations
General
autogluon.core.spaceshas been deprecated. Please useautogluon.common.spacesinstead @Innixma (#3701)
Tabular
Tabular will log warnings if using the deprecated methods. Deprecated methods are planned to be removed in AutoGluon 1.2 @Innixma (#3701)
autogluon.tabular.TabularPredictorpredictor.get_model_names()->predictor.model_names()predictor.get_model_names_persisted()->predictor.model_names(persisted=True)predictor.compile_models()->predictor.compile()predictor.persist_models()->predictor.persist()predictor.unpersist_models()->predictor.unpersist()predictor.get_model_best()->predictor.model_bestpredictor.get_pred_from_proba()->predictor.predict_from_proba()predictor.get_oof_pred_proba()->predictor.predict_proba_oof()predictor.get_oof_pred()->predictor.predict_oof()predictor.get_model_full_dict()->predictor.model_refit_map()predictor.get_size_disk()->predictor.disk_usage()predictor.get_size_disk_per_file()->predictor.disk_usage_per_file()predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to FalseSame for
predictor.evaluate()andpredictor.evaluate_predictions()
AutoMM
Deprecated the
FewShotSVMPredictorin favor of the newfew_shot_classificationproblem type @zhiqiangdon (#3699)Deprecated the
AutoMMPredictorin favor ofMultiModalPredictor@zhiqiangdon (#3650)autogluon.multimodal.MultiModalPredictorDeprecated the
configargument in the fit API. @zhiqiangdon (#3679)Deprecated the
init_scratchandpipelinearguments in the init API @zhiqiangdon (#3668)
TimeSeries
autogluon.timeseries.TimeSeriesPredictorDeprecated argument
TimeSeriesPredictor(ignore_time_index: bool). Now, if the data contains irregular timestamps, either convert it to regular frequency withdata = data.convert_frequency(freq)or provide frequency when creating the predictor asTimeSeriesPredictor(freq=freq).predictor.evaluate()now returns a dictionary (previously returned a float)predictor.score()->predictor.evaluate()predictor.get_model_names()->predictor.model_names()predictor.get_model_best()->predictor.model_bestMetric
"mean_wQuantileLoss"has been renamed to"WQL"predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to FalseWhen setting
hyperparametersto a string inpredictor.fit(), supported values are now"default","light"and"very_light"
autogluon.timeseries.TimeSeriesDataFramedf.to_regular_index()->df.convert_frequency()Deprecated method
df.get_reindexed_view(). Please see deprecation notes forignore_time_indexunderTimeSeriesPredictorabove for information on how to deal with irregular timestamps
Models
All models based on MXNet (
DeepARMXNet,MQCNNMXNet,MQRNNMXNet,SimpleFeedForwardMXNet,TemporalFusionTransformerMXNet,TransformerMXNet) have been removedStatistical models from Statmodels (
ARIMA,Theta,ETS) have been replaced by their counterparts from StatsForecast (#3513). Note that these models now have different hyperparameter names.DirectTabularis now implemented usingmlforecastbackend (same asRecursiveTabular), most hyperparameter names for the model have changed.
autogluon.timeseries.TimeSeriesEvaluatorhas been deprecated. Please use metrics available inautogluon.timeseries.metricsinstead.autogluon.timeseries.splitter.MultiWindowSplitterandautogluon.timeseries.splitter.LastWindowSplitterhave been deprecated. Please usenum_val_windowsandval_step_sizearguments toTimeSeriesPredictor.fitinstead (alternatively, useautogluon.timeseries.splitter.ExpandingWindowSplitter).
Papers
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
We have published a paper on AutoGluon-TimeSeries at AutoML Conference 2023 (Paper Link, YouTube Video). In the paper, we benchmarked AutoGluon and popular open-source forecasting frameworks (including DeepAR, TFT, AutoARIMA, AutoETS, AutoPyTorch). AutoGluon produces SOTA results in point and probabilistic forecasting, and even achieves 65% win rate against the best-in-hindsight combination of models.
TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications
We have published a paper on Tabular Zeroshot-HPO ensembling simulation to arXiv (Paper Link, GitHub). This paper is key to achieving the performance improvements seen in AutoGluon 1.0, and we plan to continue to develop the code-base to support future enhancements.
XTab: Cross-table Pretraining for Tabular Transformers
We have published a paper on tabular Transformer pre-training at ICML 2023 (Paper Link, GitHub). In the paper we demonstrate state-of-the-art performance for tabular deep learning models, including being able to match the performance of XGBoost and LightGBM models. While the pre-trained transformer is not yet incorporated into AutoGluon, we plan to integrate it in a future release.
Learning Multimodal Data Augmentation in Feature Space
Our paper on learning multimodal data augmentation was accepted at ICLR 2023 (Paper Link, GitHub). This paper introduces a plug-and-play module to learn multimodal data augmentation in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that it can (1) improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data. This work is not yet incorporated into AutoGluon, but we plan to integrate it in a future release.
Data Augmentation for Object Detection via Controllable Diffusion Models
Our paper on generative object detection data augmentation has been accepted at WACV 2024 (Paper and GitHub link will be available soon). This paper proposes a data augmentation pipeline based on controllable diffusion models and CLIP, with visual prior generation to guide the generation and post-filtering by category-calibrated CLIP scores to control its quality. We demonstrate that the performance improves across various tasks and settings when using our augmentation pipeline with different detectors. Although diffusion models are currently not integrated into AutoGluon, we plan to incorporate the data augmentation techniques in a future release.
Adapting Image Foundation Models for Video Understanding
We have published a paper on how to efficiently adapt image foundation models for video understanding at ICLR 2023 (Paper Link, GitHub). This paper introduces spatial adaptation, temporal adaptation and joint adaptation to gradually equip a frozen image model with spatiotemporal reasoning capability. The proposed method achieves competitive or even better performance than traditional full finetuning while largely saving the training cost of large foundation models.
v0.8.3
Version 0.8.3
v0.8.3 is a patch release to address security vulnerabilities.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.8.2…v0.8.3
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
v0.8.2
Version 0.8.2
v0.8.2 is a hot-fix release to pin pydantic version to avoid crashing during HPO
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.8.1…v0.8.2
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
codespell: action, config + some typos fixed @yarikoptic @yinweisu (#3323)
Unpin sentencepiece @zhiqiangdon (#3368)
Pin pydantic @yinweisu (3370)
v0.8.1
Version 0.8.1
v0.8.1 is a bug fix release.
As always, only load previously trained models using the same version of AutoGluon that they were originally trained on. Loading models trained in different versions of AutoGluon is not supported.
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/v0.8.0…v0.8.1
This version supports Python versions 3.8, 3.9, and 3.10.
Changes
Documentation improvements
Bug Fixes / General Improvements
Move PyMuPDF to optional @Innixma @zhiqiangdon (#3331)
Update persist_models max_memory 0.1 -> 0.4 @Innixma (#3338)
Remove fairscale @zhiqiangdon (#3342)
Fix
DirectTabularmodel failing for some metrics; hide warnings produced byAutoARIMA@shchur (#3350)Reduce per gpu batch size for AutoMM high_quality_hpo to avoid out of memory error for some corner cases @zhiqiangdon (#3360)
Fix HPO crash by setting reuse_actor to False @yinweisu (#3361)
v0.8.0
Version 0.8.0
We’re happy to announce the AutoGluon 0.8 release.
Note: Loading models trained in different versions of AutoGluon is not supported.
This release contains 196 commits from 20 contributors!
See the full commit change-log here: https://github.com/autogluon/autogluon/compare/0.7.0…0.8.0
Special thanks to @geoalgo for the joint work in generating the experimental tabular Zeroshot-HPO portfolio this release!
Full Contributor List (ordered by # of commits):
@shchur, @Innixma, @yinweisu, @gradientsky, @FANGAreNotGnu, @zhiqiangdon, @gidler, @liangfu, @tonyhoo, @cheungdaven, @cnpgs, @giswqs, @suzhoum, @yongxinw, @isunli, @jjaeyeon, @xiaochenbin9527, @yzhliu, @jsharpna, @sxjscience
AutoGluon 0.8 supports Python versions 3.8, 3.9, and 3.10.
Changes
Highlights
AutoGluon TimeSeries introduced several major improvements, including new models, upgraded presets that lead to better forecast accuracy, and optimizations that speed up training & inference.
AutoGluon Tabular now supports calibrating the decision threshold in binary classification (API), leading to massive improvements in metrics such as
f1andbalanced_accuracy. It is not uncommon to seef1scores improve from0.70to0.73as an example. We strongly encourage all users who are using these metrics to try out the new decision threshold calibration logic.AutoGluon MultiModal introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection.
AutoGluon MultiModal upgraded the presets for object detection, now offering
medium_quality,high_quality, andbest_qualityoptions. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset.AutoGluon Tabular has added an experimental Zeroshot HPO config which performs well on small datasets <10000 rows when at least an hour of training time is provided (~60% win-rate vs
best_quality). To try it out, specifypresets="experimental_zeroshot_hpo_hybrid"when callingfit().AutoGluon EDA added support for Anomaly Detection and Partial Dependence Plots.
AutoGluon Tabular has added experimental support for TabPFN, a pre-trained tabular transformer model. Try it out via
pip install autogluon.tabular[all,tabpfn](hyperparameter key is “TABPFN”)!
General
General doc improvements @tonyhoo @Innixma @yinweisu @gidler @cnpgs @isunli @giswqs (#2940, #2953, #2963, #3007, #3027, #3059, #3068, #3083, #3128, #3129, #3130, #3147, #3174, #3187, #3256, #3258, #3280, #3306, #3307, #3311, #3313)
General code fixes and improvements @yinweisu @Innixma (#2921, #3078, #3113, #3140, #3206)
CI improvements @yinweisu @gidler @yzhliu @liangfu @gradientsky (#2965, #3008, #3013, #3020, #3046, #3053, #3108, #3135, #3159, #3283, #3185)
Update namespace packages for PEP420 compatibility @gradientsky (#3228)
Multimodal
AutoGluon MultiModal (also known as AutoMM) introduces two new features: 1) PDF document classification, and 2) Open Vocabulary Object Detection. Additionally, we have upgraded the presets for object detection, now offering medium_quality, high_quality, and best_quality options. The empirical results demonstrate significant ~20% relative improvements in the mAP (mean Average Precision) metric, using the same preset.
New Features
PDF Document Classification. See tutorial @cheungdaven (#2864, #3043)
Open Vocabulary Object Detection. See tutorial @FANGAreNotGnu (#3164)
Performance Improvements
Upgrade the detection engine from mmdet 2.x to mmdet 3.x, and upgrade our presets @FANGAreNotGnu (#3262)
medium_quality: yolo-s -> yolox-lhigh_quality: yolox-l -> DINO-Res50best_quality: yolox-x -> DINO-Swin_l
Speedup fusion model training with deepspeed strategy. @liangfu (#2932)
Enable detection backbone freezing to boost finetuning speed and save GPU usage @FANGAreNotGnu (#3220)
Other Enhancements
Support passing data path to the fit() API @zhiqiangdon (#3006)
Upgrade TIMM to the latest v0.9.* @zhiqiangdon (#3282)
Support xywh output for object detection @FANGAreNotGnu (#2948)
Fusion model inference acceleration with TensorRT @liangfu (#2836, #2987)
Support customizing advanced image data augmentation. Users can pass a list of torchvision transform objects as image augmentation. @zhiqiangdon (#3022)
Add yoloxm and yoloxtiny @FangAreNotGnu (#3038)
Add MultiImageMix Dataset for Object Detection @FangAreNotGnu (#3094)
Support loading specific checkpoints. Users can load the intermediate checkpoints other than model.ckpt and last.ckpt. @zhiqiangdon (#3244)
Add some predictor properties for model statistics @zhiqiangdon (#3289)
trainable_parametersreturns the number of trainable parameters.total_parametersreturns the number of total parameters.model_sizereturns the model size measured by megabytes.
Bug Fixes / Code and Doc Improvements
General bug fixes and improvements @zhiqiangdon @liangfu @cheungdaven @xiaochenbin9527 @Innixma @FANGAreNotGnu @gradientsky @yinweisu @yongxinw (#2939, #2989, #2983, #2998, #3001, #3004, #3006, #3025, #3026, #3048, #3055, #3064, #3070, #3081, #3090, #3103, #3106, #3119, #3155, #3158, #3167, #3180, #3188, #3222, #3261, #3266, #3277, #3279, #3261, #3267)
Refactor inferring problem type and output shape @zhiqiangdon (#3227)
Log GPU info including GPU total memory, free memory, GPU card name, and CUDA version during training @zhiqaingdon (#3291)
Tabular
New Features
Added
calibrate_decision_threshold(tutorial), which allows to optimize a given metric’s decision threshold for predictions to strongly enhance the metric score. @Innixma (#3298)We’ve added an experimental Zeroshot HPO config, which performs well on small datasets <10000 rows when at least an hour of training time is provided. To try it out, specify
presets="experimental_zeroshot_hpo_hybrid"when callingfit()@Innixma @geoalgo (#3312)The TabPFN model is now supported as an experimental model. TabPFN is a viable model option when inference speed is not a concern, and the number of rows of training data is less than 10,000. Try it out via
pip install autogluon.tabular[all,tabpfn]! @Innixma (#3270)Backend support for distributed training, which will be available with the next Cloud module release. @yinweisu (#3054, #3110, #3115, #3131, #3142, #3179, #3216)
Performance Improvements
Other Enhancements
Add quantile regression support for CatBoost @shchur (#3165)
Add enable_categorical=True support to XGBoost @Innixma (#3286)
Bug Fixes / Code and Doc Improvements
Cross-OS loading of a fit TabularPredictor should now work properly @yinweisu @Innixma
General bug fixes and improvements @Innixma @cnpgs @shchur @yinweisu @gradientsky (#2865, #2936, #2990, #3045, #3060, #3069, #3148, #3182, #3199, #3226, #3257, #3259, #3268, #3269, #3287, #3288, #3285, #3293, #3294, #3302)
Move interpretable logic to InterpretableTabularPredictor @Innixma (#2981)
TimeSeries
In v0.8 we introduce several major improvements to the Time Series module, including new models, upgraded presets that lead to better forecast accuracy, and optimizations that speed up training & inference.
Highlights
New models:
PatchTSTandDLinearfrom GluonTS, andRecursiveTabularbased on integration with themlforecastlibrary @shchur (#3177, #3184, #3230)Improved accuracy and reduced overall training time thanks to updated presets @shchur (#3281, #3120)
3-6x faster training and inference for
AutoARIMA,AutoETS,Theta,DirectTabular,WeightedEnsemblemodels @shchur (#3062, #3214, #3252)
New Features
Dramatically faster repeated calls to
predict(),leaderboard()andevaluate()thanks to prediction caching @shchur (#3237)Reduce overfitting by using multiple validation windows with the
num_val_windowsargument tofit()@shchur (#3080)Exclude certain models from presets with the
excluded_model_typesargument tofit()@shchur (#3231)New method
refit_full()that refits models on combined train and validation data @shchur (#3157)Train multiple configurations of the same model by providing lists in the
hyperparametersargument @shchur (#3183)Time limit set by
time_limitis now respected by all models @shchur (#3214)
Enhancements
Improvements to the
DirectTabularmodel (previously calledAutoGluonTabular): faster featurization, trained as a quantile regression model ifeval_metricis set to"mean_wQuantileLoss"@shchur (#2973, #3211)Use correct seasonal period when computing the MASE metric @shchur (#2970)
Check the AutoGluon version when loading
TimeSeriesPredictorfrom disk @shchur (#3233)
Minor Improvements / Documentation / Bug Fixes
Update documentation and tutorials @shchur (#2960, #2964, #3296, #3297)
General bug fixes and improvements @shchur (#2977, #3058, #3066, #3160, #3193, #3202, #3236, #3255, #3275, #3290)
Exploratory Data Analysis (EDA) tools
In 0.8 we introduce a few new tools to help with data exploration and feature engineering:
Anomaly Detection @gradientsky (#3124, #3137) - helps to identify unusual patterns or behaviors in data that deviate significantly from the norm. It’s best used when finding outliers, rare events, or suspicious activities that could indicate fraud, defects, or system failures. Check the Anomaly Detection Tutorial to explore the functionality.
Partial Dependence Plots @gradientsky (#3071, #3079) - visualize the relationship between a feature and the model’s output for each individual instance in the dataset. Two-way variant can visualize potential interactions between any two features. Please see this tutorial for more detail: Using Interaction Charts To Learn Information About the Data
Bug Fixes / Code and Doc Improvements
Switch regression analysis in
quick_fitto use residuals plot @gradientsky (#3039)Added
explain_rowsmethod toautogluon.eda.auto- Kernel SHAP visualization @gradientsky (#3014)General improvements and fixes @gradientsky (#2991, #3056, #3102, #3107, #3138)