
Predicting Columns in a Table - In Depth¶
Tip: If you are new to AutoGluon, review Predicting Columns in a Table - Quick Start to learn the basics of the AutoGluon API.
This tutorial describes how you can exert greater control when using
AutoGluon’s fit() or predict(). Recall that to maximize
predictive performance, you should always first try fit() with all
default arguments except eval_metric and presets, before you
experiment with other arguments covered in this in-depth tutorial like
hyperparameter_tune, hyperparameters, stack_ensemble_levels,
num_bagging_folds, num_bagging_sets, etc.
Using the same census data table as in the Predicting Columns in a Table - Quick Start
tutorial, we’ll now predict the occupation of an individual - a
multiclass classification problem. Start by importing AutoGluon,
specifying TabularPrediction as the task, and loading the data.
import autogluon as ag
from autogluon import TabularPrediction as task
import numpy as np
train_data = task.Dataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
subsample_size = 500 # subsample subset of data for faster demo, try setting this to much larger values
train_data = train_data.sample(n=subsample_size, random_state=0)
print(train_data.head())
label_column = 'occupation'
print("Summary of occupation column: \n", train_data['occupation'].describe())
new_data = task.Dataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
test_data = new_data[5000:].copy() # this should be separate data in your applications
y_test = test_data[label_column]
test_data_nolabel = test_data.drop(labels=[label_column], axis=1) # delete label column
val_data = new_data[:5000]
metric = 'accuracy' # we specify eval-metric just for demo (unnecessary as it's the default)
Loaded data from: https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv | Columns = 15 / 15 | Rows = 39073 -> 39073
Loaded data from: https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv | Columns = 15 / 15 | Rows = 9769 -> 9769
age workclass fnlwgt education education-num 6118 51 Private 39264 Some-college 10
23204 58 Private 51662 10th 6
29590 40 Private 326310 Some-college 10
18116 37 Private 222450 HS-grad 9
33964 62 Private 109190 Bachelors 13
marital-status occupation relationship race sex 6118 Married-civ-spouse Exec-managerial Wife White Female
23204 Married-civ-spouse Other-service Wife White Female
29590 Married-civ-spouse Craft-repair Husband White Male
18116 Never-married Sales Not-in-family White Male
33964 Married-civ-spouse Exec-managerial Husband White Male
capital-gain capital-loss hours-per-week native-country class
6118 0 0 40 United-States >50K
23204 0 0 8 United-States <=50K
29590 0 0 44 United-States <=50K
18116 0 2339 40 El-Salvador <=50K
33964 15024 0 40 United-States >50K
Summary of occupation column:
count 500
unique 15
top Exec-managerial
freq 77
Name: occupation, dtype: object
Specifying hyperparameters and tuning them¶
We first demonstrate hyperparameter-tuning and how you can provide your own validation dataset that AutoGluon internally relies on to: tune hyperparameters, early-stop iterative training, and construct model ensembles. One reason you may specify validation data is when future test data will stem from a different distribution than training data (and your specified validation data is more representative of the future data that will likely be encountered).
If you don’t have a strong reason to provide your own validation
dataset, we recommend you omit the tuning_data argument. This lets
AutoGluon automatically select validation data from your provided
training set (it uses smart strategies such as stratified sampling). For
greater control, you can specify the holdout_frac argument to tell
AutoGluon what fraction of the provided training data to hold out for
validation.
Caution: Since AutoGluon tunes internal knobs based on this
validation data, performance estimates reported on this data may be
over-optimistic. For unbiased performance estimates, you should always
call predict() on a separate dataset (that was never passed to
fit()), as we did in the previous Quick-Start tutorial. We also
emphasize that most options specified in this tutorial are chosen to
minimize runtime for the purposes of demonstration and you should select
more reasonable values in order to obtain high-quality models.
fit() trains neural networks and various types of tree ensembles by
default. You can specify various hyperparameter values for each type of
model. For each hyperparameter, you can either specify a single fixed
value, or a search space of values to consider during hyperparameter
optimization. Hyperparameters which you do not specify are left at
default settings chosen automatically by AutoGluon, which may be fixed
values or search spaces.
hp_tune = True # whether or not to do hyperparameter optimization
nn_options = { # specifies non-default hyperparameter values for neural network models
'num_epochs': 10, # number of training epochs (controls training time of NN models)
'learning_rate': ag.space.Real(1e-4, 1e-2, default=5e-4, log=True), # learning rate used in training (real-valued hyperparameter searched on log-scale)
'activation': ag.space.Categorical('relu', 'softrelu', 'tanh'), # activation function used in NN (categorical hyperparameter, default = first entry)
'layers': ag.space.Categorical([100],[1000],[200,100],[300,200,100]), # each choice for categorical hyperparameter 'layers' corresponds to list of sizes for each NN layer to use
'dropout_prob': ag.space.Real(0.0, 0.5, default=0.1), # dropout probability (real-valued hyperparameter)
}
gbm_options = { # specifies non-default hyperparameter values for lightGBM gradient boosted trees
'num_boost_round': 100, # number of boosting rounds (controls training time of GBM models)
'num_leaves': ag.space.Int(lower=26, upper=66, default=36), # number of leaves in trees (integer hyperparameter)
}
hyperparameters = { # hyperparameters of each model type
'GBM': gbm_options,
'NN': nn_options, # NOTE: comment this line out if you get errors on Mac OSX
} # When these keys are missing from hyperparameters dict, no models of that type are trained
time_limits = 2*60 # train various models for ~2 min
num_trials = 5 # try at most 3 different hyperparameter configurations for each type of model
search_strategy = 'skopt' # to tune hyperparameters using SKopt Bayesian optimization routine
predictor = task.fit(train_data=train_data, tuning_data=val_data, label=label_column,
time_limits=time_limits, eval_metric=metric, num_trials=num_trials,
hyperparameter_tune=hp_tune, hyperparameters=hyperparameters,
search_strategy=search_strategy)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Warning: hyperparameter_tune=True is currently experimental and may cause the process to hang. Setting auto_stack=True instead is recommended to achieve maximum quality models.
No output_directory specified. Models will be saved in: AutogluonModels/ag-20201208_200648/
Beginning AutoGluon training ... Time limit = 120s
AutoGluon will save models to AutogluonModels/ag-20201208_200648/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Tuning Data Rows: 5000
Tuning Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21960.61 MB
Train Data (Original) Memory Usage: 3.11 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.1s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.3 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.08s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
Starting Experiments
Num of Finished Tasks is 0
Num of Pending Tasks is 5
HBox(children=(HTML(value=''), FloatProgress(value=0.0, max=5.0), HTML(value='')))
Time out (secs) is 54.0
Please either provide filename or allow plot in get_training_curves
0.1714 = Validation accuracy score
5.35s = Training runtime
0.48s = Validation runtime
0.2342 = Validation accuracy score
5.43s = Training runtime
0.36s = Validation runtime
0.219 = Validation accuracy score
5.49s = Training runtime
0.46s = Validation runtime
0.26 = Validation accuracy score
5.64s = Training runtime
0.46s = Validation runtime
0.1886 = Validation accuracy score
5.49s = Training runtime
0.5s = Validation runtime
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/lightgbm/basic.py:1286: UserWarning: Overriding the parameters from Reference Dataset.
warnings.warn('Overriding the parameters from Reference Dataset.')
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/lightgbm/basic.py:1098: UserWarning: categorical_column in param dict is overridden.
warnings.warn('{} in param dict is overridden.'.format(cat_alias))
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
Starting Experiments
Num of Finished Tasks is 0
Num of Pending Tasks is 5
HBox(children=(HTML(value=''), FloatProgress(value=0.0, max=5.0), HTML(value='')))
Time out (secs) is 54.0
0.3008 = Validation accuracy score
6.24s = Training runtime
0.03s = Validation runtime
0.3098 = Validation accuracy score
4.83s = Training runtime
0.04s = Validation runtime
0.301 = Validation accuracy score
8.74s = Training runtime
0.04s = Validation runtime
0.2953 = Validation accuracy score
11.47s = Training runtime
0.09s = Validation runtime
0.259 = Validation accuracy score
9.65s = Training runtime
0.03s = Validation runtime
Fitting model: weighted_ensemble_k0_l1 ... Training model for up to 119.92s of the 42.8s of remaining time.
0.3195 = Validation accuracy score
1.33s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 78.56s ...
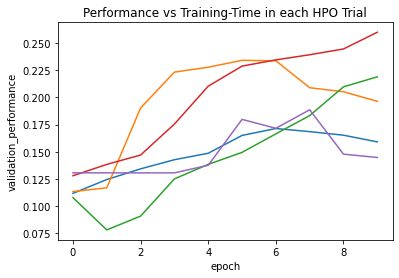
We again demonstrate how to use the trained models to predict on the test data.
y_pred = predictor.predict(test_data_nolabel)
print("Predictions: ", list(y_pred)[:5])
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=False)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code) Evaluation: accuracy on test data: 0.29419165443489204
Predictions: [' Exec-managerial', ' Craft-repair', ' Craft-repair', ' Other-service', ' Craft-repair']
Use the following to view a summary of what happened during fit. Now this command will show details of the hyperparameter-tuning process for each type of model:
results = predictor.fit_summary()
* Summary of fit() *
Estimated performance of each model:
model score_val pred_time_val fit_time pred_time_val_marginal fit_time_marginal stack_level can_infer fit_order
0 weighted_ensemble_k0_l1 0.319459 2.420563 53.775417 0.001138 1.330252 1 True 11
1 LightGBMClassifier/trial_6 0.309822 0.035449 4.831587 0.035449 4.831587 0 True 7
2 LightGBMClassifier/trial_7 0.301005 0.040429 8.738077 0.040429 8.738077 0 True 8
3 LightGBMClassifier/trial_5 0.300800 0.027617 6.236756 0.027617 6.236756 0 True 6
4 LightGBMClassifier/trial_8 0.295263 0.087132 11.474329 0.087132 11.474329 0 True 9
5 NeuralNetClassifier/trial_3 0.259996 0.459335 5.640950 0.459335 5.640950 0 True 4
6 LightGBMClassifier/trial_9 0.258971 0.033328 9.648161 0.033328 9.648161 0 True 10
7 NeuralNetClassifier/trial_1 0.234160 0.355495 5.434115 0.355495 5.434115 0 True 2
8 NeuralNetClassifier/trial_2 0.218987 0.460589 5.486303 0.460589 5.486303 0 True 3
9 NeuralNetClassifier/trial_4 0.188641 0.496177 5.492877 0.496177 5.492877 0 True 5
10 NeuralNetClassifier/trial_0 0.171417 0.484819 5.346929 0.484819 5.346929 0 True 1
Number of models trained: 11
Types of models trained:
{'TabularNeuralNetModel', 'LGBModel', 'WeightedEnsembleModel'}
Bagging used: False
Stack-ensembling used: False
Hyperparameter-tuning used: True
User-specified hyperparameters:
{'default': {'GBM': [{'num_boost_round': 100, 'num_leaves': Int: lower=26, upper=66}], 'NN': [{'num_epochs': 10, 'learning_rate': Real: lower=0.0001, upper=0.01, 'activation': Categorical['relu', 'softrelu', 'tanh'], 'layers': Categorical[[100], [1000], [200, 100], [300, 200, 100]], 'dropout_prob': Real: lower=0.0, upper=0.5}]}}
Feature Metadata (Processed):
(raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
Plot summary of models saved to file: AutogluonModels/ag-20201208_200648/SummaryOfModels.html
Plot summary of models saved to file: AutogluonModels/ag-20201208_200648/NeuralNetClassifier_HPOmodelsummary.html
Plot summary of models saved to file: NeuralNetClassifier_HPOmodelsummary.html
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
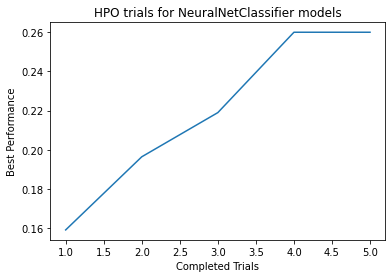
Plot of HPO performance saved to file: AutogluonModels/ag-20201208_200648/NeuralNetClassifier_HPOperformanceVStrials.png
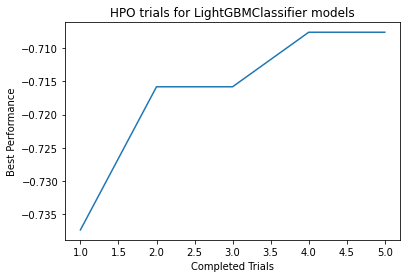
Plot summary of models saved to file: AutogluonModels/ag-20201208_200648/LightGBMClassifier_HPOmodelsummary.html
Plot summary of models saved to file: LightGBMClassifier_HPOmodelsummary.html
Plot of HPO performance saved to file: AutogluonModels/ag-20201208_200648/LightGBMClassifier_HPOperformanceVStrials.png
* Details of Hyperparameter optimization *
HPO for NeuralNetClassifier model: Num. configurations tried = 5, Time spent = 31.514182090759277s, Search strategy = skopt
Best hyperparameter-configuration (validation-performance: accuracy = 0.25999589911831045):
{'activation▁choice': 2, 'dropout_prob': 0.396902948100144, 'embedding_size_factor': 0.7285129088859379, 'layers▁choice': 1, 'learning_rate': 0.00017272817374902507, 'network_type▁choice': 0, 'use_batchnorm▁choice': 0, 'weight_decay': 2.6541384907083633e-09}
HPO for LightGBMClassifier model: Num. configurations tried = 5, Time spent = 41.77331829071045s, Search strategy = skopt
Best hyperparameter-configuration (validation-performance: accuracy = -0.7076071355341398):
{'feature_fraction': 0.7595536601939119, 'learning_rate': 0.02781872077974975, 'min_data_in_leaf': 9, 'num_leaves': 53}
* End of fit() summary *
In the above example, the predictive performance may be poor because we
specified very little training to ensure quick runtimes. You can call
fit() multiple times while modifying the above settings to better
understand how these choices affect performance outcomes. For example:
you can comment out the train_data.head command or increase
subsample_size to train using a larger dataset, increase the
num_epochs and num_boost_round hyperparameters, and increase the
time_limits (which you should do for all code in these tutorials).
To see more detailed output during the execution of fit(), you can
also pass in the argument: verbosity = 3.
Model ensembling with stacking/bagging¶
Beyond hyperparameter-tuning with a correctly-specified evaluation
metric, two other methods to boost predictive performance are bagging
and stack-ensembling. You’ll often
see performance improve if you specify num_bagging_folds = 5-10,
stack_ensemble_levels = 1-3 in the call to fit(), but this will
increase training times and memory/disk usage.
predictor = task.fit(train_data=train_data, label=label_column, eval_metric=metric,
num_bagging_folds=5, num_bagging_sets=1, stack_ensemble_levels=1,
hyperparameters = {'NN': {'num_epochs': 2}, 'GBM': {'num_boost_round': 20}} # last argument is just for quick demo here, omit it in real applications
)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
No output_directory specified. Models will be saved in: AutogluonModels/ag-20201208_200810/
Beginning AutoGluon training ...
AutoGluon will save models to AutogluonModels/ag-20201208_200810/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21815.66 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.0s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.07s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
Fitting model: NeuralNetClassifier_STACKER_l0 ...
0.1268 = Validation accuracy score
2.43s = Training runtime
0.16s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l0 ...
0.3129 = Validation accuracy score
4.08s = Training runtime
0.07s = Validation runtime
Fitting model: weighted_ensemble_k0_l1 ...
0.317 = Validation accuracy score
0.11s = Training runtime
0.0s = Validation runtime
Fitting model: NeuralNetClassifier_STACKER_l1 ...
0.1043 = Validation accuracy score
2.12s = Training runtime
0.21s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l1 ...
0.3149 = Validation accuracy score
4.8s = Training runtime
0.06s = Validation runtime
Fitting model: weighted_ensemble_k0_l2 ...
0.3149 = Validation accuracy score
0.11s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 14.36s ...
You should not provide tuning_data when stacking/bagging, and
instead provide all your available data as train_data (which
AutoGluon will split in more intellgent ways). num_bagging_sets
controls how many times the k-fold bagging process is repeated to
further reduce variance (increasing this may further boost accuracy but
will substantially increase training times, inference latency, and
memory/disk usage). Rather than manually searching for good
bagging/stacking values yourself, AutoGluon will automatically select
good values for you if you specify auto_stack instead:
output_directory = 'agModels-predictOccupation' # folder where to store trained models
predictor = task.fit(train_data=train_data, label=label_column, eval_metric=metric,
auto_stack=True, output_directory=output_directory,
hyperparameters={'NN': {'num_epochs': 2}, 'GBM': {'num_boost_round': 20}}, time_limits=30 # last 2 arguments are for quick demo, omit them in real applications
)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Beginning AutoGluon training ... Time limit = 30s
AutoGluon will save models to agModels-predictOccupation/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21733.77 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.0s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.07s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
Fitting model: NeuralNetClassifier_STACKER_l0 ... Training model for up to 29.93s of the 29.93s of remaining time.
0.0961 = Validation accuracy score
2.03s = Training runtime
0.17s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l0 ... Training model for up to 27.7s of the 27.7s of remaining time.
0.3129 = Validation accuracy score
4.11s = Training runtime
0.06s = Validation runtime
Repeating k-fold bagging: 2/20
Fitting model: NeuralNetClassifier_STACKER_l0 ... Training model for up to 23.5s of the 23.5s of remaining time.
0.1166 = Validation accuracy score
4.06s = Training runtime
0.32s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l0 ... Training model for up to 21.28s of the 21.28s of remaining time.
0.3047 = Validation accuracy score
8.26s = Training runtime
0.13s = Validation runtime
Repeating k-fold bagging: 3/20
Fitting model: NeuralNetClassifier_STACKER_l0 ... Training model for up to 17.05s of the 17.05s of remaining time.
0.1329 = Validation accuracy score
6.07s = Training runtime
0.48s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l0 ... Training model for up to 14.84s of the 14.84s of remaining time.
0.2986 = Validation accuracy score
12.35s = Training runtime
0.2s = Validation runtime
Repeating k-fold bagging: 4/20
Fitting model: NeuralNetClassifier_STACKER_l0 ... Training model for up to 10.65s of the 10.65s of remaining time.
0.1247 = Validation accuracy score
8.09s = Training runtime
0.64s = Validation runtime
Fitting model: LightGBMClassifier_STACKER_l0 ... Training model for up to 8.43s of the 8.43s of remaining time.
0.3067 = Validation accuracy score
16.38s = Training runtime
0.26s = Validation runtime
Completed 4/20 k-fold bagging repeats ...
Fitting model: weighted_ensemble_k0_l1 ... Training model for up to 29.93s of the 4.31s of remaining time.
0.3108 = Validation accuracy score
0.11s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 25.81s ...
Often stacking/bagging will produce superior accuracy than
hyperparameter-tuning, but you may try combining both techniques (note:
specifying presets='best_quality' in fit() simply sets
auto_stack = True).
Prediction options (inference)¶
Even if you’ve started a new Python session since last calling
fit(), you can still load a previously trained predictor from disk:
predictor = task.load(output_directory)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
Above output_directory is the same folder previously passed to
fit(), in which all the trained models have been saved. You can
train easily models on one machine and deploy them on another. Simply
copy the output_directory folder to the new machine and specify its
new path in task.load().
We can make a prediction on an individual example rather than a full dataset:
datapoint = test_data_nolabel.iloc[[0]] # Note: .iloc[0] won't work because it returns pandas Series instead of DataFrame
print(datapoint)
print(predictor.predict(datapoint))
age workclass fnlwgt education education-num marital-status 5000 49 Private 259087 Some-college 10 Divorced
relationship race sex capital-gain capital-loss 5000 Not-in-family White Female 0 0
hours-per-week native-country class
5000 40 United-States <=50K
[' Exec-managerial']
To output predicted class probabilities instead of predicted classes, you can use:
predictor.predict_proba(datapoint, as_pandas=True) # as_pandas shows which probability corresponds to which class
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
| ? | Adm-clerical | Armed-Forces | Craft-repair | Exec-managerial | Farming-fishing | Handlers-cleaners | Machine-op-inspct | Other-service | Priv-house-serv | Prof-specialty | Protective-serv | Sales | Tech-support | Transport-moving | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5000 | 0.050646 | 0.122795 | 0.0 | 0.119093 | 0.195809 | 0.04207 | 0.053171 | 0.061199 | 0.065746 | 0.0 | 0.083764 | 0.0 | 0.08861 | 0.040614 | 0.076483 |
By default, predict() and predict_proba() will utilize the model
that AutoGluon thinks is most accurate, which is usually an ensemble of
many individual models. Here’s how to see which model this is:
predictor.get_model_best()
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
'weighted_ensemble_k0_l1'
We can instead specify a particular model to use for predictions (e.g. to reduce inference latency). Note that a ‘model’ in AutoGluon may refer to for example a single Neural Network, a bagged ensemble of many Neural Network copies trained on different training/validation splits, a weighted ensemble that aggregates the predictions of many other models, or a stacker model that operates on predictions output by other models. This is akin to viewing a Random Forest as one ‘model’ when it is in fact an ensemble of many decision trees.
Before deciding which model to use, let’s evaluate all of the models AutoGluon has previously trained on our test data:
predictor.leaderboard(test_data, silent=True)
| model | score_test | score_val | pred_time_test | pred_time_val | fit_time | pred_time_test_marginal | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LightGBMClassifier_STACKER_l0 | 0.288530 | 0.306748 | 0.438713 | 0.263853 | 16.381924 | 0.438713 | 0.263853 | 16.381924 | 0 | True | 2 |
| 1 | weighted_ensemble_k0_l1 | 0.288530 | 0.310838 | 12.983819 | 0.908290 | 24.580205 | 0.002760 | 0.000420 | 0.113107 | 1 | True | 3 |
| 2 | NeuralNetClassifier_STACKER_l0 | 0.121409 | 0.124744 | 12.542346 | 0.644016 | 8.085174 | 12.542346 | 0.644016 | 8.085174 | 0 | True | 1 |
The leaderboard shows each model’s predictive performance on the test
data (score_test) and validation data (score_val), as well as
the time required to: produce predictions for the test data
(pred_time_val), produce predictions on the validation data
(pred_time_val), and train only this model (fit_time). Below, we
show that a leaderboard can be produced without new data (just uses the
data previously reserved for validation inside fit) and can display
extra information about each model:
predictor.leaderboard(extra_info=True, silent=True)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | num_features | ... | child_model_type | hyperparameters | hyperparameters_fit | AG_args_fit | features | child_hyperparameters | child_hyperparameters_fit | child_AG_args_fit | ancestors | descendants | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | weighted_ensemble_k0_l1 | 0.310838 | 0.908290 | 24.580205 | 0.000420 | 0.113107 | 1 | True | 3 | 24 | ... | GreedyWeightedEnsembleModel | {'max_models': 25, 'max_models_per_type': 5} | {} | {'max_memory_usage_ratio': 1.0, 'max_time_limi... | [NeuralNetClassifier_STACKER_l0_9, NeuralNetCl... | {'ensemble_size': 100} | {'ensemble_size': 9} | {'max_memory_usage_ratio': 1.0, 'max_time_limi... | [NeuralNetClassifier_STACKER_l0, LightGBMClass... | [] |
| 1 | LightGBMClassifier_STACKER_l0 | 0.306748 | 0.263853 | 16.381924 | 0.263853 | 16.381924 | 0 | True | 2 | 14 | ... | LGBModel | {'max_models': 25, 'max_models_per_type': 5} | {} | {'max_memory_usage_ratio': 1.0, 'max_time_limi... | [education, race, native-country, age, workcla... | {'num_boost_round': 20, 'num_threads': -1, 'ob... | {'num_boost_round': 12} | {'max_memory_usage_ratio': 1.0, 'max_time_limi... | [] | [weighted_ensemble_k0_l1] |
| 2 | NeuralNetClassifier_STACKER_l0 | 0.124744 | 0.644016 | 8.085174 | 0.644016 | 8.085174 | 0 | True | 1 | 14 | ... | TabularNeuralNetModel | {'max_models': 25, 'max_models_per_type': 5} | {} | {'max_memory_usage_ratio': 1.0, 'max_time_limi... | [education, race, native-country, age, workcla... | {'num_epochs': 2, 'epochs_wo_improve': 20, 'se... | {'num_epochs': 2} | {'ignored_type_group_special': ['text_ngram', ... | [] | [weighted_ensemble_k0_l1] |
3 rows × 29 columns
The expanded leaderboard shows properties like how many features are
used by each model (num_features), which other models are ancestors
whose predictions are required inputs for each model (ancestors),
and how much memory each model and all its ancestors would occupy if
simultaneously persisted (memory_size_w_ancestors). See the
leaderboard
documentation
for full details.
Here’s how to specify a particular model to use for prediction instead of AutoGluon’s default model-choice:
i = 0 # index of model to use
model_to_use = predictor.get_model_names()[i]
model_pred = predictor.predict(datapoint, model=model_to_use)
print("Prediction from %s model: %s" % (model_to_use, model_pred))
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
Prediction from NeuralNetClassifier_STACKER_l0 model: [' Adm-clerical']
We can easily access various information about the trained predictor or a particular model:
all_models = predictor.get_model_names()
model_to_use = all_models[i]
specific_model = predictor._trainer.load_model(model_to_use)
# Objects defined below are dicts of various information (not printed here as they are quite large):
model_info = specific_model.get_info()
predictor_information = predictor.info()
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
The predictor also remembers what metric predictions should be
evaluated with, which can be done with ground truth labels as follows:
y_pred = predictor.predict(test_data_nolabel)
predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
Evaluation: accuracy on test data: 0.2885300901656532
Evaluations on test data:
{
"accuracy": 0.2885300901656532,
"accuracy_score": 0.2885300901656532,
"balanced_accuracy_score": 0.19115808471772017,
"matthews_corrcoef": 0.20011333951633872
}
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1221: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
Detailed (per-class) classification report:
{
" ?": {
"precision": 0.9814814814814815,
"recall": 0.7186440677966102,
"f1-score": 0.8297455968688845,
"support": 295
},
" Adm-clerical": {
"precision": 0.2344213649851632,
"recall": 0.28884826325411334,
"f1-score": 0.2588042588042587,
"support": 547
},
" Armed-Forces": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 1
},
" Craft-repair": {
"precision": 0.2945914844649022,
"recall": 0.4082934609250399,
"f1-score": 0.34224598930481287,
"support": 627
},
" Exec-managerial": {
"precision": 0.2484076433121019,
"recall": 0.37925445705024313,
"f1-score": 0.30019243104554205,
"support": 617
},
" Farming-fishing": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 121
},
" Handlers-cleaners": {
"precision": 0.12244897959183673,
"recall": 0.08955223880597014,
"f1-score": 0.10344827586206895,
"support": 201
},
" Machine-op-inspct": {
"precision": 0.1412639405204461,
"recall": 0.13523131672597866,
"f1-score": 0.1381818181818182,
"support": 281
},
" Other-service": {
"precision": 0.26406926406926406,
"recall": 0.13863636363636364,
"f1-score": 0.18181818181818182,
"support": 440
},
" Priv-house-serv": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 20
},
" Prof-specialty": {
"precision": 0.3870558375634518,
"recall": 0.5066445182724253,
"f1-score": 0.43884892086330934,
"support": 602
},
" Protective-serv": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 111
},
" Sales": {
"precision": 0.1510791366906475,
"recall": 0.15412844036697249,
"f1-score": 0.15258855585831063,
"support": 545
},
" Tech-support": {
"precision": 0.5,
"recall": 0.007042253521126761,
"f1-score": 0.01388888888888889,
"support": 142
},
" Transport-moving": {
"precision": 0.15517241379310345,
"recall": 0.0410958904109589,
"f1-score": 0.06498194945848376,
"support": 219
},
"accuracy": 0.2885300901656532,
"macro avg": {
"precision": 0.2319994364314932,
"recall": 0.19115808471772017,
"f1-score": 0.1883163244636373,
"support": 4769
},
"weighted avg": {
"precision": 0.2844555024264947,
"recall": 0.2885300901656532,
"f1-score": 0.2703546074030102,
"support": 4769
}
}
OrderedDict([('accuracy', 0.2885300901656532),
('accuracy_score', 0.2885300901656532),
('balanced_accuracy_score', 0.19115808471772017),
('matthews_corrcoef', 0.20011333951633872),
('confusion_matrix',
? Adm-clerical Armed-Forces Craft-repair ? 212 8 0 11
Adm-clerical 0 158 0 54
Armed-Forces 0 0 0 0
Craft-repair 0 46 0 256
Exec-managerial 1 73 0 59
Farming-fishing 0 11 0 26
Handlers-cleaners 1 31 0 60
Machine-op-inspct 0 46 0 106
Other-service 1 111 0 66
Priv-house-serv 0 2 0 2
Prof-specialty 1 40 0 30
Protective-serv 0 11 0 32
Sales 0 100 0 69
Tech-support 0 24 0 24
Transport-moving 0 13 0 74
Exec-managerial Farming-fishing Handlers-cleaners ? 44 0 0
Adm-clerical 102 3 10
Armed-Forces 0 0 0
Craft-repair 84 4 33
Exec-managerial 234 2 5
Farming-fishing 13 0 7
Handlers-cleaners 10 1 18
Machine-op-inspct 23 1 10
Other-service 35 0 21
Priv-house-serv 5 0 0
Prof-specialty 170 0 3
Protective-serv 24 1 5
Sales 130 1 20
Tech-support 30 1 2
Transport-moving 38 3 13
Machine-op-inspct Other-service Priv-house-serv ? 3 0 0
Adm-clerical 17 52 0
Armed-Forces 0 0 0
Craft-repair 70 10 0
Exec-managerial 7 6 0
Farming-fishing 15 2 0
Handlers-cleaners 33 8 0
Machine-op-inspct 38 24 0
Other-service 29 61 0
Priv-house-serv 2 7 0
Prof-specialty 7 9 0
Protective-serv 5 1 0
Sales 13 40 0
Tech-support 3 7 0
Transport-moving 27 4 0
Prof-specialty Protective-serv Sales Tech-support ? 8 0 3 0
Adm-clerical 74 0 75 1
Armed-Forces 1 0 0 0
Craft-repair 56 0 59 0
Exec-managerial 162 0 65 0
Farming-fishing 6 0 27 0
Handlers-cleaners 4 0 32 0
Machine-op-inspct 9 0 20 0
Other-service 18 0 93 0
Priv-house-serv 1 0 1 0
Prof-specialty 305 0 37 0
Protective-serv 16 0 15 0
Sales 85 0 84 0
Tech-support 37 0 13 1
Transport-moving 6 0 32 0
Transport-moving
? 6
Adm-clerical 1
Armed-Forces 0
Craft-repair 9
Exec-managerial 3
Farming-fishing 14
Handlers-cleaners 3
Machine-op-inspct 4
Other-service 5
Priv-house-serv 0
Prof-specialty 0
Protective-serv 1
Sales 3
Tech-support 0
Transport-moving 9 ),
('classification_report',
{' ?': {'precision': 0.9814814814814815,
'recall': 0.7186440677966102,
'f1-score': 0.8297455968688845,
'support': 295},
' Adm-clerical': {'precision': 0.2344213649851632,
'recall': 0.28884826325411334,
'f1-score': 0.2588042588042587,
'support': 547},
' Armed-Forces': {'precision': 0.0,
'recall': 0.0,
'f1-score': 0.0,
'support': 1},
' Craft-repair': {'precision': 0.2945914844649022,
'recall': 0.4082934609250399,
'f1-score': 0.34224598930481287,
'support': 627},
' Exec-managerial': {'precision': 0.2484076433121019,
'recall': 0.37925445705024313,
'f1-score': 0.30019243104554205,
'support': 617},
' Farming-fishing': {'precision': 0.0,
'recall': 0.0,
'f1-score': 0.0,
'support': 121},
' Handlers-cleaners': {'precision': 0.12244897959183673,
'recall': 0.08955223880597014,
'f1-score': 0.10344827586206895,
'support': 201},
' Machine-op-inspct': {'precision': 0.1412639405204461,
'recall': 0.13523131672597866,
'f1-score': 0.1381818181818182,
'support': 281},
' Other-service': {'precision': 0.26406926406926406,
'recall': 0.13863636363636364,
'f1-score': 0.18181818181818182,
'support': 440},
' Priv-house-serv': {'precision': 0.0,
'recall': 0.0,
'f1-score': 0.0,
'support': 20},
' Prof-specialty': {'precision': 0.3870558375634518,
'recall': 0.5066445182724253,
'f1-score': 0.43884892086330934,
'support': 602},
' Protective-serv': {'precision': 0.0,
'recall': 0.0,
'f1-score': 0.0,
'support': 111},
' Sales': {'precision': 0.1510791366906475,
'recall': 0.15412844036697249,
'f1-score': 0.15258855585831063,
'support': 545},
' Tech-support': {'precision': 0.5,
'recall': 0.007042253521126761,
'f1-score': 0.01388888888888889,
'support': 142},
' Transport-moving': {'precision': 0.15517241379310345,
'recall': 0.0410958904109589,
'f1-score': 0.06498194945848376,
'support': 219},
'accuracy': 0.2885300901656532,
'macro avg': {'precision': 0.2319994364314932,
'recall': 0.19115808471772017,
'f1-score': 0.1883163244636373,
'support': 4769},
'weighted avg': {'precision': 0.2844555024264947,
'recall': 0.2885300901656532,
'f1-score': 0.2703546074030102,
'support': 4769}})])
However, you must be careful here as certain metrics require predicted
probabilities rather than classes. Since the label columns remains in
the test_data DataFrame, we can instead use the shorthand:
perf = predictor.evaluate(test_data)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
Predictive performance on given dataset: accuracy = 0.2885300901656532
which will correctly select between predict() or predict_proba()
depending on the evaluation metric.
Interpretability (feature importance)¶
To better understand our trained predictor, we can estimate the overall importance of each feature:
importance_scores = predictor.feature_importance(test_data)
print(importance_scores)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Computing raw permutation importance for 14 features on weighted_ensemble_k0_l1 ...
59.3s = Expected runtime
59.54s = Actual runtime
education-num 0.067
workclass 0.043
sex 0.034
hours-per-week 0.019
class 0.008
education 0.002
fnlwgt 0.002
capital-gain 0.001
marital-status 0.001
native-country 0.000
capital-loss 0.000
race 0.000
age -0.002
relationship -0.008
dtype: float64
Computed via
permutation-shuffling, these
feature importance scores quantify the drop in predictive performance
(of the already trained predictor) when one column’s values are randomly
shuffled across rows. The top features in this list contribute most to
AutoGluon’s accuracy (for predicting when/if a patient will be
readmitted to the hospital). Features with non-positive importance score
hardly contribute to the predictor’s accuracy, or may even be actively
harmful to include in the data (consider removing these features from
your data and calling fit again). These scores facilitate
interpretability of the predictor’s global behavior (which features it
relies on for all predictions) rather than local
explanations
that only rationalize one particular prediction.
Accelerating inference¶
We describe multiple ways to reduce the time it takes for AutoGluon to produce predictions.
Keeping models in memory¶
By default, AutoGluon loads models into memory one at a time and only when they are needed for prediction. This strategy is robust for large stacked/bagged ensembles, but leads to slower prediction times. If you plan to repeatedly make predictions (e.g. on new datapoints one at a time rather than one large test dataset), you can first specify that all models required for inference should be loaded into memory as follows:
predictor.persist_models()
num_test = 20
preds = np.array(['']*num_test, dtype='object')
for i in range(num_test):
datapoint = test_data_nolabel.iloc[[i]]
pred_numpy = predictor.predict(datapoint)
preds[i] = pred_numpy[0]
perf = predictor.evaluate_predictions(y_test[:num_test], preds, auxiliary_metrics=True)
print("Predictions: ", preds)
predictor.unpersist_models() # free memory by clearing models, future predict() calls will load models from disk
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Persisting 3 models in memory. Models will require 0.1% of memory.
Evaluation: accuracy on test data: 0.25
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1814: UserWarning: y_pred contains classes not in y_true
warnings.warn('y_pred contains classes not in y_true')
Evaluations on test data:
{
"accuracy": 0.25,
"accuracy_score": 0.25,
"balanced_accuracy_score": 0.22380952380952382,
"matthews_corrcoef": 0.14026929848666153
}
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1221: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/sklearn/metrics/_classification.py:1221: UndefinedMetricWarning: Recall and F-score are ill-defined and being set to 0.0 in labels with no true samples. Use zero_division parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
Detailed (per-class) classification report:
{
" ?": {
"precision": 1.0,
"recall": 0.5,
"f1-score": 0.6666666666666666,
"support": 2
},
" Adm-clerical": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 0
},
" Craft-repair": {
"precision": 0.4,
"recall": 0.4,
"f1-score": 0.4000000000000001,
"support": 5
},
" Exec-managerial": {
"precision": 0.14285714285714285,
"recall": 0.3333333333333333,
"f1-score": 0.2,
"support": 3
},
" Handlers-cleaners": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 0
},
" Machine-op-inspct": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 1
},
" Other-service": {
"precision": 1.0,
"recall": 0.3333333333333333,
"f1-score": 0.5,
"support": 3
},
" Sales": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 4
},
" Transport-moving": {
"precision": 0.0,
"recall": 0.0,
"f1-score": 0.0,
"support": 2
},
"accuracy": 0.25,
"macro avg": {
"precision": 0.28253968253968254,
"recall": 0.17407407407407408,
"f1-score": 0.1962962962962963,
"support": 20
},
"weighted avg": {
"precision": 0.37142857142857144,
"recall": 0.25,
"f1-score": 0.27166666666666667,
"support": 20
}
}
Unpersisted 3 models: ['weighted_ensemble_k0_l1', 'NeuralNetClassifier_STACKER_l0', 'LightGBMClassifier_STACKER_l0']
Predictions: [' Exec-managerial' ' Craft-repair' ' Craft-repair' ' Adm-clerical'
' Sales' ' Exec-managerial' ' Exec-managerial' ' Handlers-cleaners'
' Craft-repair' ' Adm-clerical' ' Other-service' ' Exec-managerial'
' Exec-managerial' ' Exec-managerial' ' Adm-clerical' ' ?'
' Handlers-cleaners' ' Craft-repair' ' Exec-managerial' ' Craft-repair']
['weighted_ensemble_k0_l1',
'NeuralNetClassifier_STACKER_l0',
'LightGBMClassifier_STACKER_l0']
You can alternatively specify a particular model to persist via the
models argument of persist_models(), or simply set
models='all' to simultaneously load every single model that was
trained during fit.
Using smaller ensemble or faster model for prediction¶
Without having to retrain any models, one can construct alternative ensembles that aggregate individual models’ predictions with different weighting schemes. These ensembles become smaller (and hence faster for prediction) if they assign nonzero weight to less models. You can produce a wide variety of ensembles with different accuracy-speed tradeoffs like this:
additional_ensembles = predictor.fit_weighted_ensemble(expand_pareto_frontier=True)
print("Alternative ensembles you can use for prediction:", additional_ensembles)
predictor.leaderboard(only_pareto_frontier=True, silent=True)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Fitting model: weighted_ensemble_custom_k0_l1 ...
0.3108 = Validation accuracy score
0.11s = Training runtime
0.0s = Validation runtime
Alternative ensembles you can use for prediction: ['weighted_ensemble_custom_k0_l1']
| model | score_val | pred_time_val | fit_time | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | weighted_ensemble_custom_k0_l1 | 0.310838 | 0.908284 | 24.577966 | 0.000415 | 0.110868 | 1 | True | 4 |
| 1 | LightGBMClassifier_STACKER_l0 | 0.306748 | 0.263853 | 16.381924 | 0.263853 | 16.381924 | 0 | True | 2 |
The resulting leaderboard will contain the most accurate model for a given inference-latency. You can select whichever model exhibits acceptable latency from the leaderboard and use it for prediction.
model_for_prediction = additional_ensembles[0]
predictions = predictor.predict(test_data, model=model_for_prediction)
predictor.delete_models(models_to_delete=additional_ensembles, dry_run=False) # delete these extra models so they don't affect rest of tutorial
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code) Deleting model weighted_ensemble_custom_k0_l1. All files under agModels-predictOccupation/models/weighted_ensemble_custom_k0_l1/ will be removed.
Collapsing bagged ensembles via refit_full¶
For an ensemble predictor trained with bagging (as done above), recall
there ~10 bagged copies of each individual model trained on different
train/validation folds. We can collapse this bag of ~10 models into a
single model that’s fit to the full dataset, which can greatly reduce
its memory/latency requirements (but may also reduce accuracy). Below we
refit such a model for each original model but you can alternatively do
this for just a particular model by specifying the model argument of
refit_full().
refit_model_map = predictor.refit_full()
print("Name of each refit-full model corresponding to a previous bagged ensemble:")
print(refit_model_map)
predictor.leaderboard(test_data, silent=True)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Fitting model: NeuralNetClassifier_FULL_STACKER_l0 ...
0.31s = Training runtime
Fitting model: LightGBMClassifier_FULL_STACKER_l0 ...
0.62s = Training runtime
Fitting model: weighted_ensemble_FULL_k0_l1 ...
0.3108 = Validation accuracy score
0.01s = Training runtime
0.0s = Validation runtime
Name of each refit-full model corresponding to a previous bagged ensemble:
{'NeuralNetClassifier_STACKER_l0': 'NeuralNetClassifier_FULL_STACKER_l0', 'LightGBMClassifier_STACKER_l0': 'LightGBMClassifier_FULL_STACKER_l0', 'weighted_ensemble_k0_l1': 'weighted_ensemble_FULL_k0_l1'}
| model | score_test | score_val | pred_time_test | pred_time_val | fit_time | pred_time_test_marginal | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LightGBMClassifier_STACKER_l0 | 0.288530 | 0.306748 | 0.439134 | 0.263853 | 16.381924 | 0.439134 | 0.263853 | 16.381924 | 0 | True | 2 |
| 1 | weighted_ensemble_k0_l1 | 0.288530 | 0.310838 | 13.348858 | 0.908290 | 24.580205 | 0.002269 | 0.000420 | 0.113107 | 1 | True | 3 |
| 2 | weighted_ensemble_FULL_k0_l1 | 0.280981 | NaN | 0.616362 | NaN | 0.937388 | 0.002915 | 0.000423 | 0.007535 | 1 | True | 6 |
| 3 | LightGBMClassifier_FULL_STACKER_l0 | 0.279933 | NaN | 0.024900 | NaN | 0.623186 | 0.024900 | NaN | 0.623186 | 0 | True | 5 |
| 4 | NeuralNetClassifier_FULL_STACKER_l0 | 0.134410 | NaN | 0.588547 | NaN | 0.306668 | 0.588547 | NaN | 0.306668 | 0 | True | 4 |
| 5 | NeuralNetClassifier_STACKER_l0 | 0.121409 | 0.124744 | 12.907455 | 0.644016 | 8.085174 | 12.907455 | 0.644016 | 8.085174 | 0 | True | 1 |
This adds the refit-full models to the leaderboard and we can opt to use
any of them for prediction just like any other model. Note
pred_time_test and pred_time_val list the time taken to produce
predictions with each model (in seconds) on the test/validation data.
Since the refit-full models were trained using all of the data, there is
no internal validation score (score_val) available for them. You can
also call refit_full() with non-bagged models to refit the same
models to your full dataset (there won’t be memory/latency gains in this
case but test accuracy may improve).
Model distillation¶
While computationally-favorable, single individual models will usually
have lower accuracy than weighted/stacked/bagged ensembles. Model
Distillation offers one way to
retain the computational benefits of a single model, while enjoying some
of the accuracy-boost that comes with ensembling. The idea is to train
the individual model (which we can call the student) to mimic the
predictions of the full stack ensemble (the teacher). Like
refit_full(), the distill() function will produce additional
models we can opt to use for prediction.
student_models = predictor.distill(time_limits=30) # specify much longer time-limits in real applications
print(student_models)
preds_student = predictor.predict(test_data_nolabel, model=student_models[0])
print(f"predictions from {student_models[0]}:", preds_student)
predictor.leaderboard(test_data)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
Distilling with teacher_preds=soft, augment_method=spunge ...
SPUNGE: Augmenting training data with 1955 synthetic samples for distillation...
Distilling with each of these student models: ['LightGBMClassifier_DSTL', 'NeuralNetClassifier_DSTL']
Fitting model: LightGBMClassifier_DSTL ... Training model for up to 30.0s of the 30.0s of remaining time.
1.68s = Training runtime
0.01s = Validation runtime
0.3776 = Validation accuracy score
Fitting model: NeuralNetClassifier_DSTL ... Training model for up to 28.27s of the 28.27s of remaining time.
0.55s = Training runtime
0.03s = Validation runtime
0.0816 = Validation accuracy score
['LightGBMClassifier_DSTL', 'NeuralNetClassifier_DSTL']
predictions from LightGBMClassifier_DSTL: [' Exec-managerial' ' Exec-managerial' ' Craft-repair' ... ' Sales'
' Sales' ' Craft-repair']
model score_test score_val pred_time_test pred_time_val fit_time pred_time_test_marginal pred_time_val_marginal fit_time_marginal stack_level can_infer fit_order
0 LightGBMClassifier_STACKER_l0 0.288530 0.306748 0.439334 0.263853 16.381924 0.439334 0.263853 16.381924 0 True 2
1 weighted_ensemble_k0_l1 0.288530 0.310838 13.468242 0.908290 24.580205 0.002208 0.000420 0.113107 1 True 3
2 LightGBMClassifier_DSTL 0.286853 0.377551 0.030010 0.014457 1.677330 0.030010 0.014457 1.677330 0 True 7
3 weighted_ensemble_FULL_k0_l1 0.280981 NaN 0.610461 NaN 0.937388 0.002879 0.000423 0.007535 1 True 6
4 LightGBMClassifier_FULL_STACKER_l0 0.279933 NaN 0.025337 NaN 0.623186 0.025337 NaN 0.623186 0 True 5
5 NeuralNetClassifier_DSTL 0.136087 0.081633 0.673047 0.032684 0.554203 0.673047 0.032684 0.554203 0 True 8
6 NeuralNetClassifier_FULL_STACKER_l0 0.134410 NaN 0.582246 NaN 0.306668 0.582246 NaN 0.306668 0 True 4
7 NeuralNetClassifier_STACKER_l0 0.121409 0.124744 13.026700 0.644016 8.085174 13.026700 0.644016 8.085174 0 True 1
| model | score_test | score_val | pred_time_test | pred_time_val | fit_time | pred_time_test_marginal | pred_time_val_marginal | fit_time_marginal | stack_level | can_infer | fit_order | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LightGBMClassifier_STACKER_l0 | 0.288530 | 0.306748 | 0.439334 | 0.263853 | 16.381924 | 0.439334 | 0.263853 | 16.381924 | 0 | True | 2 |
| 1 | weighted_ensemble_k0_l1 | 0.288530 | 0.310838 | 13.468242 | 0.908290 | 24.580205 | 0.002208 | 0.000420 | 0.113107 | 1 | True | 3 |
| 2 | LightGBMClassifier_DSTL | 0.286853 | 0.377551 | 0.030010 | 0.014457 | 1.677330 | 0.030010 | 0.014457 | 1.677330 | 0 | True | 7 |
| 3 | weighted_ensemble_FULL_k0_l1 | 0.280981 | NaN | 0.610461 | NaN | 0.937388 | 0.002879 | 0.000423 | 0.007535 | 1 | True | 6 |
| 4 | LightGBMClassifier_FULL_STACKER_l0 | 0.279933 | NaN | 0.025337 | NaN | 0.623186 | 0.025337 | NaN | 0.623186 | 0 | True | 5 |
| 5 | NeuralNetClassifier_DSTL | 0.136087 | 0.081633 | 0.673047 | 0.032684 | 0.554203 | 0.673047 | 0.032684 | 0.554203 | 0 | True | 8 |
| 6 | NeuralNetClassifier_FULL_STACKER_l0 | 0.134410 | NaN | 0.582246 | NaN | 0.306668 | 0.582246 | NaN | 0.306668 | 0 | True | 4 |
| 7 | NeuralNetClassifier_STACKER_l0 | 0.121409 | 0.124744 | 13.026700 | 0.644016 | 8.085174 | 13.026700 | 0.644016 | 8.085174 | 0 | True | 1 |
Faster presets or hyperparameters¶
Instead of trying to speed up a cumbersome trained model at prediction
time, if you know inference latency or memory will be an issue at the
outset, then you can adjust the training process accordingly to ensure
fit() does not produce unwieldy models.
One option is to specify more lightweight presets:
presets = ['good_quality_faster_inference_only_refit', 'optimize_for_deployment']
predictor_light = task.fit(train_data=train_data, label=label_column, eval_metric=metric,
presets=presets, time_limits=30)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
No output_directory specified. Models will be saved in: AutogluonModels/ag-20201208_201209/
Beginning AutoGluon training ... Time limit = 30s
AutoGluon will save models to AutogluonModels/ag-20201208_201209/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21687.87 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.0s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.06s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
Fitting model: NeuralNetClassifier_STACKER_l0 ... Training model for up to 29.94s of the 29.93s of remaining time.
Ran out of time, stopping training early.
Ran out of time, stopping training early.
Ran out of time, stopping training early.
0.3129 = Validation accuracy score
24.47s = Training runtime
0.16s = Validation runtime
Fitting model: RandomForestClassifierGini_STACKER_l0 ... Training model for up to 5.3s of the 5.3s of remaining time.
Warning: Reducing model 'n_estimators' from 300 -> 62 due to low time. Expected time usage reduced from 4.0s -> 0.8s...
Warning: Reducing model 'n_estimators' from 300 -> 74 due to low time. Expected time usage reduced from 4.0s -> 1.0s...
Warning: Reducing model 'n_estimators' from 300 -> 92 due to low time. Expected time usage reduced from 4.0s -> 1.2s...
Warning: Reducing model 'n_estimators' from 300 -> 124 due to low time. Expected time usage reduced from 4.0s -> 1.7s...
Warning: Reducing model 'n_estimators' from 300 -> 222 due to low time. Expected time usage reduced from 4.0s -> 2.9s...
0.3292 = Validation accuracy score
1.7s = Training runtime
0.54s = Validation runtime
Fitting model: RandomForestClassifierEntr_STACKER_l0 ... Training model for up to 3.05s of the 3.05s of remaining time.
Warning: Model is expected to require 4.0s to train, which exceeds the maximum time limit of 0.5s, skipping model...
Time limit exceeded... Skipping RandomForestClassifierEntr_STACKER_l0.
Fitting model: ExtraTreesClassifierGini_STACKER_l0 ... Training model for up to 2.93s of the 2.93s of remaining time.
Warning: Model is expected to require 4.0s to train, which exceeds the maximum time limit of 0.5s, skipping model...
Time limit exceeded... Skipping ExtraTreesClassifierGini_STACKER_l0.
Fitting model: ExtraTreesClassifierEntr_STACKER_l0 ... Training model for up to 2.81s of the 2.81s of remaining time.
Warning: Model is expected to require 3.9s to train, which exceeds the maximum time limit of 0.4s, skipping model...
Time limit exceeded... Skipping ExtraTreesClassifierEntr_STACKER_l0.
Fitting model: LightGBMClassifier_STACKER_l0 ... Training model for up to 2.69s of the 2.68s of remaining time.
Ran out of time, early stopping on iteration 10. Best iteration is:
[6] train_set's multi_error: 0.475703 valid_set's multi_error: 0.714286
Ran out of time, early stopping on iteration 10. Best iteration is:
[5] train_set's multi_error: 0.483376 valid_set's multi_error: 0.704082
Ran out of time, early stopping on iteration 11. Best iteration is:
[11] train_set's multi_error: 0.355499 valid_set's multi_error: 0.602041
Ran out of time, early stopping on iteration 12. Best iteration is:
[2] train_set's multi_error: 0.629156 valid_set's multi_error: 0.765306
Ran out of time, early stopping on iteration 13. Best iteration is:
[4] train_set's multi_error: 0.561224 valid_set's multi_error: 0.690722
0.3047 = Validation accuracy score
2.5s = Training runtime
0.06s = Validation runtime
Fitting model: LightGBMClassifierXT_STACKER_l0 ... Training model for up to 0.11s of the 0.11s of remaining time.
Ran out of time, early stopping on iteration 1. Best iteration is:
[1] train_set's multi_error: 0.808184 valid_set's multi_error: 0.795918
Time limit exceeded... Skipping LightGBMClassifierXT_STACKER_l0.
Completed 1/20 k-fold bagging repeats ...
Fitting model: weighted_ensemble_k0_l1 ... Training model for up to 29.94s of the -0.05s of remaining time.
0.3558 = Validation accuracy score
0.14s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 30.2s ...
Fitting model: RandomForestClassifierGini_FULL_STACKER_l0 ...
0.36s = Training runtime
Fitting model: NeuralNetClassifier_FULL_STACKER_l0 ...
1.42s = Training runtime
Fitting model: LightGBMClassifier_FULL_STACKER_l0 ...
0.37s = Training runtime
Fitting model: weighted_ensemble_FULL_k0_l1 ...
0.3558 = Validation accuracy score
0.08s = Training runtime
0.0s = Validation runtime
Deleting model NeuralNetClassifier_STACKER_l0. All files under AutogluonModels/ag-20201208_201209/models/NeuralNetClassifier_STACKER_l0/ will be removed.
Deleting model RandomForestClassifierGini_STACKER_l0. All files under AutogluonModels/ag-20201208_201209/models/RandomForestClassifierGini_STACKER_l0/ will be removed.
Deleting model LightGBMClassifier_STACKER_l0. All files under AutogluonModels/ag-20201208_201209/models/LightGBMClassifier_STACKER_l0/ will be removed.
Deleting model weighted_ensemble_k0_l1. All files under AutogluonModels/ag-20201208_201209/models/weighted_ensemble_k0_l1/ will be removed.
Another option is to specify more lightweight hyperparameters:
predictor_light = task.fit(train_data=train_data, label=label_column, eval_metric=metric,
hyperparameters='very_light', time_limits=30)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
No output_directory specified. Models will be saved in: AutogluonModels/ag-20201208_201241/
Beginning AutoGluon training ... Time limit = 30s
AutoGluon will save models to AutogluonModels/ag-20201208_201241/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21666.75 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.0s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.07s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
Fitting model: NeuralNetClassifier ... Training model for up to 29.93s of the 29.93s of remaining time.
0.3776 = Validation accuracy score
4.82s = Training runtime
0.03s = Validation runtime
Fitting model: LightGBMClassifier ... Training model for up to 25.07s of the 25.07s of remaining time.
0.3265 = Validation accuracy score
6.47s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMClassifierXT ... Training model for up to 18.58s of the 18.58s of remaining time.
0.3673 = Validation accuracy score
4.27s = Training runtime
0.01s = Validation runtime
Fitting model: CatboostClassifier ... Training model for up to 14.29s of the 14.28s of remaining time.
0.3571 = Validation accuracy score
4.93s = Training runtime
0.02s = Validation runtime
Fitting model: weighted_ensemble_k0_l1 ... Training model for up to 29.93s of the 9.24s of remaining time.
0.398 = Validation accuracy score
0.1s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 20.88s ...
Here you can set hyperparameters to either ‘light’, ‘very_light’,
or ‘toy’ to obtain progressively smaller (but less accurate) models and
predictors. Advanced users may instead try manually specifying
particular models’ hyperparameters in order to make them faster/smaller.
Finally, you may also exclude specific unwieldy models from being trained at all. Below we exclude models that tend to be slower (K Nearest Neighbors, Neural Network, models with custom larger-than-default hyperparameters):
excluded_model_types = ['KNN','NN','custom']
predictor_light = task.fit(train_data=train_data, label=label_column, eval_metric=metric,
excluded_model_types=excluded_model_types, time_limits=30)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
No output_directory specified. Models will be saved in: AutogluonModels/ag-20201208_201302/
Beginning AutoGluon training ... Time limit = 30s
AutoGluon will save models to AutogluonModels/ag-20201208_201302/
AutoGluon Version: 0.0.15b20201208
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == object).
First 10 (of 15) unique label values: [' Exec-managerial', ' Other-service', ' Craft-repair', ' Sales', ' Prof-specialty', ' Protective-serv', ' ?', ' Adm-clerical', ' Machine-op-inspct', ' Tech-support']
If 'multiclass' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 12 out of 15 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.978
Train Data Class Count: 12
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 21628.41 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'relationship', 'race', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.0s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.07s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
AutoGluon will early stop models using evaluation metric: 'accuracy'
Excluded Model Types: ['KNN', 'NN', 'custom']
Found 'NN' model in hyperparameters, but 'NN' is present in excluded_model_types and will be removed.
Found 'KNN' model in hyperparameters, but 'KNN' is present in excluded_model_types and will be removed.
Found 'custom' model in hyperparameters, but 'custom' is present in excluded_model_types and will be removed.
Fitting model: RandomForestClassifierGini ... Training model for up to 29.93s of the 29.93s of remaining time.
0.2857 = Validation accuracy score
0.63s = Training runtime
0.11s = Validation runtime
Fitting model: RandomForestClassifierEntr ... Training model for up to 29.17s of the 29.17s of remaining time.
0.3061 = Validation accuracy score
0.62s = Training runtime
0.11s = Validation runtime
Fitting model: ExtraTreesClassifierGini ... Training model for up to 28.41s of the 28.41s of remaining time.
0.2653 = Validation accuracy score
0.52s = Training runtime
0.11s = Validation runtime
Fitting model: ExtraTreesClassifierEntr ... Training model for up to 27.75s of the 27.75s of remaining time.
0.2551 = Validation accuracy score
0.52s = Training runtime
0.11s = Validation runtime
Fitting model: LightGBMClassifier ... Training model for up to 27.08s of the 27.08s of remaining time.
0.3265 = Validation accuracy score
6.43s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMClassifierXT ... Training model for up to 20.63s of the 20.63s of remaining time.
0.3673 = Validation accuracy score
4.27s = Training runtime
0.01s = Validation runtime
Fitting model: CatboostClassifier ... Training model for up to 16.33s of the 16.33s of remaining time.
0.3571 = Validation accuracy score
4.69s = Training runtime
0.01s = Validation runtime
Fitting model: weighted_ensemble_k0_l1 ... Training model for up to 29.93s of the 11.01s of remaining time.
0.3673 = Validation accuracy score
0.16s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 19.16s ...
If you encounter memory issues¶
To reduce memory usage during training, you may try each of the following strategies individually or combinations of them (these may harm accuracy):
In
fit(), setnum_bagging_sets = 1(can also try values greater than 1 to harm accuracy less).In
fit(), setexcluded_model_types = ['KNN','XT','RF'](or some subset of these models).Try different
presetsinfit().In
fit(), sethyperparameters = ‘light’orhyperparameters = 'very_light'.Text fields in your table require substantial memory for N-gram featurization. To mitigate this in
fit(), you can either: (1) add'ignore_text'to yourpresetslist (to ignore text features), or (2) specify the argument:
feature_generator = AutoMLPipelineFeatureGenerator(vectorizer=CountVectorizer(min_df=30, ngram_range=(1, 3), max_features=MAX_NGRAM, dtype=np.uint8))
where MAX_NGRAM = 1000 say (try various values under 10000 to reduce
the number of N-gram features used to represent each text field), and
CountVectorizer,
AutoMLPipelineFeatureGenerator
must be first imported via:
from sklearn.feature_extraction.text import CountVectorizer
from autogluon.utils.tabular.features.generators.auto_ml_pipeline import AutoMLPipelineFeatureGenerator
In addition to reducing memory usage, many of the above strategies can also be used to reduce training times.
To reduce memory usage during inference:
If trying to produce predictions for a large test dataset, break the test data into smaller chunks as demonstrated in FAQ.
If models have been previously persisted in memory but inference-speed is not a major concern, call
predictor.unpersist_models().If models have been previously persisted in memory, bagging was used in
fit(), and inference-speed is a concern: callpredictor.refit_full()and use one of the refit-full models for prediction (ensure this is the only model persisted in memory).
If you encounter disk space issues¶
To reduce disk usage, you may try each of the following strategies individually or combinations of them:
Make sure to delete all
output_directoryfolders from previousfit()runs! These can eat up your free space if you callfit()many times. If you didn’t specifyoutput_directory, AutoGluon still automatically saved its models to a folder called: “AutogluonModels/ag-[TIMESTAMP]”, where TIMESTAMP records whenfit()was called, so make sure to also delete these folders if you run low on free space.Call
predictor.save_space()to delete auxiliary files produced duringfit().Call
predictor.delete_models(models_to_keep='best', dry_run=False)if you only intend to use this predictor for inference going forward (will delete files required for non-prediction-related functionality likefit_summary).In
fit(), you can add'optimize_for_deployment'to thepresetslist, which will automatically invoke the previous two strategies after training.Most of the above strategies to reduce memory usage will also reduce disk usage (but may harm accuracy).
References¶
The following paper describes how AutoGluon internally operates on tabular data:
Erickson et al. AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data. Arxiv, 2020.