
Demo RL Searcher¶
In this tutorial, we are going to compare RL searcher with random search in a simulation environment.
A Toy Reward Space¶
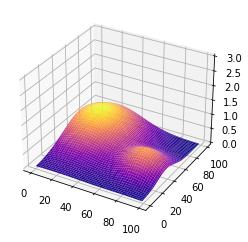
Input Space x = [0: 99], y = [0: 99]. The rewards are a combination
of 2 gaussians as shown in the following figure:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
Generate the simulation rewards as a mixture of 2 gaussians:
def gaussian(x, y, x0, y0, xalpha, yalpha, A):
return A * np.exp( -((x-x0)/xalpha)**2 -((y-y0)/yalpha)**2)
x, y = np.linspace(0, 99, 100), np.linspace(0, 99, 100)
X, Y = np.meshgrid(x, y)
Z = np.zeros(X.shape)
ps = [(20, 70, 35, 40, 1),
(80, 40, 20, 20, 0.7)]
for p in ps:
Z += gaussian(X, Y, *p)
Visualize the reward space:
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z, cmap='plasma')
ax.set_zlim(0,np.max(Z)+2)
plt.show()
Simulation Experiment¶
Customize Train Function¶
We can define any function with a decorator @ag.args, which converts
the function to AutoGluon searchable. The reporter is used to
communicate with AutoGluon search algorithms.
import autogluon as ag
@ag.args(
x=ag.space.Categorical(*list(range(100))),
y=ag.space.Categorical(*list(range(100))),
)
def rl_simulation(args, reporter):
x, y = args.x, args.y
reporter(accuracy=Z[y][x])
Random Search Baseline¶
random_scheduler = ag.scheduler.FIFOScheduler(rl_simulation,
resource={'num_cpus': 1, 'num_gpus': 0},
num_trials=300,
reward_attr='accuracy')
random_scheduler.run()
random_scheduler.join_jobs()
print('Best config: {}, best reward: {}'.format(random_scheduler.get_best_config(), random_scheduler.get_best_reward()))
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code) scheduler_options: Key 'searcher': Imputing default value random scheduler_options: Key 'resume': Imputing default value False scheduler_options: Key 'time_attr': Imputing default value epoch scheduler_options: Key 'visualizer': Imputing default value none scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60 scheduler_options: Key 'delay_get_config': Imputing default value True Starting Experiments Num of Finished Tasks is 0 Num of Pending Tasks is 300
HBox(children=(HTML(value=''), FloatProgress(value=0.0, max=300.0), HTML(value='')))
Best config: {'x▁choice': 22, 'y▁choice': 69}, best reward: 0.9961362873852471
Reinforcement Learning¶
rl_scheduler = ag.scheduler.RLScheduler(rl_simulation,
resource={'num_cpus': 1, 'num_gpus': 0},
num_trials=300,
reward_attr='accuracy',
controller_batch_size=4,
controller_lr=5e-3,
checkpoint='./rl_exp/checkerpoint.ag')
rl_scheduler.run()
rl_scheduler.join_jobs()
print('Best config: {}, best reward: {}'.format(rl_scheduler.get_best_config(), rl_scheduler.get_best_reward()))
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above.
and should_run_async(code)
scheduler_options: Key 'resume': Imputing default value False
scheduler_options: Key 'ema_baseline_decay': Imputing default value 0.95
scheduler_options: Key 'controller_resource': Imputing default value {'num_cpus': 0, 'num_gpus': 0}
scheduler_options: Key 'sync': Imputing default value True
scheduler_options: Key 'time_attr': Imputing default value epoch
scheduler_options: Key 'visualizer': Imputing default value none
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
Reserved DistributedResource(
Node = Remote REMOTE_ID: 0,
<Remote: 'inproc://172.31.38.222/23320/1' processes=1 threads=8, memory=33.24 GB>
nCPUs = 0) in Remote REMOTE_ID: 0,
<Remote: 'inproc://172.31.38.222/23320/1' processes=1 threads=8, memory=33.24 GB>
Starting Experiments
Num of Finished Tasks is 0
Num of Pending Tasks is 300
100%|██████████| 76/76 [00:19<00:00, 3.84it/s]
Best config: {'x▁choice': 21, 'y▁choice': 74}, best reward: 0.9892484241569526
Compare the Performance¶
Get the result history:
results_rl = [v[0]['accuracy'] for v in rl_scheduler.training_history.values()]
results_random = [v[0]['accuracy'] for v in random_scheduler.training_history.values()]
Average result every 10 trials:
import statistics
results1 = [statistics.mean(results_random[i:i+10]) for i in range(0, len(results_random), 10)]
results2 = [statistics.mean(results_rl[i:i+10]) for i in range(0, len(results_rl), 10)]
Plot the results:
plt.plot(range(len(results1)), results1, range(len(results2)), results2)
[<matplotlib.lines.Line2D at 0x7f29842c0f10>,
<matplotlib.lines.Line2D at 0x7f28b8d8c7d0>]
