
Getting started with Advanced HPO Algorithms¶
Loading libraries¶
# Basic utils for folder manipulations etc
import time
import multiprocessing # to count the number of CPUs available
# External tools to load and process data
import numpy as np
import pandas as pd
# MXNet (NeuralNets)
import mxnet as mx
from mxnet import gluon, autograd
from mxnet.gluon import nn
# AutoGluon and HPO tools
import autogluon as ag
from autogluon.utils import load_and_split_openml_data
Check the version of MxNet, you should be fine with version >= 1.5
mx.__version__
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
'1.7.0'
You can also check the version of AutoGluon and the specific commit and check that it matches what you want.
ag.__version__
'0.0.15b20201208'
Hyperparameter Optimization of a 2-layer MLP¶
Setting up the context¶
Here we declare a few “environment variables” setting the context for what we’re doing
OPENML_TASK_ID = 6 # describes the problem we will tackle
RATIO_TRAIN_VALID = 0.33 # split of the training data used for validation
RESOURCE_ATTR_NAME = 'epoch' # how do we measure resources (will become clearer further)
REWARD_ATTR_NAME = 'objective' # how do we measure performance (will become clearer further)
NUM_CPUS = multiprocessing.cpu_count()
Preparing the data¶
We will use a multi-way classification task from OpenML. Data preparation includes:
Missing values are imputed, using the ‘mean’ strategy of
sklearn.impute.SimpleImputerSplit training set into training and validation
Standardize inputs to mean 0, variance 1
X_train, X_valid, y_train, y_valid, n_classes = load_and_split_openml_data(
OPENML_TASK_ID, RATIO_TRAIN_VALID, download_from_openml=False)
n_classes
Downloading ./org/openml/www/datasets/6/dataset.arff from https://autogluon.s3.amazonaws.com/org/openml/www/datasets/6/dataset.arff...
100%|██████████| 704/704 [00:00<00:00, 35778.82KB/s]
Downloading ./org/openml/www/datasets/6/dataset.pkl.py3 from https://autogluon.s3.amazonaws.com/org/openml/www/datasets/6/dataset.pkl.py3...
100%|██████████| 2521/2521 [00:00<00:00, 18565.58KB/s]
Downloading ./org/openml/www/datasets/6/description.xml from https://autogluon.s3.amazonaws.com/org/openml/www/datasets/6/description.xml...
3KB [00:00, 3819.95KB/s]
Downloading ./org/openml/www/datasets/6/features.xml from https://autogluon.s3.amazonaws.com/org/openml/www/datasets/6/features.xml...
8KB [00:00, 9165.37KB/s]
Downloading ./org/openml/www/datasets/6/qualities.xml from https://autogluon.s3.amazonaws.com/org/openml/www/datasets/6/qualities.xml...
15KB [00:00, 15427.80KB/s]
Downloading ./org/openml/www/tasks/6/datasplits.arff from https://autogluon.s3.amazonaws.com/org/openml/www/tasks/6/datasplits.arff...
2998KB [00:00, 19865.09KB/s]
Downloading ./org/openml/www/tasks/6/datasplits.pkl.py3 from https://autogluon.s3.amazonaws.com/org/openml/www/tasks/6/datasplits.pkl.py3...
881KB [00:00, 45336.32KB/s]
Downloading ./org/openml/www/tasks/6/task.xml from https://autogluon.s3.amazonaws.com/org/openml/www/tasks/6/task.xml...
3KB [00:00, 3311.29KB/s]
pickle load data letter
26
The problem has 26 classes.
Declaring a model specifying a hyperparameter space with AutoGluon¶
Two layer MLP where we optimize over:
the number of units on the first layer
the number of units on the second layer
the dropout rate after each layer
the learning rate
the scaling
the
@ag.argsdecorator allows us to specify the space we will optimize over, this matches the ConfigSpace syntax
The body of the function run_mlp_openml is pretty simple:
it reads the hyperparameters given via the decorator
it defines a 2 layer MLP with dropout
it declares a trainer with the ‘adam’ loss function and a provided learning rate
it trains the NN with a number of epochs (most of that is boilerplate code from
mxnet)the
reporterat the end is used to keep track of training history in the hyperparameter optimization
Note: The number of epochs and the hyperparameter space are reduced to make for a shorter experiment
@ag.args(n_units_1=ag.space.Int(lower=16, upper=128),
n_units_2=ag.space.Int(lower=16, upper=128),
dropout_1=ag.space.Real(lower=0, upper=.75),
dropout_2=ag.space.Real(lower=0, upper=.75),
learning_rate=ag.space.Real(lower=1e-6, upper=1, log=True),
batch_size=ag.space.Int(lower=8, upper=128),
scale_1=ag.space.Real(lower=0.001, upper=10, log=True),
scale_2=ag.space.Real(lower=0.001, upper=10, log=True),
epochs=9)
def run_mlp_openml(args, reporter, **kwargs):
# Time stamp for elapsed_time
ts_start = time.time()
# Unwrap hyperparameters
n_units_1 = args.n_units_1
n_units_2 = args.n_units_2
dropout_1 = args.dropout_1
dropout_2 = args.dropout_2
scale_1 = args.scale_1
scale_2 = args.scale_2
batch_size = args.batch_size
learning_rate = args.learning_rate
ctx = mx.cpu()
net = nn.Sequential()
with net.name_scope():
# Layer 1
net.add(nn.Dense(n_units_1, activation='relu',
weight_initializer=mx.initializer.Uniform(scale=scale_1)))
# Dropout
net.add(gluon.nn.Dropout(dropout_1))
# Layer 2
net.add(nn.Dense(n_units_2, activation='relu',
weight_initializer=mx.initializer.Uniform(scale=scale_2)))
# Dropout
net.add(gluon.nn.Dropout(dropout_2))
# Output
net.add(nn.Dense(n_classes))
net.initialize(ctx=ctx)
trainer = gluon.Trainer(net.collect_params(), 'adam',
{'learning_rate': learning_rate})
for epoch in range(args.epochs):
ts_epoch = time.time()
train_iter = mx.io.NDArrayIter(
data={'data': X_train},
label={'label': y_train},
batch_size=batch_size,
shuffle=True)
valid_iter = mx.io.NDArrayIter(
data={'data': X_valid},
label={'label': y_valid},
batch_size=batch_size,
shuffle=False)
metric = mx.metric.Accuracy()
loss = gluon.loss.SoftmaxCrossEntropyLoss()
for batch in train_iter:
data = batch.data[0].as_in_context(ctx)
label = batch.label[0].as_in_context(ctx)
with autograd.record():
output = net(data)
L = loss(output, label)
L.backward()
trainer.step(data.shape[0])
metric.update([label], [output])
name, train_acc = metric.get()
metric = mx.metric.Accuracy()
for batch in valid_iter:
data = batch.data[0].as_in_context(ctx)
label = batch.label[0].as_in_context(ctx)
output = net(data)
metric.update([label], [output])
name, val_acc = metric.get()
print('Epoch %d ; Time: %f ; Training: %s=%f ; Validation: %s=%f' % (
epoch + 1, time.time() - ts_start, name, train_acc, name, val_acc))
ts_now = time.time()
eval_time = ts_now - ts_epoch
elapsed_time = ts_now - ts_start
# The resource reported back (as 'epoch') is the number of epochs
# done, starting at 1
reporter(
epoch=epoch + 1,
objective=float(val_acc),
eval_time=eval_time,
time_step=ts_now,
elapsed_time=elapsed_time)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
Note: The annotation epochs=9 specifies the maximum number of
epochs for training. It becomes available as args.epochs.
Importantly, it is also processed by HyperbandScheduler below in
order to set its max_t attribute.
Recommendation: Whenever writing training code to be passed as
train_fn to a scheduler, if this training code reports a resource
(or time) attribute, the corresponding maximum resource value should be
included in train_fn.args:
If the resource attribute (
time_attrof scheduler) intrain_fnisepoch, make sure to includeepochs=XYZin the annotation. This allows the scheduler to readmax_tfromtrain_fn.args.epochs. This case corresponds to our example here.If the resource attribute is something else than
epoch, you can also include the annotationmax_t=XYZ, which allows the scheduler to readmax_tfromtrain_fn.args.max_t.
Annotating the training function by the correct value for max_t
simplifies scheduler creation (since max_t does not have to be
passed), and avoids inconsistencies between train_fn and the
scheduler.
Running the Hyperparameter Optimization¶
You can use the following schedulers:
FIFO (
fifo)Hyperband (either the stopping (
hbs) or promotion (hbp) variant)
And the following searchers:
Random search (
random)Gaussian process based Bayesian optimization (
bayesopt)SkOpt Bayesian optimization (
skopt; only with FIFO scheduler)
Note that the method known as (asynchronous) Hyperband is using random
search. Combining Hyperband scheduling with the bayesopt searcher
uses a novel method called asynchronous BOHB.
Pick the combination you’re interested in (doing the full experiment
takes around 120 seconds, see the time_out parameter), running
everything with multiple runs can take a fair bit of time. In real life,
you will want to choose a larger time_out in order to obtain good
performance.
SCHEDULER = "hbs"
SEARCHER = "bayesopt"
def compute_error(df):
return 1.0 - df["objective"]
def compute_runtime(df, start_timestamp):
return df["time_step"] - start_timestamp
def process_training_history(task_dicts, start_timestamp,
runtime_fn=compute_runtime,
error_fn=compute_error):
task_dfs = []
for task_id in task_dicts:
task_df = pd.DataFrame(task_dicts[task_id])
task_df = task_df.assign(task_id=task_id,
runtime=runtime_fn(task_df, start_timestamp),
error=error_fn(task_df),
target_epoch=task_df["epoch"].iloc[-1])
task_dfs.append(task_df)
result = pd.concat(task_dfs, axis="index", ignore_index=True, sort=True)
# re-order by runtime
result = result.sort_values(by="runtime")
# calculate incumbent best -- the cumulative minimum of the error.
result = result.assign(best=result["error"].cummin())
return result
resources = dict(num_cpus=NUM_CPUS, num_gpus=0)
search_options = {
'num_init_random': 2,
'debug_log': True}
if SCHEDULER == 'fifo':
myscheduler = ag.scheduler.FIFOScheduler(
run_mlp_openml,
resource=resources,
searcher=SEARCHER,
search_options=search_options,
time_out=120,
time_attr=RESOURCE_ATTR_NAME,
reward_attr=REWARD_ATTR_NAME)
else:
# This setup uses rung levels at 1, 3, 9 epochs. We just use a single
# bracket, so this is in fact successive halving (Hyperband would use
# more than 1 bracket).
# Also note that since we do not use the max_t argument of
# HyperbandScheduler, this value is obtained from train_fn.args.epochs.
sch_type = 'stopping' if SCHEDULER == 'hbs' else 'promotion'
myscheduler = ag.scheduler.HyperbandScheduler(
run_mlp_openml,
resource=resources,
searcher=SEARCHER,
search_options=search_options,
time_out=120,
time_attr=RESOURCE_ATTR_NAME,
reward_attr=REWARD_ATTR_NAME,
type=sch_type,
grace_period=1,
reduction_factor=3,
brackets=1)
# run tasks
myscheduler.run()
myscheduler.join_jobs()
results_df = process_training_history(
myscheduler.training_history.copy(),
start_timestamp=myscheduler._start_time)
max_t = 9, as inferred from train_fn.args
scheduler_options: Key 'resume': Imputing default value False
scheduler_options: Key 'keep_size_ratios': Imputing default value False
scheduler_options: Key 'maxt_pending': Imputing default value False
scheduler_options: Key 'searcher_data': Imputing default value rungs
scheduler_options: Key 'do_snapshots': Imputing default value False
scheduler_options: Key 'visualizer': Imputing default value none
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
search_options: Key 'random_seed': Imputing default value 6623
search_options: Key 'opt_skip_init_length': Imputing default value 150
search_options: Key 'opt_skip_period': Imputing default value 1
search_options: Key 'profiler': Imputing default value False
search_options: Key 'opt_maxiter': Imputing default value 50
search_options: Key 'opt_nstarts': Imputing default value 2
search_options: Key 'opt_warmstart': Imputing default value False
search_options: Key 'opt_verbose': Imputing default value False
search_options: Key 'opt_debug_writer': Imputing default value False
search_options: Key 'num_fantasy_samples': Imputing default value 20
search_options: Key 'num_init_candidates': Imputing default value 250
search_options: Key 'initial_scoring': Imputing default value thompson_indep
search_options: Key 'first_is_default': Imputing default value True
search_options: Key 'opt_skip_num_max_resource': Imputing default value False
search_options: Key 'gp_resource_kernel': Imputing default value matern52
search_options: Key 'resource_acq': Imputing default value bohb
[GPMultiFidelitySearcher.__init__]
- acquisition_class = <class 'autogluon.searcher.bayesopt.models.nphead_acqfunc.EIAcquisitionFunction'>
- local_minimizer_class = <class 'autogluon.searcher.bayesopt.tuning_algorithms.bo_algorithm_components.LBFGSOptimizeAcquisition'>
- num_initial_candidates = 250
- num_initial_random_choices = 2
- initial_scoring = thompson_indep
- first_is_default = True
Starting Experiments
Num of Finished Tasks is 0
Time out (secs) is 120
Starting get_config[random] for config_id 0
Start with default config:
{'batch_size': 68, 'dropout_1': 0.375, 'dropout_2': 0.375, 'learning_rate': 0.001, 'n_units_1': 72, 'n_units_2': 72, 'scale_1': 0.1, 'scale_2': 0.1}
[0: random]
batch_size: 68
dropout_1: 0.375
dropout_2: 0.375
learning_rate: 0.001
n_units_1: 72
n_units_2: 72
scale_1: 0.1
scale_2: 0.1
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/distributed/worker.py:3382: UserWarning: Large object of size 1.30 MB detected in task graph:
(<function run_mlp_openml at 0x7fca3ae220e0>, {'ar ... sReporter}, [])
Consider scattering large objects ahead of time
with client.scatter to reduce scheduler burden and
keep data on workers
future = client.submit(func, big_data) # bad
big_future = client.scatter(big_data) # good
future = client.submit(func, big_future) # good
% (format_bytes(len(b)), s)
Epoch 1 ; Time: 0.487472 ; Training: accuracy=0.260079 ; Validation: accuracy=0.531250
Update for config_id 0:1: reward = 0.53125, crit_val = 0.46875
config_id 0: Reaches 1, continues to 3
Epoch 2 ; Time: 0.926579 ; Training: accuracy=0.496365 ; Validation: accuracy=0.655247
Epoch 3 ; Time: 1.356268 ; Training: accuracy=0.559650 ; Validation: accuracy=0.694686
Update for config_id 0:3: reward = 0.6946858288770054, crit_val = 0.30531417112299464
config_id 0: Reaches 3, continues to 9
Epoch 4 ; Time: 1.845146 ; Training: accuracy=0.588896 ; Validation: accuracy=0.711063
Epoch 5 ; Time: 2.314168 ; Training: accuracy=0.609385 ; Validation: accuracy=0.726939
Epoch 6 ; Time: 2.740413 ; Training: accuracy=0.628139 ; Validation: accuracy=0.745321
Epoch 7 ; Time: 3.177248 ; Training: accuracy=0.641193 ; Validation: accuracy=0.750501
Epoch 8 ; Time: 3.643309 ; Training: accuracy=0.653751 ; Validation: accuracy=0.763202
Epoch 9 ; Time: 4.067426 ; Training: accuracy=0.665482 ; Validation: accuracy=0.766043
config_id 0: Terminating evaluation at 9
Update for config_id 0:9: reward = 0.766042780748663, crit_val = 0.23395721925133695
Starting get_config[random] for config_id 1
[1: random]
batch_size: 115
dropout_1: 0.20259011582642464
dropout_2: 0.733834734066138
learning_rate: 0.05543264041163712
n_units_1: 16
n_units_2: 98
scale_1: 0.002572165463098296
scale_2: 0.10173245902918794
Epoch 1 ; Time: 0.329100 ; Training: accuracy=0.229979 ; Validation: accuracy=0.439465
config_id 1: Terminating evaluation at 1
Update for config_id 1:1: reward = 0.4394648829431438, crit_val = 0.5605351170568562
Starting get_config[BO] for config_id 2
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.39213912685779695
- self.std = 0.12921544434693305
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 4
Current best is [0.46875]
[2: BO] (31 evaluations)
batch_size: 8
dropout_1: 0.75
dropout_2: 0.0
learning_rate: 1.0000000000000004e-06
n_units_1: 104
n_units_2: 16
scale_1: 5.268003346484092
scale_2: 10.0
Started BO from (top scorer):
batch_size: 121
dropout_1: 0.5574991411739321
dropout_2: 0.6004867652907465
learning_rate: 1.1442441844469983e-05
n_units_1: 104
n_units_2: 74
scale_1: 5.1796125582255845
scale_2: 4.062152221968767
Top score values: [0.04288078 0.09683621 0.10506474 0.16396388 0.16578847]
Labeled: 0:1, 0:3, 0:9, 1:1. Pending:
Targets: [ 0.59289254 -0.67193946 -1.22417183 1.30321875]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.6499287450947893, 'kernel_inv_bw1': 0.7868267238572046, 'kernel_inv_bw2': 0.6968644163688983, 'kernel_inv_bw3': 1.5741271749031467, 'kernel_inv_bw4': 0.006439399118472123, 'kernel_inv_bw5': 1.263427319135036, 'kernel_inv_bw6': 0.016976849029310993, 'kernel_inv_bw7': 7.446843139170003, 'kernel_inv_bw8': 77.487094491379, 'kernel_covariance_scale': 0.6952346587872724, 'mean_mean_value': -0.20198178577073855}
Epoch 1 ; Time: 3.706185 ; Training: accuracy=0.030670 ; Validation: accuracy=0.020525
config_id 2: Terminating evaluation at 1
Update for config_id 2:1: reward = 0.020524899057873486, crit_val = 0.9794751009421265
Starting get_config[BO] for config_id 3
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5096063216746629
- self.std = 0.26182336083473223
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 5
Current best is [0.46875]
[3: BO] (1 evaluations)
batch_size: 96
dropout_1: 0.5781081746991475
dropout_2: 0.72091413345427
learning_rate: 1.61137399838547e-06
n_units_1: 109
n_units_2: 22
scale_1: 0.008727376434682146
scale_2: 0.2756687103347264
Started BO from (top scorer):
batch_size: 96
dropout_1: 0.5781081746991475
dropout_2: 0.72091413345427
learning_rate: 1.61137399838547e-06
n_units_1: 109
n_units_2: 22
scale_1: 0.008727376434682146
scale_2: 0.2756687103347264
Top score values: [-0.25782355 -0.02287811 -0.01564609 0.05535007 0.13022974]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1. Pending:
Targets: [-0.15604536 -0.78026709 -1.05280561 0.19451586 1.7946022 ]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 1.3494943628982463, 'kernel_inv_bw1': 0.5787082424900308, 'kernel_inv_bw2': 1.0506610825670117, 'kernel_inv_bw3': 4.215044918879378, 'kernel_inv_bw4': 13.290378704778576, 'kernel_inv_bw5': 0.45832863654556477, 'kernel_inv_bw6': 100.00000000000004, 'kernel_inv_bw7': 0.21774850431320444, 'kernel_inv_bw8': 1.5400558722296638, 'kernel_covariance_scale': 0.8098233651957109, 'mean_mean_value': 0.29870471837022616}
Epoch 1 ; Time: 0.405849 ; Training: accuracy=0.048611 ; Validation: accuracy=0.081989
config_id 3: Terminating evaluation at 1
Update for config_id 3:1: reward = 0.08198924731182795, crit_val = 0.918010752688172
Starting get_config[BO] for config_id 4
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5776737268435811
- self.std = 0.2833585804791231
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 6
Current best is [0.46875]
[4: BO] (2 evaluations)
batch_size: 114
dropout_1: 0.02102008918174078
dropout_2: 0.7424384878196432
learning_rate: 0.009540252459329624
n_units_1: 77
n_units_2: 60
scale_1: 4.513630047489416
scale_2: 2.5774596161227126
Started BO from (top scorer):
batch_size: 114
dropout_1: 0.02115203449262079
dropout_2: 0.7424374090277859
learning_rate: 0.009516071128311068
n_units_1: 77
n_units_2: 60
scale_1: 4.510177647703899
scale_2: 0.4090186411843695
Top score values: [-0.09495753 -0.059177 0.15157438 0.15623764 0.17638331]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1. Pending:
Targets: [-0.38440243 -0.96118337 -1.213009 -0.06048382 1.41799614 1.20108248]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.00791939840556937, 'kernel_inv_bw1': 0.4134976030920574, 'kernel_inv_bw2': 0.19020975634901863, 'kernel_inv_bw3': 0.45927321133324434, 'kernel_inv_bw4': 0.21024309992401136, 'kernel_inv_bw5': 0.5639434738758471, 'kernel_inv_bw6': 0.2973090901522113, 'kernel_inv_bw7': 58.02742522405625, 'kernel_inv_bw8': 1.3178422777681582, 'kernel_covariance_scale': 0.8149392022165727, 'mean_mean_value': 0.4540365480466013}
Epoch 1 ; Time: 0.321782 ; Training: accuracy=0.167825 ; Validation: accuracy=0.421384
config_id 4: Terminating evaluation at 1
Update for config_id 4:1: reward = 0.42138364779874216, crit_val = 0.5786163522012578
Starting get_config[BO] for config_id 5
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5778083876089635
- self.std = 0.26233927661788736
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 7
Current best is [0.46875]
[5: BO] (8 evaluations)
batch_size: 106
dropout_1: 0.0
dropout_2: 0.19489793058292
learning_rate: 0.0001917164114589211
n_units_1: 32
n_units_2: 62
scale_1: 0.8743649345893009
scale_2: 0.011718758917625331
Started BO from (top scorer):
batch_size: 106
dropout_1: 0.027455281142636845
dropout_2: 0.1947445824338346
learning_rate: 0.00019353840383486696
n_units_1: 32
n_units_2: 62
scale_1: 0.8743650199122025
scale_2: 0.011718825652088465
Top score values: [0.23310624 0.24388219 0.2489686 0.26519887 0.28645084]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1. Pending:
Targets: [-0.41571506 -1.03870919 -1.31071173 -0.06584325 1.53109637 1.29680302
0.00307985]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.0011228852506329462, 'kernel_inv_bw1': 0.5389755119780264, 'kernel_inv_bw2': 0.035642439357343174, 'kernel_inv_bw3': 3.4290743735425813, 'kernel_inv_bw4': 0.0009578091245968871, 'kernel_inv_bw5': 0.0071188337593711135, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.0006415358974401202, 'kernel_inv_bw8': 97.96343416545665, 'kernel_covariance_scale': 0.7653084445327711, 'mean_mean_value': -0.2651390598902953}
Epoch 1 ; Time: 0.370475 ; Training: accuracy=0.229229 ; Validation: accuracy=0.304038
config_id 5: Terminating evaluation at 1
Update for config_id 5:1: reward = 0.30403839788149617, crit_val = 0.6959616021185038
Starting get_config[BO] for config_id 6
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.592577539422656
- self.std = 0.24848753281888844
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 8
Current best is [0.46875]
[6: BO] (8 evaluations)
batch_size: 16
dropout_1: 0.3640756919610413
dropout_2: 0.5718969782781318
learning_rate: 0.0013273787481107593
n_units_1: 128
n_units_2: 100
scale_1: 1.5323135545345714
scale_2: 0.2711460391616208
Started BO from (top scorer):
batch_size: 16
dropout_1: 0.36407558466849665
dropout_2: 0.5718969773157769
learning_rate: 0.0013273802663397456
n_units_1: 122
n_units_2: 110
scale_1: 1.5323510833732292
scale_2: 0.27114866856161
Top score values: [0.03998227 0.11977853 0.13245333 0.14247006 0.1801681 ]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1. Pending:
Targets: [-0.49832496 -1.15604741 -1.44321253 -0.12894982 1.55700995 1.3096561
-0.05618466 0.41605332]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.0006993602391388139, 'kernel_inv_bw1': 0.0002486573595518353, 'kernel_inv_bw2': 0.0001318698763768803, 'kernel_inv_bw3': 0.00031063667937819903, 'kernel_inv_bw4': 0.8479717587157058, 'kernel_inv_bw5': 1.7456862096511072, 'kernel_inv_bw6': 0.0007826063528641171, 'kernel_inv_bw7': 0.0006299031529609759, 'kernel_inv_bw8': 1.273414833431511, 'kernel_covariance_scale': 1.3373236492243967, 'mean_mean_value': 0.21836461194132425}
Epoch 1 ; Time: 1.854029 ; Training: accuracy=0.336124 ; Validation: accuracy=0.668683
Update for config_id 6:1: reward = 0.6686827956989247, crit_val = 0.33131720430107525
config_id 6: Reaches 1, continues to 3
Epoch 2 ; Time: 3.640819 ; Training: accuracy=0.500746 ; Validation: accuracy=0.728663
Epoch 3 ; Time: 5.410069 ; Training: accuracy=0.554874 ; Validation: accuracy=0.737735
Update for config_id 6:3: reward = 0.7377352150537635, crit_val = 0.2622647849462365
config_id 6: Reaches 3, continues to 9
Epoch 4 ; Time: 7.642351 ; Training: accuracy=0.601790 ; Validation: accuracy=0.779402
Epoch 5 ; Time: 9.450804 ; Training: accuracy=0.618369 ; Validation: accuracy=0.796875
Epoch 6 ; Time: 11.364773 ; Training: accuracy=0.639920 ; Validation: accuracy=0.812332
Epoch 7 ; Time: 13.246381 ; Training: accuracy=0.656582 ; Validation: accuracy=0.818716
Epoch 8 ; Time: 15.031076 ; Training: accuracy=0.672580 ; Validation: accuracy=0.838710
Epoch 9 ; Time: 16.789679 ; Training: accuracy=0.683107 ; Validation: accuracy=0.830981
config_id 6: Terminating evaluation at 9
Update for config_id 6:9: reward = 0.8309811827956989, crit_val = 0.16901881720430112
Starting get_config[BO] for config_id 7
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5002928292575328
- self.std = 0.26234133843029117
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 11
Current best is [0.3313172]
[7: BO] (4 evaluations)
batch_size: 12
dropout_1: 0.6745038543033849
dropout_2: 0.5392565199404769
learning_rate: 0.8563314945282694
n_units_1: 128
n_units_2: 128
scale_1: 0.00941255860057999
scale_2: 0.2646064285412933
Started BO from (top scorer):
batch_size: 12
dropout_1: 0.6745027588016371
dropout_2: 0.5392565564737246
learning_rate: 0.8563260354947063
n_units_1: 84
n_units_2: 105
scale_1: 0.00942347303672847
scale_2: 0.2646066115886901
Top score values: [0.18302057 0.20010663 0.21453925 0.26892143 0.26953059]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9. Pending:
Targets: [-0.12023583 -0.74322506 -1.01522548 0.22963323 1.82656029 1.59226878
0.29855578 0.74585566 -0.64410598 -0.90732191 -1.26275948]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.00046721381575460976, 'kernel_inv_bw1': 0.00027945416294156703, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 0.000361818016098626, 'kernel_inv_bw4': 0.8054995260303396, 'kernel_inv_bw5': 1.8102707809066103, 'kernel_inv_bw6': 0.002517693024440981, 'kernel_inv_bw7': 0.00010000000000000009, 'kernel_inv_bw8': 1.114599391234888, 'kernel_covariance_scale': 1.0980804092858671, 'mean_mean_value': 0.48770984232856585}
Epoch 1 ; Time: 2.948995 ; Training: accuracy=0.038806 ; Validation: accuracy=0.037879
config_id 7: Terminating evaluation at 1
Update for config_id 7:1: reward = 0.03787878787878788, crit_val = 0.9621212121212122
Starting get_config[BO] for config_id 8
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5387785278295061
- self.std = 0.281745219365974
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 12
Current best is [0.33131721]
[8: BO] (16 evaluations)
batch_size: 8
dropout_1: 0.2659272127964557
dropout_2: 0.6900363068623963
learning_rate: 0.005809894190138349
n_units_1: 128
n_units_2: 95
scale_1: 6.514260009328389
scale_2: 0.0407308493761842
Started BO from (top scorer):
batch_size: 100
dropout_1: 0.10188329107858729
dropout_2: 0.6900361830485076
learning_rate: 0.005808309193037013
n_units_1: 126
n_units_2: 95
scale_1: 6.514197760883919
scale_2: 0.04073063082851759
Top score values: [0.1325505 0.15233528 0.191637 0.22464727 0.23966581]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1. Pending:
Targets: [-0.24855267 -0.82863644 -1.0819041 0.07722079 1.56416699 1.34601121
0.14139663 0.55789083 -0.73634372 -0.98143189 -1.31239036 1.50257273]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.06701545817196791, 'kernel_inv_bw1': 3.1620401434912626, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 0.0005111348651985465, 'kernel_inv_bw4': 0.707297536733937, 'kernel_inv_bw5': 0.002050806496292287, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.00010000000000000009, 'kernel_inv_bw8': 1.5509672657087004, 'kernel_covariance_scale': 0.802545891685748, 'mean_mean_value': 0.2111618055911085}
Epoch 1 ; Time: 4.405943 ; Training: accuracy=0.098226 ; Validation: accuracy=0.160162
config_id 8: Terminating evaluation at 1
Update for config_id 8:1: reward = 0.1601615074024226, crit_val = 0.8398384925975774
Starting get_config[BO] for config_id 9
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5619369866578192
- self.std = 0.2823295185000604
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 13
Current best is [0.3313172]
[9: BO] (1 evaluations)
batch_size: 22
dropout_1: 0.6060180058908871
dropout_2: 0.3694251698271682
learning_rate: 0.21464029125308434
n_units_1: 16
n_units_2: 52
scale_1: 0.0018357925258620815
scale_2: 1.462784943068434
Started BO from (top scorer):
batch_size: 22
dropout_1: 0.6060180058908871
dropout_2: 0.3694251698271682
learning_rate: 0.21464029125308434
n_units_1: 16
n_units_2: 52
scale_1: 0.0018357925258620815
scale_2: 1.462784943068434
Top score values: [0.05141957 0.06756006 0.07343811 0.1288816 0.15526496]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1. Pending:
Targets: [-0.33006463 -0.90894787 -1.16169138 -0.00496537 1.4789035 1.26119921
0.05907765 0.47470989 -0.81684616 -1.0614271 -1.39170063 1.41743672
0.98431615]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.12536897330209024, 'kernel_inv_bw1': 56.05143589172606, 'kernel_inv_bw2': 0.6891701888367768, 'kernel_inv_bw3': 99.97740071934261, 'kernel_inv_bw4': 0.07537196068684757, 'kernel_inv_bw5': 0.8049266978059991, 'kernel_inv_bw6': 0.2532172541571074, 'kernel_inv_bw7': 99.9650172872422, 'kernel_inv_bw8': 1.1172076352259694, 'kernel_covariance_scale': 0.7868042958143471, 'mean_mean_value': 0.35682399111693597}
Epoch 1 ; Time: 1.371782 ; Training: accuracy=0.038003 ; Validation: accuracy=0.038552
config_id 9: Terminating evaluation at 1
Update for config_id 9:1: reward = 0.03855218855218855, crit_val = 0.9614478114478114
Starting get_config[BO] for config_id 10
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5904734741428187
- self.std = 0.29086542110040536
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 14
Current best is [0.33131721]
[10: BO] (38 evaluations)
batch_size: 8
dropout_1: 0.39058248200567325
dropout_2: 0.75
learning_rate: 0.018352560186403126
n_units_1: 112
n_units_2: 114
scale_1: 0.3781195956947368
scale_2: 10.0
Started BO from (top scorer):
batch_size: 67
dropout_1: 0.42180185164183004
dropout_2: 0.14768835668807428
learning_rate: 0.007382785030804872
n_units_1: 17
n_units_2: 107
scale_1: 0.23149492613519776
scale_2: 2.6437066234271045
Top score values: [-0.15693853 0.17195647 0.17419227 0.25711761 0.26617094]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1. Pending:
Targets: [-0.41848726 -0.98038227 -1.22570862 -0.10292855 1.33739385 1.12607844
-0.04076498 0.36266988 -0.89098343 -1.12838676 -1.44896789 1.27773091
0.85732095 1.27541574]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.9537010450485282, 'kernel_inv_bw1': 12.897576685309335, 'kernel_inv_bw2': 0.046304772665198994, 'kernel_inv_bw3': 0.017375775199196232, 'kernel_inv_bw4': 0.03136432845599069, 'kernel_inv_bw5': 0.007643925695191919, 'kernel_inv_bw6': 0.007533859065587351, 'kernel_inv_bw7': 0.16990051031051623, 'kernel_inv_bw8': 1.3697360955805709, 'kernel_covariance_scale': 0.6491252043225703, 'mean_mean_value': 0.3329432783656786}
Epoch 1 ; Time: 4.292739 ; Training: accuracy=0.085046 ; Validation: accuracy=0.073015
config_id 10: Terminating evaluation at 1
Update for config_id 10:1: reward = 0.07301480484522208, crit_val = 0.926985195154778
Starting get_config[BO] for config_id 11
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.6129075888769493
- self.std = 0.29327217171161385
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 15
Current best is [0.33131721]
[11: BO] (17 evaluations)
batch_size: 8
dropout_1: 0.5200398610955415
dropout_2: 0.6746529820978835
learning_rate: 0.0007111511659553435
n_units_1: 20
n_units_2: 127
scale_1: 0.11925200634046369
scale_2: 1.416601084977511
Started BO from (top scorer):
batch_size: 60
dropout_1: 0.6173446849627836
dropout_2: 0.6746530798671563
learning_rate: 1.8073792217344776e-05
n_units_1: 20
n_units_2: 128
scale_1: 0.11925197766089414
scale_2: 1.5592615231526614
Top score values: [0.2202283 0.23189342 0.23951484 0.25662481 0.30129138]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1. Pending:
Targets: [-0.49154882 -1.04883261 -1.29214568 -0.17857975 1.24992259 1.04034134
-0.11692632 0.28319773 -0.96016742 -1.19562249 -1.51357276 1.19074927
0.77378942 1.1884531 1.07094241]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 1.4044370934439048, 'kernel_inv_bw1': 0.09921002427331542, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 9.22095360131539, 'kernel_inv_bw4': 0.004399620781082389, 'kernel_inv_bw5': 0.024535043977392212, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.033807460653923434, 'kernel_inv_bw8': 1.2036867934072941, 'kernel_covariance_scale': 0.6627478502737585, 'mean_mean_value': 0.37911881620584653}
Epoch 1 ; Time: 3.634546 ; Training: accuracy=0.187334 ; Validation: accuracy=0.562752
Update for config_id 11:1: reward = 0.5627523553162853, crit_val = 0.4372476446837147
config_id 11: Reaches 1, continues to 3
Epoch 2 ; Time: 7.186900 ; Training: accuracy=0.287550 ; Validation: accuracy=0.609354
Epoch 3 ; Time: 10.747527 ; Training: accuracy=0.324022 ; Validation: accuracy=0.646366
config_id 11: Terminating evaluation at 3
Update for config_id 11:3: reward = 0.6463660834454913, crit_val = 0.3536339165545087
Starting get_config[BO] for config_id 12
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5873232584936743
- self.std = 0.2846132844157344
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 17
Current best is [0.33131721]
[12: BO] (10 evaluations)
batch_size: 8
dropout_1: 0.7361153286837211
dropout_2: 0.3095766363524611
learning_rate: 3.845433057917802e-05
n_units_1: 98
n_units_2: 59
scale_1: 1.7405406580340526
scale_2: 0.5601206223681634
Started BO from (top scorer):
batch_size: 12
dropout_1: 0.7361132626796868
dropout_2: 0.30957663579249306
learning_rate: 8.518737997663894e-06
n_units_1: 98
n_units_2: 59
scale_1: 1.7404698524703932
scale_2: 0.5601180658452514
Top score values: [0.11524898 0.22380164 0.30153974 0.31926266 0.3474178 ]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3. Pending:
Targets: [-0.41661182 -0.99085005 -1.24156552 -0.09412119 1.37784096 1.16188355
-0.03059206 0.38170511 -0.89948737 -1.14210577 -1.46972915 1.31686739
0.88722223 1.31450137 1.19341561 -0.52729659 -0.82107672]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 1.3270225209850888, 'kernel_inv_bw1': 0.010397356922295495, 'kernel_inv_bw2': 0.0007221262406899736, 'kernel_inv_bw3': 10.500056136753114, 'kernel_inv_bw4': 0.07416146389339609, 'kernel_inv_bw5': 0.005070132310148894, 'kernel_inv_bw6': 0.0184692764104324, 'kernel_inv_bw7': 0.007977234368476308, 'kernel_inv_bw8': 1.170429723053323, 'kernel_covariance_scale': 0.6387803988286264, 'mean_mean_value': 0.5034450880907433}
Epoch 1 ; Time: 3.658152 ; Training: accuracy=0.038793 ; Validation: accuracy=0.056023
config_id 12: Terminating evaluation at 1
Update for config_id 12:1: reward = 0.056022880215343206, crit_val = 0.9439771197846568
Starting get_config[BO] for config_id 13
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.6071373618987289
- self.std = 0.2884070684723663
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 18
Current best is [0.33131721]
[13: BO] (50 evaluations)
batch_size: 34
dropout_1: 0.0
dropout_2: 0.16531656565678315
learning_rate: 0.0015710151190437619
n_units_1: 16
n_units_2: 53
scale_1: 0.0010000000000000002
scale_2: 0.02515153076268347
Started BO from (top scorer):
batch_size: 65
dropout_1: 0.14708276563581593
dropout_2: 0.17195192075723356
learning_rate: 0.0022913550028786415
n_units_1: 74
n_units_2: 57
scale_1: 0.33881181967715607
scale_2: 0.06287741099517685
Top score values: [0.24173118 0.32261171 0.32342942 0.35403063 0.37132952]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1. Pending:
Targets: [-0.47983346 -1.04651801 -1.29393549 -0.16158496 1.29101461 1.07789796
-0.09889151 0.30798219 -0.95635713 -1.19578407 -1.51909781 1.2308431
0.80684961 1.2285082 1.10901524 -0.58906225 -0.87897792 1.1679317 ]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 1.3590575477767326, 'kernel_inv_bw1': 0.03936069903087651, 'kernel_inv_bw2': 0.0026984432414393494, 'kernel_inv_bw3': 10.296001231381487, 'kernel_inv_bw4': 0.04807502049559833, 'kernel_inv_bw5': 0.0075945343276932874, 'kernel_inv_bw6': 0.04822808438234503, 'kernel_inv_bw7': 0.02645952960098961, 'kernel_inv_bw8': 1.1509944808708752, 'kernel_covariance_scale': 0.6224491569300521, 'mean_mean_value': 0.5128076290185375}
Epoch 1 ; Time: 0.895618 ; Training: accuracy=0.285004 ; Validation: accuracy=0.484706
Update for config_id 13:1: reward = 0.48470588235294115, crit_val = 0.5152941176470589
config_id 13: Reaches 1, continues to 3
Epoch 2 ; Time: 1.719433 ; Training: accuracy=0.541591 ; Validation: accuracy=0.605882
Epoch 3 ; Time: 2.555429 ; Training: accuracy=0.613422 ; Validation: accuracy=0.655462
config_id 13: Terminating evaluation at 3
Update for config_id 13:3: reward = 0.6554621848739496, crit_val = 0.3445378151260504
Starting get_config[BO] for config_id 14
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5894152223475115
- self.std = 0.28002925628238085
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 20
Current best is [0.33131721]
[14: BO] (11 evaluations)
batch_size: 128
dropout_1: 0.3960821640083113
dropout_2: 0.042683254962728207
learning_rate: 0.0019572264290375644
n_units_1: 128
n_units_2: 67
scale_1: 0.0018443079577594394
scale_2: 0.21772892819706435
Started BO from (top scorer):
batch_size: 96
dropout_1: 0.3960815012094535
dropout_2: 0.042683322497057974
learning_rate: 0.002198541885573249
n_units_1: 121
n_units_2: 67
scale_1: 0.0018447905151312408
scale_2: 0.21772889032173864
Top score values: [0.24839197 0.3059221 0.31899261 0.33188266 0.36762275]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3. Pending:
Targets: [-0.4309022 -1.01454061 -1.26936024 -0.10313246 1.39292545 1.17343286
-0.03856336 0.38048303 -0.92168233 -1.16827235 -1.50125887 1.33095375
0.89427538 1.328549 1.20548109 -0.54339886 -0.84198812 1.26616019
-0.26469057 -0.8744708 ]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 1.1570959984938367, 'kernel_inv_bw1': 0.0013202869606903764, 'kernel_inv_bw2': 0.0003397239151057199, 'kernel_inv_bw3': 8.199525210323392, 'kernel_inv_bw4': 0.40806701165574927, 'kernel_inv_bw5': 0.0018460943947932122, 'kernel_inv_bw6': 0.005969169164110574, 'kernel_inv_bw7': 0.00019791409072134644, 'kernel_inv_bw8': 1.2666478406791895, 'kernel_covariance_scale': 0.701840781818308, 'mean_mean_value': 0.5419607149303785}
Epoch 1 ; Time: 0.293656 ; Training: accuracy=0.374836 ; Validation: accuracy=0.645778
Update for config_id 14:1: reward = 0.6457779255319149, crit_val = 0.35422207446808507
config_id 14: Reaches 1, continues to 3
Epoch 2 ; Time: 0.531325 ; Training: accuracy=0.634375 ; Validation: accuracy=0.724402
Epoch 3 ; Time: 0.780186 ; Training: accuracy=0.685197 ; Validation: accuracy=0.753657
Update for config_id 14:3: reward = 0.753656914893617, crit_val = 0.24634308510638303
config_id 14: Reaches 3, continues to 9
Epoch 4 ; Time: 1.024297 ; Training: accuracy=0.719819 ; Validation: accuracy=0.791722
Epoch 5 ; Time: 1.252722 ; Training: accuracy=0.738898 ; Validation: accuracy=0.804355
Epoch 6 ; Time: 1.483242 ; Training: accuracy=0.756908 ; Validation: accuracy=0.821975
Epoch 7 ; Time: 1.712579 ; Training: accuracy=0.769572 ; Validation: accuracy=0.833112
Epoch 8 ; Time: 1.942191 ; Training: accuracy=0.781497 ; Validation: accuracy=0.847573
Epoch 9 ; Time: 2.190483 ; Training: accuracy=0.788734 ; Validation: accuracy=0.855884
config_id 14: Terminating evaluation at 9
Update for config_id 14:9: reward = 0.8558843085106383, crit_val = 0.14411569148936165
Starting get_config[BO] for config_id 15
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5449124042614809
- self.std = 0.2869693324790331
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 23
Current best is [0.33131721]
[15: BO] (20 evaluations)
batch_size: 128
dropout_1: 0.5874699566298283
dropout_2: 0.019158429826698728
learning_rate: 0.0028143456348614813
n_units_1: 16
n_units_2: 65
scale_1: 0.007570194869186357
scale_2: 0.4176590013022225
Started BO from (top scorer):
batch_size: 120
dropout_1: 0.5874698784709596
dropout_2: 0.019158458756236257
learning_rate: 0.004943278031654848
n_units_1: 45
n_units_2: 65
scale_1: 0.007570194707280391
scale_2: 0.41765883900238027
Top score values: [0.33024692 0.36369566 0.37554193 0.37856652 0.41267252]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9. Pending:
Targets: [-0.26540259 -0.83492627 -1.08358333 0.05444036 1.51431755 1.30013317
0.11744791 0.52636007 -0.74431368 -0.98494016 -1.30987372 1.45384458
1.02772685 1.45149798 1.33140635 -0.37517863 -0.66654679 1.39061799
-0.10321063 -0.69824391 -0.66449724 -1.04042239 -1.39665347]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.8734634367949952, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 8.153205061445796, 'kernel_inv_bw4': 0.42861232208826666, 'kernel_inv_bw5': 0.00039202069260665104, 'kernel_inv_bw6': 0.0002390795781528369, 'kernel_inv_bw7': 0.00010000000000000009, 'kernel_inv_bw8': 1.1579246089342603, 'kernel_covariance_scale': 0.7727887367465754, 'mean_mean_value': 0.5584941941324477}
Epoch 1 ; Time: 0.294466 ; Training: accuracy=0.152549 ; Validation: accuracy=0.472074
Update for config_id 15:1: reward = 0.4720744680851064, crit_val = 0.5279255319148937
config_id 15: Reaches 1, continues to 3
Epoch 2 ; Time: 0.537837 ; Training: accuracy=0.298109 ; Validation: accuracy=0.568816
Epoch 3 ; Time: 0.776367 ; Training: accuracy=0.353701 ; Validation: accuracy=0.629820
config_id 15: Terminating evaluation at 3
Update for config_id 15:3: reward = 0.6298204787234043, crit_val = 0.3701795212765957
Starting get_config[BO] for config_id 16
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.537243614048222
- self.std = 0.2773757036702802
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 25
Current best is [0.33131721]
[16: BO] (19 evaluations)
batch_size: 84
dropout_1: 0.29561829231685044
dropout_2: 0.04596460097673949
learning_rate: 5.724211615833766e-06
n_units_1: 16
n_units_2: 128
scale_1: 0.12674180899264345
scale_2: 0.05366256812884492
Started BO from (top scorer):
batch_size: 84
dropout_1: 0.29561835745224185
dropout_2: 0.045964606867111624
learning_rate: 7.894147491592967e-06
n_units_1: 47
n_units_2: 89
scale_1: 0.1267418849373593
scale_2: 0.05726027896274499
Top score values: [0.30987005 0.3136461 0.31724314 0.32688824 0.32740173]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3. Pending:
Targets: [-0.24693444 -0.8361563 -1.0934137 0.08397096 1.59434111 1.37274871
0.14915776 0.57221302 -0.74240969 -0.99135874 -1.32753083 1.53177655
1.09092063 1.52934879 1.40510353 -0.36050731 -0.66195307 1.46636313
-0.07913273 -0.6947465 -0.65983263 -1.04875995 -1.41731203 -0.03359372
-0.60230255]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.014383779703254456, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 8.832360400391776, 'kernel_inv_bw4': 1.3472447408705768, 'kernel_inv_bw5': 0.21165268977016086, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.03367028338858101, 'kernel_inv_bw8': 1.1091776477163353, 'kernel_covariance_scale': 0.895496207576915, 'mean_mean_value': 0.7364176704770193}
Epoch 1 ; Time: 0.407605 ; Training: accuracy=0.032242 ; Validation: accuracy=0.034205
config_id 16: Terminating evaluation at 1
Update for config_id 16:1: reward = 0.03420523138832998, crit_val = 0.96579476861167
Starting get_config[BO] for config_id 17
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5537263507622007
- self.std = 0.28420093250084527
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 26
Current best is [0.33131721]
[17: BO] (23 evaluations)
batch_size: 8
dropout_1: 0.42586366439452183
dropout_2: 0.35223538880391364
learning_rate: 0.0008740524364132574
n_units_1: 128
n_units_2: 115
scale_1: 0.003423700940392097
scale_2: 1.68546307271504
Started BO from (top scorer):
batch_size: 11
dropout_1: 0.4258636765224537
dropout_2: 0.35223545110974847
learning_rate: 0.0008874104488487803
n_units_1: 69
n_units_2: 115
scale_1: 0.0034237046336428783
scale_2: 1.685459854482685
Top score values: [0.34829086 0.36348719 0.36570441 0.37972359 0.38632808]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1. Pending:
Targets: [-0.29900096 -0.87407236 -1.12515159 0.02395758 1.49805543 1.28178468
0.08757889 0.50047426 -0.78257712 -1.02554754 -1.35364627 1.43699339
1.00672485 1.43462394 1.31336249 -0.40984632 -0.7040527 1.37315091
-0.13522909 -0.73605858 -0.70198319 -1.08157022 -1.44127134 -0.09078372
-0.64583472 1.4499193 ]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.7888083475148504, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 7.332875248743284, 'kernel_inv_bw4': 0.3771762783333212, 'kernel_inv_bw5': 0.0016658182432786528, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.0002777776968666048, 'kernel_inv_bw8': 1.1887945351189257, 'kernel_covariance_scale': 0.8060677884471117, 'mean_mean_value': 0.5254497585338413}
Epoch 1 ; Time: 3.757869 ; Training: accuracy=0.485162 ; Validation: accuracy=0.740747
Update for config_id 17:1: reward = 0.7407469717362046, crit_val = 0.25925302826379537
config_id 17: Reaches 1, continues to 3
Epoch 2 ; Time: 7.342433 ; Training: accuracy=0.620441 ; Validation: accuracy=0.783479
Epoch 3 ; Time: 10.871896 ; Training: accuracy=0.666777 ; Validation: accuracy=0.805013
Update for config_id 17:3: reward = 0.8050134589502019, crit_val = 0.19498654104979807
config_id 17: Reaches 3, continues to 9
Epoch 4 ; Time: 14.472019 ; Training: accuracy=0.688578 ; Validation: accuracy=0.811406
Epoch 5 ; Time: 18.196518 ; Training: accuracy=0.701426 ; Validation: accuracy=0.815949
Epoch 6 ; Time: 21.747994 ; Training: accuracy=0.711207 ; Validation: accuracy=0.836137
Epoch 7 ; Time: 25.340872 ; Training: accuracy=0.725216 ; Validation: accuracy=0.839838
Epoch 8 ; Time: 29.057332 ; Training: accuracy=0.730355 ; Validation: accuracy=0.844549
Epoch 9 ; Time: 32.737144 ; Training: accuracy=0.740882 ; Validation: accuracy=0.851783
config_id 17: Terminating evaluation at 9
Update for config_id 17:9: reward = 0.8517833109017496, crit_val = 0.14821668909825036
Starting get_config[BO] for config_id 18
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5172186682147953
- self.std = 0.2901378851551728
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 29
Current best is [0.25925303]
[18: BO] (25 evaluations)
batch_size: 8
dropout_1: 0.6103372263926843
dropout_2: 0.75
learning_rate: 0.0006065386795024323
n_units_1: 128
n_units_2: 116
scale_1: 6.883514764953241
scale_2: 1.9951490582671303
Started BO from (top scorer):
batch_size: 27
dropout_1: 0.6103372305742708
dropout_2: 0.7169201124332221
learning_rate: 0.0007434736984816291
n_units_1: 113
n_units_2: 116
scale_1: 6.883405660029565
scale_2: 1.9951489067176602
Top score values: [0.29140152 0.35405184 0.36892151 0.37652894 0.3779718 ]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9. Pending:
Targets: [-0.16705391 -0.7303579 -0.97629942 0.14929608 1.59323017 1.38138487
0.21161554 0.61606203 -0.64073488 -0.87873351 -1.20011853 1.53341762
1.11195346 1.53109665 1.41231652 -0.2756311 -0.56381727 1.47088151
-0.00663323 -0.59516824 -0.56179011 -0.93360984 -1.28595056 0.03690267
-0.50679058 1.54607903 -0.88911395 -1.11061721 -1.27181591]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.8212271192604788, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.1901591006465807, 'kernel_inv_bw3': 6.338459251879282, 'kernel_inv_bw4': 0.3895836008359322, 'kernel_inv_bw5': 0.0007520472230177056, 'kernel_inv_bw6': 0.0008055860353685261, 'kernel_inv_bw7': 0.00015286692670848332, 'kernel_inv_bw8': 1.0493843619970442, 'kernel_covariance_scale': 0.8464555264643454, 'mean_mean_value': 0.5698720264511019}
Epoch 1 ; Time: 3.634857 ; Training: accuracy=0.086621 ; Validation: accuracy=0.416218
config_id 18: Terminating evaluation at 1
Update for config_id 18:1: reward = 0.41621803499327054, crit_val = 0.5837819650067295
Starting get_config[BO] for config_id 19
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.5194374447745264
- self.std = 0.2855113986670422
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 30
Current best is [0.25925303]
[19: BO] (22 evaluations)
batch_size: 57
dropout_1: 0.15094904546633964
dropout_2: 0.054486021482137714
learning_rate: 0.0012666545242820861
n_units_1: 59
n_units_2: 117
scale_1: 0.0010000000000000002
scale_2: 2.321079057850671
Started BO from (top scorer):
batch_size: 57
dropout_1: 0.1509661326935938
dropout_2: 0.0544905189778816
learning_rate: 0.0018805444047928965
n_units_1: 59
n_units_2: 117
scale_1: 7.9386304987563845
scale_2: 3.675533754679733
Top score values: [0.15998046 0.16207085 0.24653442 0.30552353 0.3111285 ]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9, 18:1. Pending:
Targets: [-0.17753212 -0.74996401 -0.99989082 0.14394407 1.61127597 1.39599788
0.20727336 0.61827359 -0.65888872 -0.90074393 -1.22733673 1.5504942
1.12220055 1.54813562 1.42743075 -0.28786872 -0.58072472 1.48694475
-0.01451195 -0.6125837 -0.57866471 -0.95650948 -1.31455961 0.02972942
-0.52277396 1.56336078 -0.91129257 -1.13638512 -1.30019592 0.22536585]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.00433111323493072, 'kernel_inv_bw1': 0.0024413041830750283, 'kernel_inv_bw2': 0.0009169872154755717, 'kernel_inv_bw3': 13.772939589553168, 'kernel_inv_bw4': 0.0006378068727762713, 'kernel_inv_bw5': 0.00010000000000000009, 'kernel_inv_bw6': 0.2946555693253991, 'kernel_inv_bw7': 1.9253478811176665, 'kernel_inv_bw8': 1.2453772959764744, 'kernel_covariance_scale': 0.7867773961362077, 'mean_mean_value': 0.8260903038304861}
Epoch 1 ; Time: 0.599440 ; Training: accuracy=0.531281 ; Validation: accuracy=0.729323
Update for config_id 19:1: reward = 0.7293233082706767, crit_val = 0.2706766917293233
config_id 19: Reaches 1, continues to 3
Epoch 2 ; Time: 1.115420 ; Training: accuracy=0.709037 ; Validation: accuracy=0.798830
Epoch 3 ; Time: 1.625280 ; Training: accuracy=0.751324 ; Validation: accuracy=0.819716
Update for config_id 19:3: reward = 0.8197159565580618, crit_val = 0.18028404344193816
config_id 19: Reaches 3, continues to 9
Epoch 4 ; Time: 2.136457 ; Training: accuracy=0.777557 ; Validation: accuracy=0.845113
Epoch 5 ; Time: 2.652630 ; Training: accuracy=0.796922 ; Validation: accuracy=0.851295
Epoch 6 ; Time: 3.163065 ; Training: accuracy=0.803956 ; Validation: accuracy=0.869173
Epoch 7 ; Time: 3.677748 ; Training: accuracy=0.813803 ; Validation: accuracy=0.870510
Epoch 8 ; Time: 4.186631 ; Training: accuracy=0.825472 ; Validation: accuracy=0.880535
Epoch 9 ; Time: 4.694727 ; Training: accuracy=0.830354 ; Validation: accuracy=0.886884
config_id 19: Terminating evaluation at 9
Update for config_id 19:9: reward = 0.8868838763575606, crit_val = 0.11311612364243939
Starting get_config[BO] for config_id 20
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.4893090970318028
- self.std = 0.2890712425986082
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 33
Current best is [0.18028404]
[20: BO] (19 evaluations)
batch_size: 50
dropout_1: 0.49158334246503194
dropout_2: 0.6092455972564605
learning_rate: 0.0012226018662646772
n_units_1: 128
n_units_2: 101
scale_1: 0.0010000000000000002
scale_2: 8.841059210697582
Started BO from (top scorer):
batch_size: 50
dropout_1: 0.4915833332725128
dropout_2: 0.6092455947750531
learning_rate: 0.0009896305015320154
n_units_1: 105
n_units_2: 104
scale_1: 0.004185509210264236
scale_2: 8.841058817468932
Top score values: [0.14444307 0.21323356 0.24522217 0.24625234 0.25256966]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9, 18:1, 19:1, 19:3, 19:9. Pending:
Targets: [-0.07112121 -0.63650374 -0.88335275 0.24639608 1.69565813 1.48303114
0.30894548 0.71488434 -0.54655002 -0.78542684 -1.10799773 1.63562488
1.21260556 1.63329534 1.51407693 -0.18009904 -0.46934859 1.57285802
0.08989141 -0.50081523 -0.46731394 -0.84050565 -1.19414648 0.13358795
-0.41211147 1.64833301 -0.79584557 -1.01816616 -1.17995967 0.32681517
-0.75632707 -1.06902731 -1.30138498]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.0025147433668945606, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.00010000000000000009, 'kernel_inv_bw3': 10.228070087035343, 'kernel_inv_bw4': 0.3341694514951017, 'kernel_inv_bw5': 1.5345181583587304, 'kernel_inv_bw6': 0.42391206685457244, 'kernel_inv_bw7': 0.00010000000000000009, 'kernel_inv_bw8': 0.9836551864837128, 'kernel_covariance_scale': 0.7751464871518577, 'mean_mean_value': 0.9277859812909629}
Epoch 1 ; Time: 0.659930 ; Training: accuracy=0.309752 ; Validation: accuracy=0.653277
Update for config_id 20:1: reward = 0.6532773109243698, crit_val = 0.3467226890756302
config_id 20: Reaches 1, continues to 3
Epoch 2 ; Time: 1.318232 ; Training: accuracy=0.458430 ; Validation: accuracy=0.712269
Epoch 3 ; Time: 1.887254 ; Training: accuracy=0.503554 ; Validation: accuracy=0.734118
config_id 20: Terminating evaluation at 3
Update for config_id 20:3: reward = 0.7341176470588235, crit_val = 0.26588235294117646
Starting get_config[BO] for config_id 21
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.4788515784018943
- self.std = 0.28405104436502127
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 35
Current best is [0.18028404]
[21: BO] (21 evaluations)
batch_size: 69
dropout_1: 0.6846097998516558
dropout_2: 0.0
learning_rate: 0.00419794572293586
n_units_1: 128
n_units_2: 16
scale_1: 0.01280647308906677
scale_2: 1.4928556711581158
Started BO from (top scorer):
batch_size: 69
dropout_1: 0.6846098063842428
dropout_2: 0.37503620187634523
learning_rate: 0.006604515646728909
n_units_1: 39
n_units_2: 16
scale_1: 0.012806773195459422
scale_2: 1.4928547138400632
Top score values: [0.07741982 0.1112656 0.13929171 0.16458562 0.17968934]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9, 18:1, 19:1, 19:3, 19:9, 20:1, 20:3. Pending:
Targets: [-0.03556255 -0.6109374 -0.86214912 0.28756641 1.76244211 1.54605724
0.35122129 0.76433454 -0.51939388 -0.76249251 -1.09076438 1.70134785
1.27085227 1.69897715 1.57765171 -0.1464664 -0.44082803 1.63747168
0.12829574 -0.4728508 -0.43875742 -0.81854476 -1.17843568 0.17276456
-0.38257933 1.71428058 -0.77309538 -0.99934516 -1.16399815 0.3694068
-0.73287844 -1.05110522 -1.28756948 -0.46515896 -0.74975688]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.0027323470407812672, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.625258886948428, 'kernel_inv_bw3': 10.700609872387792, 'kernel_inv_bw4': 0.3590962475629683, 'kernel_inv_bw5': 1.5098067650168017, 'kernel_inv_bw6': 0.0004296334105178157, 'kernel_inv_bw7': 0.00010000000000000009, 'kernel_inv_bw8': 1.0249418832596129, 'kernel_covariance_scale': 0.7844650900066925, 'mean_mean_value': 0.9631358750589729}
Epoch 1 ; Time: 0.482841 ; Training: accuracy=0.390973 ; Validation: accuracy=0.650341
Update for config_id 21:1: reward = 0.6503414959187073, crit_val = 0.34965850408129273
config_id 21: Reaches 1, continues to 3
Epoch 2 ; Time: 0.899163 ; Training: accuracy=0.551056 ; Validation: accuracy=0.727136
Epoch 3 ; Time: 1.419126 ; Training: accuracy=0.599172 ; Validation: accuracy=0.741129
config_id 21: Terminating evaluation at 3
Update for config_id 21:3: reward = 0.7411294352823589, crit_val = 0.25887056471764114
Starting get_config[BO] for config_id 22
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.4694144408882496
- self.std = 0.27927329180703736
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 37
Current best is [0.18028404]
[22: BO] (31 evaluations)
batch_size: 97
dropout_1: 0.03525520179231688
dropout_2: 0.0
learning_rate: 0.0010462362290686923
n_units_1: 128
n_units_2: 116
scale_1: 0.0089324290118041
scale_2: 0.002694886459580705
Started BO from (top scorer):
batch_size: 97
dropout_1: 0.03525519267376742
dropout_2: 0.14112112793136056
learning_rate: 0.0008731605681165959
n_units_1: 34
n_units_2: 111
scale_1: 0.00893254334894475
scale_2: 0.0026966114746035533
Top score values: [0.13717338 0.16953916 0.20037068 0.20657606 0.2089187 ]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9, 18:1, 19:1, 19:3, 19:9, 20:1, 20:3, 21:1, 21:3. Pending:
Targets: [-0.00237918 -0.58759743 -0.84310684 0.3262778 1.82638539 1.60629865
0.39102168 0.81120239 -0.4944878 -0.74174532 -1.0756332 1.76424594
1.32638552 1.76183468 1.63843363 -0.11518035 -0.41457786 1.69927699
0.16428236 -0.44714847 -0.41247183 -0.7987565 -1.16480437 0.20951195
-0.35533265 1.77739992 -0.75252958 -0.98265 -1.15011983 0.4095183
-0.71162462 -1.03529555 -1.2758052 -0.43932505 -0.72879181 -0.42881271
-0.75389907]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.008237124952554261, 'kernel_inv_bw1': 0.00010000000000000009, 'kernel_inv_bw2': 0.5880912076104247, 'kernel_inv_bw3': 10.185589798340844, 'kernel_inv_bw4': 0.3653671308166189, 'kernel_inv_bw5': 1.3603653677848018, 'kernel_inv_bw6': 0.00010000000000000009, 'kernel_inv_bw7': 0.0027483490401810492, 'kernel_inv_bw8': 0.9967960318909171, 'kernel_covariance_scale': 0.8585744127880335, 'mean_mean_value': 0.9591701223363772}
Epoch 1 ; Time: 0.406953 ; Training: accuracy=0.283216 ; Validation: accuracy=0.534420
Update for config_id 22:1: reward = 0.5344196873960758, crit_val = 0.4655803126039242
config_id 22: Reaches 1, continues to 3
Epoch 2 ; Time: 0.708424 ; Training: accuracy=0.605938 ; Validation: accuracy=0.657965
Epoch 3 ; Time: 1.003700 ; Training: accuracy=0.696825 ; Validation: accuracy=0.724144
config_id 22: Terminating evaluation at 3
Update for config_id 22:3: reward = 0.724143664782175, crit_val = 0.27585633521782504
Starting get_config[BO] for config_id 23
Fitting GP model
[GPMXNetModel._posterior_for_state]
- self.mean = 0.4643531015560764
- self.std = 0.27373215983793886
BO Algorithm: Generating initial candidates.
BO Algorithm: Scoring (and reordering) candidates.
BO Algorithm: Selecting final set of candidates.
[GPMXNetModel.current_best -- RECOMPUTING]
- len(candidates) = 39
Current best is [0.18028404]
[23: BO] (25 evaluations)
batch_size: 9
dropout_1: 0.16072914348806375
dropout_2: 0.0
learning_rate: 0.001376475809627921
n_units_1: 128
n_units_2: 66
scale_1: 4.51193567432714
scale_2: 8.339615256729386
Started BO from (top scorer):
batch_size: 70
dropout_1: 0.16072911814660834
dropout_2: 0.05925522155820254
learning_rate: 0.0019714398213228606
n_units_1: 88
n_units_2: 66
scale_1: 4.518191497775782
scale_2: 5.428016900058286
Top score values: [0.13008039 0.14359533 0.17553767 0.1820455 0.27343393]
Labeled: 0:1, 0:3, 0:9, 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 6:3, 6:9, 7:1, 8:1, 9:1, 10:1, 11:1, 11:3, 12:1, 13:1, 13:3, 14:1, 14:3, 14:9, 15:1, 15:3, 16:1, 17:1, 17:3, 17:9, 18:1, 19:1, 19:3, 19:9, 20:1, 20:3, 21:1, 21:3, 22:1, 22:3. Pending:
Targets: [ 0.01606278 -0.58100199 -0.84168365 0.35137273 1.88184684 1.6573049
0.41742721 0.84611359 -0.48600755 -0.73827027 -1.07891701 1.81844951
1.37172553 1.81598943 1.69009039 -0.09902182 -0.40448 1.7521654
0.18609803 -0.43770994 -0.40233134 -0.79643553 -1.16989326 0.23224319
-0.3440355 1.83186976 -0.74927284 -0.98405157 -1.15491147 0.43629825
-0.70753984 -1.03776282 -1.28314108 -0.42972814 -0.72505455 -0.419003
-0.75067006 0.00448325 -0.68861754]
GP params:{'noise_variance': 1.0000000000000007e-09, 'kernel_inv_bw0': 0.685268695112951, 'kernel_inv_bw1': 0.00018046869895978142, 'kernel_inv_bw2': 0.576333883706921, 'kernel_inv_bw3': 7.658553558436415, 'kernel_inv_bw4': 0.4084432750494162, 'kernel_inv_bw5': 0.002265293744615886, 'kernel_inv_bw6': 0.004653979744777945, 'kernel_inv_bw7': 0.7395935215764463, 'kernel_inv_bw8': 1.0480594101621694, 'kernel_covariance_scale': 0.941687947464726, 'mean_mean_value': 0.9217972942451371}
Epoch 1 ; Time: 3.162787 ; Training: accuracy=0.422222 ; Validation: accuracy=0.603704
Update for config_id 23:1: reward = 0.6037037037037037, crit_val = 0.39629629629629626
config_id 23: Reaches 1, continues to 3
Epoch 2 ; Time: 6.263769 ; Training: accuracy=0.518574 ; Validation: accuracy=0.604714
Epoch 3 ; Time: 9.469267 ; Training: accuracy=0.525373 ; Validation: accuracy=0.592424
config_id 23: Terminating evaluation at 3
Update for config_id 23:3: reward = 0.5924242424242424, crit_val = 0.4075757575757576
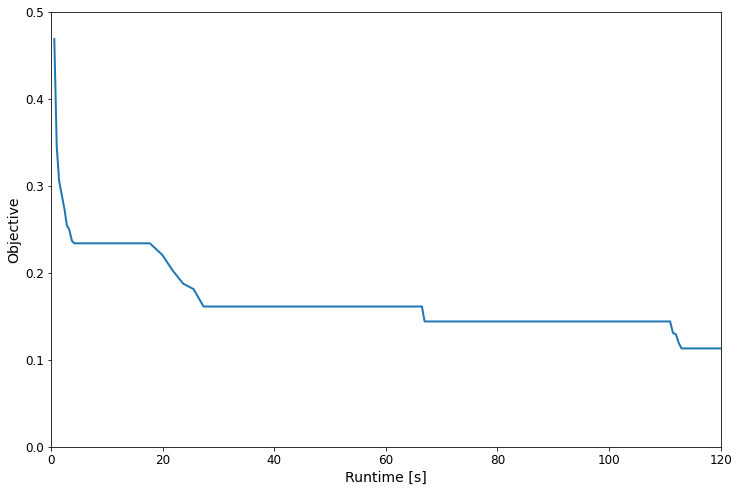
Analysing the results¶
The training history is stored in the results_df, the main fields
are the runtime and 'best' (the objective).
Note: You will get slightly different curves for different pairs of
scheduler/searcher, the time_out here is a bit too short to really
see the difference in a significant way (it would be better to set it to
>1000s). Generally speaking though, hyperband stopping / promotion +
model will tend to significantly outperform other combinations given
enough time.
results_df.head()
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
| bracket | elapsed_time | epoch | error | eval_time | objective | runtime | searcher_data_size | searcher_params_kernel_covariance_scale | searcher_params_kernel_inv_bw0 | ... | searcher_params_kernel_inv_bw7 | searcher_params_kernel_inv_bw8 | searcher_params_mean_mean_value | searcher_params_noise_variance | target_epoch | task_id | time_since_start | time_step | time_this_iter | best | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.490147 | 1 | 0.468750 | 0.483471 | 0.531250 | 0.578926 | NaN | 1.0 | 1.0 | ... | 1.0 | 1.0 | 0.0 | 0.001 | 9 | 0 | 0.581122 | 1.607457e+09 | 0.520655 | 0.468750 |
| 1 | 0 | 0.928254 | 2 | 0.344753 | 0.431203 | 0.655247 | 1.017033 | 1.0 | 1.0 | 1.0 | ... | 1.0 | 1.0 | 0.0 | 0.001 | 9 | 0 | 1.017834 | 1.607457e+09 | 0.438082 | 0.344753 |
| 2 | 0 | 1.358146 | 3 | 0.305314 | 0.428079 | 0.694686 | 1.446926 | 1.0 | 1.0 | 1.0 | ... | 1.0 | 1.0 | 0.0 | 0.001 | 9 | 0 | 1.447861 | 1.607457e+09 | 0.429894 | 0.305314 |
| 3 | 0 | 1.846933 | 4 | 0.288937 | 0.484237 | 0.711063 | 1.935713 | 2.0 | 1.0 | 1.0 | ... | 1.0 | 1.0 | 0.0 | 0.001 | 9 | 0 | 1.936584 | 1.607457e+09 | 0.488787 | 0.288937 |
| 4 | 0 | 2.315858 | 5 | 0.273061 | 0.466913 | 0.726939 | 2.404638 | 2.0 | 1.0 | 1.0 | ... | 1.0 | 1.0 | 0.0 | 0.001 | 9 | 0 | 2.405663 | 1.607457e+09 | 0.468925 | 0.273061 |
5 rows × 26 columns
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 8))
runtime = results_df['runtime'].values
objective = results_df['best'].values
plt.plot(runtime, objective, lw=2)
plt.xticks(fontsize=12)
plt.xlim(0, 120)
plt.ylim(0, 0.5)
plt.yticks(fontsize=12)
plt.xlabel("Runtime [s]", fontsize=14)
plt.ylabel("Objective", fontsize=14)
/var/lib/jenkins/miniconda3/envs/autogluon_docs-v0_0_15/lib/python3.7/site-packages/ipykernel/ipkernel.py:287: DeprecationWarning: should_run_async will not call transform_cell automatically in the future. Please pass the result to transformed_cell argument and any exception that happen during thetransform in preprocessing_exc_tuple in IPython 7.17 and above. and should_run_async(code)
Text(0, 0.5, 'Objective')
Diving Deeper¶
Now, you are ready to try HPO on your own machine learning models (if you use PyTorch, have a look at MNIST Training in PyTorch). While AutoGluon comes with well-chosen defaults, it can pay off to tune it to your specific needs. Here are some tips which may come useful.
Logging the Search Progress¶
First, it is a good idea in general to switch on debug_log, which
outputs useful information about the search progress. This is already
done in the example above.
The outputs show which configurations are chosen, stopped, or promoted.
For BO and BOHB, a range of information is displayed for every
get_config decision. This log output is very useful in order to
figure out what is going on during the search.
Configuring HyperbandScheduler¶
The most important knobs to turn with HyperbandScheduler are
max_t, grace_period, reduction_factor, brackets, and
type. The first three determine the rung levels at which stopping or
promotion decisions are being made.
The maximum resource level
max_t(usually, resource equates to epochs, somax_tis the maximum number of training epochs) is typically hardcoded intrain_fnpassed to the scheduler (this isrun_mlp_openmlin the example above). As already noted above, the value is best fixed in theag.argsdecorator asepochs=XYZ, it can then be accessed asargs.epochsin thetrain_fncode. If this is done, you do not have to passmax_twhen creating the scheduler.grace_periodandreduction_factordetermine the rung levels, which aregrace_period,grace_period * reduction_factor,grace_period * (reduction_factor ** 2), etc. All rung levels must be less or equal thanmax_t. It is recommended to makemax_tequal to the largest rung level. For example, ifgrace_period = 1,reduction_factor = 3, it is in general recommended to usemax_t = 9,max_t = 27, ormax_t = 81. Choosing amax_tvalue “off the grid” works against the successive halving principle that the total resources spent in a rung should be roughly equal between rungs. If in the example above, you setmax_t = 10, about a third of configurations reaching 9 epochs are allowed to proceed, but only for one more epoch.With
reduction_factor, you tune the extent to which successive halving filtering is applied. The larger this integer, the fewer configurations make it to higher number of epochs. Values 2, 3, 4 are commonly used.Finally,
grace_periodshould be set to the smallest resource (number of epochs) for which you expect any meaningful differentiation between configurations. Whilegrace_period = 1should always be explored, it may be too low for any meaningful stopping decisions to be made at the first rung.bracketssets the maximum number of brackets in Hyperband (make sure to study the Hyperband paper or follow-ups for details). Forbrackets = 1, you are running successive halving (single bracket). Higher brackets have larger effectivegrace_periodvalues (so runs are not stopped until later), yet are also chosen with less probability. We recommend to always consider successive halving (brackets = 1) in a comparison.Finally, with
type(valuesstopping,promotion) you are choosing different ways of extending successive halving scheduling to the asynchronous case. The method for the defaultstoppingis simpler and seems to perform well, butpromotionis more careful promoting configurations to higher resource levels, which can work better in some cases.
Asynchronous BOHB¶
Finally, here are some ideas for tuning asynchronous BOHB, apart from
tuning its HyperbandScheduling component. You need to pass these
options in search_options.
We support a range of different surrogate models over the criterion functions across resource levels. All of them are jointly dependent Gaussian process models, meaning that data collected at all resource levels are modelled together. The surrogate model is selected by
gp_resource_kernel, values arematern52,matern52-res-warp,exp-decay-sum,exp-decay-combined,exp-decay-delta1. These are variants of either a joint Matern 5/2 kernel over configuration and resource, or the exponential decay model. Details about the latter can be found here.Fitting a Gaussian process surrogate model to data encurs a cost which scales cubically with the number of datapoints. When applied to expensive deep learning workloads, even multi-fidelity asynchronous BOHB is rarely running up more than 100 observations or so (across all rung levels and brackets), and the GP computations are subdominant. However, if you apply it to cheaper
train_fnand find yourself beyond 2000 total evaluations, the cost of GP fitting can become painful. In such a situation, you can explore the optionsopt_skip_periodandopt_skip_num_max_resource. The basic idea is as follows. By far the most expensive part of aget_configcall (picking the next configuration) is the refitting of the GP model to past data (this entails re-optimizing hyperparameters of the surrogate model itself). The options allow you to skip this expensive step for mostget_configcalls, after some initial period. Check the docstrings for details about these options. If you find yourself in such a situation and gain experience with these skipping features, make sure to contact the AutoGluon developers – we would love to learn about your use case.