AutoMM for Text + Tabular - Quick Start#
![]()

In many applications, text data may be mixed with numeric/categorical data.
AutoGluon’s MultiModalPredictor can train a single neural network that jointly operates on multiple feature types,
including text, categorical, and numerical columns. The general idea is to embed the text, categorical and numeric fields
separately and fuse these features across modalities. This tutorial demonstrates such an application.
import numpy as np
import pandas as pd
import warnings
import os
warnings.filterwarnings('ignore')
np.random.seed(123)
!python3 -m pip install openpyxl
Collecting openpyxl
Downloading openpyxl-3.1.2-py2.py3-none-any.whl (249 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 250.0/250.0 kB 28.7 MB/s eta 0:00:00
?25hCollecting et-xmlfile (from openpyxl)
Downloading et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB)
Installing collected packages: et-xmlfile, openpyxl
Successfully installed et-xmlfile-1.1.0 openpyxl-3.1.2
Book Price Prediction Data#
For demonstration, we use the book price prediction dataset from the MachineHack Book Price Prediction Hackathon. Our goal is to predict a book’s price given various features like its author, the abstract, the book’s rating, etc.
!mkdir -p price_of_books
!wget https://automl-mm-bench.s3.amazonaws.com/machine_hack_competitions/predict_the_price_of_books/Data.zip -O price_of_books/Data.zip
!cd price_of_books && unzip -o Data.zip
!ls price_of_books/Participants_Data
--2023-06-30 21:08:22-- https://automl-mm-bench.s3.amazonaws.com/machine_hack_competitions/predict_the_price_of_books/Data.zip
Resolving automl-mm-bench.s3.amazonaws.com (automl-mm-bench.s3.amazonaws.com)... 52.217.192.121, 54.231.139.25, 52.217.236.225, ...
Connecting to automl-mm-bench.s3.amazonaws.com (automl-mm-bench.s3.amazonaws.com)|52.217.192.121|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3521673 (3.4M) [application/zip]
Saving to: ‘price_of_books/Data.zip’
price_of_books/Data 100%[===================>] 3.36M --.-KB/s in 0.02s
2023-06-30 21:08:22 (194 MB/s) - ‘price_of_books/Data.zip’ saved [3521673/3521673]
Archive: Data.zip
inflating: Participants_Data/Data_Test.xlsx
inflating: Participants_Data/Data_Train.xlsx
inflating: Participants_Data/Sample_Submission.xlsx
Data_Test.xlsx Data_Train.xlsx Sample_Submission.xlsx
train_df = pd.read_excel(os.path.join('price_of_books', 'Participants_Data', 'Data_Train.xlsx'), engine='openpyxl')
train_df.head()
| Title | Author | Edition | Reviews | Ratings | Synopsis | Genre | BookCategory | Price | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | The Prisoner's Gold (The Hunters 3) | Chris Kuzneski | Paperback,– 10 Mar 2016 | 4.0 out of 5 stars | 8 customer reviews | THE HUNTERS return in their third brilliant no... | Action & Adventure (Books) | Action & Adventure | 220.00 |
| 1 | Guru Dutt: A Tragedy in Three Acts | Arun Khopkar | Paperback,– 7 Nov 2012 | 3.9 out of 5 stars | 14 customer reviews | A layered portrait of a troubled genius for wh... | Cinema & Broadcast (Books) | Biographies, Diaries & True Accounts | 202.93 |
| 2 | Leviathan (Penguin Classics) | Thomas Hobbes | Paperback,– 25 Feb 1982 | 4.8 out of 5 stars | 6 customer reviews | "During the time men live without a common Pow... | International Relations | Humour | 299.00 |
| 3 | A Pocket Full of Rye (Miss Marple) | Agatha Christie | Paperback,– 5 Oct 2017 | 4.1 out of 5 stars | 13 customer reviews | A handful of grain is found in the pocket of a... | Contemporary Fiction (Books) | Crime, Thriller & Mystery | 180.00 |
| 4 | LIFE 70 Years of Extraordinary Photography | Editors of Life | Hardcover,– 10 Oct 2006 | 5.0 out of 5 stars | 1 customer review | For seven decades, "Life" has been thrilling t... | Photography Textbooks | Arts, Film & Photography | 965.62 |
We do some basic preprocessing to convert Reviews and Ratings in the data table to numeric values, and we transform prices to a log-scale.
def preprocess(df):
df = df.copy(deep=True)
df.loc[:, 'Reviews'] = pd.to_numeric(df['Reviews'].apply(lambda ele: ele[:-len(' out of 5 stars')]))
df.loc[:, 'Ratings'] = pd.to_numeric(df['Ratings'].apply(lambda ele: ele.replace(',', '')[:-len(' customer reviews')]))
df.loc[:, 'Price'] = np.log(df['Price'] + 1)
return df
train_subsample_size = 1500 # subsample for faster demo, you can try setting to larger values
test_subsample_size = 5
train_df = preprocess(train_df)
train_data = train_df.iloc[100:].sample(train_subsample_size, random_state=123)
test_data = train_df.iloc[:100].sample(test_subsample_size, random_state=245)
train_data.head()
| Title | Author | Edition | Reviews | Ratings | Synopsis | Genre | BookCategory | Price | |
|---|---|---|---|---|---|---|---|---|---|
| 949 | Furious Hours | Casey Cep | Paperback,– 1 Jun 2019 | 4.0 | NaN | ‘It’s been a long time since I picked up a boo... | True Accounts (Books) | Biographies, Diaries & True Accounts | 5.743003 |
| 5504 | REST API Design Rulebook | Mark Masse | Paperback,– 7 Nov 2011 | 5.0 | NaN | In todays market, where rival web services com... | Computing, Internet & Digital Media (Books) | Computing, Internet & Digital Media | 5.786897 |
| 5856 | The Atlantropa Articles: A Novel | Cody Franklin | Paperback,– Import, 1 Nov 2018 | 4.5 | 2.0 | #1 Amazon Best Seller! Dystopian Alternate His... | Action & Adventure (Books) | Romance | 6.893656 |
| 4137 | Hickory Dickory Dock (Poirot) | Agatha Christie | Paperback,– 5 Oct 2017 | 4.3 | 21.0 | There’s more than petty theft going on in a Lo... | Action & Adventure (Books) | Crime, Thriller & Mystery | 5.192957 |
| 3205 | The Stanley Kubrick Archives (Bibliotheca Univ... | Alison Castle | Hardcover,– 21 Aug 2016 | 4.6 | 3.0 | In 1968, when Stanley Kubrick was asked to com... | Cinema & Broadcast (Books) | Humour | 6.889591 |
Training#
We can simply create a MultiModalPredictor and call predictor.fit() to train a model that operates on across all types of features.
Internally, the neural network will be automatically generated based on the inferred data type of each feature column.
To save time, we subsample the data and only train for three minutes.
from autogluon.multimodal import MultiModalPredictor
import uuid
time_limit = 3 * 60 # set to larger value in your applications
model_path = f"./tmp/{uuid.uuid4().hex}-automm_text_book_price_prediction"
predictor = MultiModalPredictor(label='Price', path=model_path)
predictor.fit(train_data, time_limit=time_limit)
AutoGluon infers your prediction problem is: 'regression' (because dtype of label-column == float and many unique label-values observed).
Label info (max, min, mean, stddev): (9.115699967822062, 3.6109179126442243, 6.01144, 0.75972)
If 'regression' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Global seed set to 0
AutoMM starts to create your model. ✨
- AutoGluon version is 0.8.2b20230630.
- Pytorch version is 1.13.1+cu117.
- Model will be saved to "/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction".
- Validation metric is "rmse".
- To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction
```
Enjoy your coffee, and let AutoMM do the job ☕☕☕ Learn more at https://auto.gluon.ai
1 GPUs are detected, and 1 GPUs will be used.
- GPU 0 name: Tesla T4
- GPU 0 memory: 15.74GB/15.84GB (Free/Total)
CUDA version is 11.7.
Using 16bit None Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------------------------
0 | model | MultimodalFusionMLP | 109 M
1 | validation_metric | MeanSquaredError | 0
2 | loss_func | MSELoss | 0
----------------------------------------------------------
109 M Trainable params
0 Non-trainable params
109 M Total params
219.565 Total estimated model params size (MB)
Epoch 0, global step 4: 'val_rmse' reached 1.03433 (best 1.03433), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction/epoch=0-step=4.ckpt' as top 3
Epoch 0, global step 10: 'val_rmse' reached 0.96082 (best 0.96082), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction/epoch=0-step=10.ckpt' as top 3
Epoch 1, global step 14: 'val_rmse' reached 0.97462 (best 0.96082), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction/epoch=1-step=14.ckpt' as top 3
Epoch 1, global step 20: 'val_rmse' was not in top 3
Epoch 2, global step 24: 'val_rmse' reached 0.97217 (best 0.96082), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction/epoch=2-step=24.ckpt' as top 3
Epoch 2, global step 30: 'val_rmse' reached 0.86625 (best 0.86625), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction/epoch=2-step=30.ckpt' as top 3
Time limit reached. Elapsed time is 0:03:05. Signaling Trainer to stop.
Start to fuse 3 checkpoints via the greedy soup algorithm.
AutoMM has created your model 🎉🎉🎉
- To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction")
```
- You can open a terminal and launch Tensorboard to visualize the training log:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/tmp/4827d8eb124c4f2493dabe246ffeee58-automm_text_book_price_prediction
```
- If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://auto.gluon.ai/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub: https://github.com/autogluon/autogluon
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7f9afd070070>
Prediction#
We can easily obtain predictions and extract data embeddings using the MultiModalPredictor.
predictions = predictor.predict(test_data)
print('Predictions:')
print('------------')
print(np.exp(predictions) - 1)
print()
print('True Value:')
print('------------')
print(np.exp(test_data['Price']) - 1)
Predictions:
------------
1 455.721802
31 415.127441
19 1022.550903
45 567.360168
82 799.166748
Name: Price, dtype: float32
True Value:
------------
1 202.93
31 799.00
19 352.00
45 395.10
82 409.00
Name: Price, dtype: float64
performance = predictor.evaluate(test_data)
print(performance)
{'rmse': 0.7467434993157709}
embeddings = predictor.extract_embedding(test_data)
embeddings.shape
(5, 128)
What’s happening inside?#
Internally, we use different networks to encode the text columns, categorical columns, and numerical columns. The features generated by individual networks are aggregated by a late-fusion aggregator. The aggregator can output both the logits or score predictions. The architecture can be illustrated as follows:
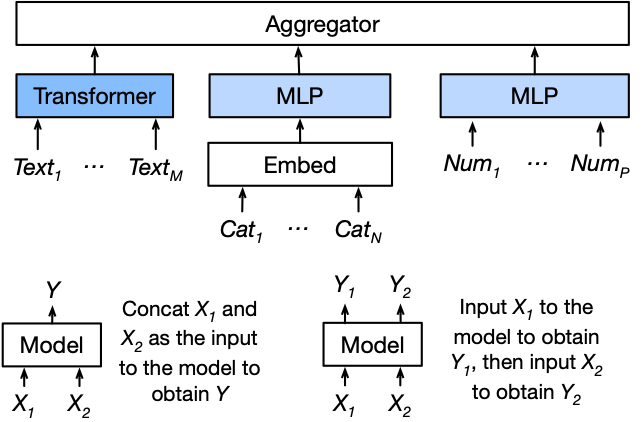
Here, we use the pretrained NLP backbone to extract the text features and then use two other towers to extract the feature from categorical column and the numerical column.
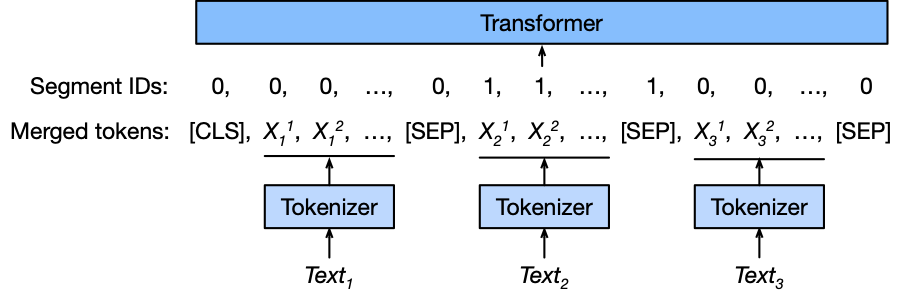
In addition, to deal with multiple text fields, we separate these fields with the [SEP] token and alternate 0s and 1s as the segment IDs, which is shown as follows:
How does this compare with TabularPredictor?#
Note that TabularPredictor can also handle data tables with text, numeric, and categorical columns, but it uses an ensemble of many types of models and may featurize text. MultiModalPredictor instead directly fuses multiple neural network models directly and handles
raw text (which are also capable of handling additional numerical/categorical columns). We generally recommend TabularPredictor if your table contains mainly numeric/categorical columns and MultiModalPredictor if your table contains mainly text columns,
but you may easily try both and we encourage this. In fact, TabularPredictor.fit(..., hyperparameters='multimodal') will train a MultiModalPredictor along with many other tabular models and ensemble them together.
Other Examples#
You may go to AutoMM Examples to explore other examples about AutoMM.
Customization#
To learn how to customize AutoMM, please refer to Customize AutoMM.