Version 1.0.0¶
Today is finally the day… AutoGluon 1.0 has arrived!! After over four years of development and 2061 commits from 111 contributors, we are excited to share with you the culmination of our efforts to create and democratize the most powerful, easy to use, and feature rich automated machine learning system in the world. AutoGluon 1.0 comes with transformative enhancements to predictive quality resulting from the combination of multiple novel ensembling innovations, spotlighted below. Besides performance enhancements, many other improvements have been made that are detailed in the individual module sections.
Note: Loading models trained on older versions of AutoGluon is not supported. Please re-train models using AutoGluon 1.0.
This release supports Python versions 3.8, 3.9, 3.10, and 3.11.
This release contains 223 commits from 17 contributors!
Full Contributor List (ordered by # of commits):
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
Join the community:
Get the latest updates:


Spotlight¶
Tabular Performance Enhancements¶
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. To the best of our knowledge, AutoGluon 1.0 marks the largest leap forward in the state-of-the-art for tabular data since the original AutoGluon paper from March 2020. The enhancements come primarily from two features: Dynamic stacking to mitigate stacked overfitting, and a new learned model hyperparameters portfolio via Zeroshot-HPO, obtained from the newly released TabRepo ensemble simulation library. Together, they lead to a 75% win-rate compared to AutoGluon 0.8 with faster inference speed, lower disk usage, and higher stability.
AutoML Benchmark Results¶
OpenML released the official 2023 AutoML Benchmark results on November 16th, 2023. Their results show AutoGluon 0.8 as the state-of-the-art in AutoML systems across a wide variety of tasks: “Overall, in terms of model performance, AutoGluon consistently has the highest average rank in our benchmark.” We now showcase that AutoGluon 1.0 achieves far superior results even to AutoGluon 0.8!
Below is a comparison on the OpenML AutoML Benchmark across 1040 tasks. LightGBM, XGBoost, and CatBoost results were obtained via AutoGluon, and other methods are from the official AutoML Benchmark 2023 results. AutoGluon 1.0 has a 95%+ win-rate against traditional tabular models, including a 99% win-rate vs LightGBM and a 100% win-rate vs XGBoost. AutoGluon 1.0 has between an 82% and 94% win-rate against other AutoML systems. For all methods, AutoGluon is able to achieve >10% average loss improvement (Ex: Going from 90% accuracy to 91% accuracy is a 10% loss improvement). AutoGluon 1.0 achieves first place in 63% of tasks, with lightautoml having the second most at 12% (AutoGluon 0.8 previously took first place 48% of the time). AutoGluon 1.0 even achieves a 7.4% average loss improvement over AutoGluon 0.8!
Method |
AG Winrate |
AG Loss Improvement |
Rescaled Loss |
Rank |
Champion |
|---|---|---|---|---|---|
AutoGluon 1.0 (Best, 4h8c) |
- |
- |
0.04 |
1.95 |
63% |
lightautoml (2023, 4h8c) |
84% |
12.0% |
0.2 |
4.78 |
12% |
H2OAutoML (2023, 4h8c) |
94% |
10.8% |
0.17 |
4.98 |
1% |
FLAML (2023, 4h8c) |
86% |
16.7% |
0.23 |
5.29 |
5% |
MLJAR (2023, 4h8c) |
82% |
23.0% |
0.33 |
5.53 |
6% |
autosklearn (2023, 4h8c) |
91% |
12.5% |
0.22 |
6.07 |
4% |
GAMA (2023, 4h8c) |
86% |
15.4% |
0.28 |
6.13 |
5% |
CatBoost (2023, 4h8c) |
95% |
18.2% |
0.28 |
6.89 |
3% |
TPOT (2023, 4h8c) |
91% |
23.1% |
0.4 |
8.15 |
1% |
LightGBM (2023, 4h8c) |
99% |
23.6% |
0.4 |
8.95 |
0% |
XGBoost (2023, 4h8c) |
100% |
24.1% |
0.43 |
9.5 |
0% |
RandomForest (2023, 4h8c) |
97% |
25.1% |
0.53 |
9.78 |
1% |
Not only is AutoGluon more accurate in 1.0, it is also more stable thanks to our new usage of Ray subprocesses during low-memory training, resulting in 0 task failures on the AutoML Benchmark.
AutoGluon 1.0 is capable of achieving the fastest inference throughput of any AutoML system while still obtaining state-of-the-art results.
By specifying the infer_limit fit argument, users can trade off between accuracy and inference speed to meet their needs.
As seen in the below plot, AutoGluon 1.0 sets the Pareto Frontier for quality and inference throughput, achieving Pareto Dominance compared to all other AutoML systems. AutoGluon 1.0 High achieves superior performance to AutoGluon 0.8 Best with 8x faster inference and 8x less disk usage!
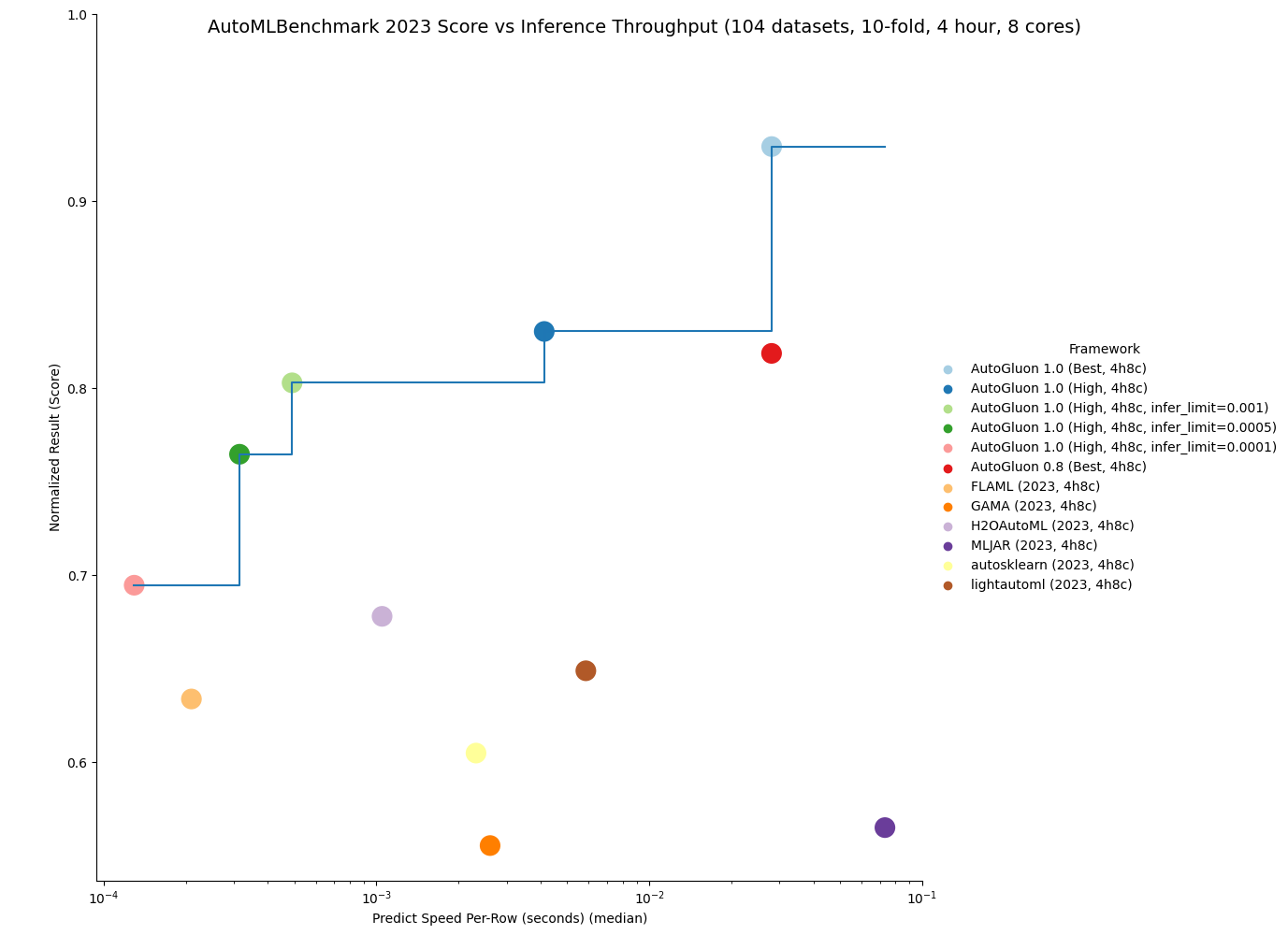
You can get more details on the results here.
We are excited to see what our users can accomplish with AutoGluon 1.0’s enhanced performance. As always, we will continue to improve AutoGluon in future releases to push the boundaries of AutoML forward for all.
AutoGluon Multimodal (AutoMM) Highlights in One Figure¶

AutoMM Uniqueness¶
AutoGluon Multimodal (AutoMM) distinguishes itself from other open-source AutoML toolboxes like AutosSklearn, LightAutoML, H2OAutoML, FLAML, MLJAR, TPOT and GAMA, which mainly focus on tabular data for classification or regression. AutoMM is designed for fine-tuning foundation models across multiple modalities—image, text, tabular, and document, either individually or combined. It offers extensive capabilities for tasks like classification, regression, object detection, named entity recognition, semantic matching, and image segmentation. In contrast, other AutoML systems generally have limited support for image or text, typically using a few pretrained models like EfficientNet or hand-crafted rules like bag-of-words as feature extractors. They often rely on traditional models or simple neural networks. AutoMM provides a uniquely comprehensive and versatile approach to AutoML, being the only AutoML system to support flexible multimodality and support for a wide range of tasks. A comparative table detailing support for various data modalities, tasks, and model types is provided below.
Data |
Task |
Model |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
image |
text |
tabular |
document |
any combination |
classification |
regression |
object detection |
semantic matching |
named entity recognition |
image segmentation |
traditional models |
deep learning models |
foundation models |
|
LightAutoML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
H2OAutoML |
✓ |
✓ |
✓ |
✓ |
||||||||||
FLAML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
MLJAR |
✓ |
✓ |
✓ |
✓ |
||||||||||
AutoSklearn |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||||
GAMA |
✓ |
✓ |
✓ |
✓ |
||||||||||
TPOT |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
||||||||
AutoMM |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
Special Thanks¶
We would like to conclude this spotlight by thanking Pieter Gijsbers, Sébastien Poirier, Erin LeDell, Joaquin Vanschoren, and the rest of the AutoML Benchmark authors for their key role in providing a shared and extensive benchmark to monitor the progress of the AutoML field. Their support has been invaluable to the AutoGluon project’s continued growth.
We would also like to thank Frank Hutter, who continues to be a leader within the AutoML field, for organizing the AutoML Conference in 2022 and 2023 to bring the community together to share ideas and align on a compelling vision.
Finally, we would like to thank Alex Smola and Mu Li for championing open source software at Amazon to make this project possible.
Additional Special Thanks¶
Special thanks to @LennartPurucker for leading development of dynamic stacking
Special thanks to @geoalgo for co-authoring TabRepo to enable Zeroshot-HPO
Special thanks to @ddelange for helping to add Python 3.11 support
Special thanks to @mglowacki100 for providing numerous feedback and suggestions
Special thanks to @Harry-zzh for contributing the new semantic segmentation problem type
General¶
Highlights¶
Python 3.11 Support @ddelange @yinweisu (#3190)
Other Enhancements¶
Added system info logging utility @Innixma (#3718)
Dependency Updates¶
Upgraded torch to
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588)Upgraded numpy to
>=1.21,<1.29@prateekdesai04 (#3709)Upgraded Pandas to
>=2.0,<2.2@yinweisu @tonyhoo @shchur (#3498)Upgraded scikit-learn to
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498)Upgraded Pillow to
>=10.0.1,<11@jaheba (#3688)Upgraded scipy to
>=1.5.4,<1.13@prateekdesai04 (#3709)Upgraded LightGBM to
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733)Upgraded XGBoost to
>=1.6,<2.1@Innixma (#3768)Various minor dependency updates @jaheba (#3689)
Tabular¶
Highlights¶
AutoGluon 1.0 features major enhancements to predictive quality, establishing a new state-of-the-art in Tabular modeling. Refer to the spotlight section above for more details!
New Features¶
Added
dynamic_stackingpredictor fit argument to mitigate stacked overfitting @LennartPurucker @Innixma (#3616)Added zeroshot-HPO learned portfolio as new hyperparameters for
best_qualityandhigh_qualitypresets. @Innixma @geoalgo (#3750)Added experimental scikit-learn API compatible wrappers to TabularPredictor. You can access them via
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor. @Innixma (#3769)Added
predictor.model_failures()@Innixma (#3421)Added enhanced FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
Added
predictor.simulation_artifact()to support integration with TabRepo @Innixma (#3555)
Performance Improvements¶
Enhanced FastAI model quality on regression via output clipping @LennartPurucker @Innixma (#3597)
Added Skip-connection Weighted Ensemble @LennartPurucker (#3598)
Fix memory leaks by using ray processes for sequential fitting @LennartPurucker (#3614)
Added dynamic parallel folds support to better utilize compute in low memory scenarios @yinweisu @Innixma (#3511)
Fixed linear model crashes during HPO and added search space for linear models @Innixma (#3571, #3720)
Other Enhancements¶
Multi-layer stacking now produces deterministic results @LennartPurucker (#3573)
Various model dependency updates @mglowacki100 (#3373)
Various code cleanup and logging improvements @Innixma (#3408, #3570, #3652, #3734)
Bug Fixes / Code and Doc Improvements¶
Fixed incorrect model memory usage calculation @Innixma (#3591)
Fixed
infer_limitbeing used incorrectly when bagging @Innixma (#3467)Fixed rare edge-case FastAI model crash @Innixma (#3416)
Various minor bug fixes @Innixma (#3418, #3480)
AutoMM¶
AutoGluon Multimodal (AutoMM) is designed to simplify the fine-tuning of foundation models for downstream applications with just three lines of code. It seamlessly integrates with popular model zoos such as HuggingFace Transformers, TIMM, and MMDetection, providing support for a diverse range of data modalities, including image, text, tabular, and document data, whether used individually or in combination.
New Features¶
Semantic Segmentation
Introducing the new problem type
semantic_segmentation, for fine-tuning Segment Anything Model (SAM) with three lines of code. @Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728)Added comprehensive benchmarks from diverse domains, including natural images, agriculture, remote sensing, and healthcare.
Utilizing parameter-efficient finetuning (PEFT) LoRA, showcasing consistent superior performance over alternatives (VPT, adaptor, BitFit, SAM-adaptor, and LST) in the extensive benchmarks.
Added one semantic segmentation tutorial @zhiqiangdon (#3716).
Using SAM-ViT Huge by default (GPU memory > 25GB required).
Few Shot Classification
Added the new
few_shot_classificationproblem type for training few shot classifiers on images or texts. @zhiqiangdon (#3662, #3681, #3695)Leveraging image/text foundation models to extract features and train SVM classifiers.
Added one few shot classification tutorial. @zhiqiangdon (#3662)
Supported torch.compile for faster training (experimental and torch >=2.2 required) @zhiqiangdon (#3520).
Performance Improvements¶
Improved default image backbones, achieving a 100% win-rate on the image benchmark. @taoyang1122 (#3738)
Replaced MLPs with FT-Transformer as the default tabular backbones, resulting in a 67% win-rate on the text+tabular benchmark. @taoyang1122 (#3732)
Using both the improved default image backbones and FT-Transformer achieves a 62% win-rate on the text+tabular+image benchmark. @taoyang1122 (#3732, #3738)
Stability Enhancements¶
Enabled rigorous multi-GPU CI testing. @prateekdesai04 (#3566)
Fixed multi-GPU issues. @FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
Enhanced Usability¶
Supported custom evaluation metrics, which allows defining custom metric object and passing it to the
eval_metricargument. @taoyang1122 (#3548)Supported multi-GPU training in notebooks (experimental). @zhiqiangdon (#3484)
Improved logging with system info. @zhiqiangdon (#3735)
Improved Scalability¶
The introduction of the new learner class design facilitates easier support for new tasks and data modalities within AutoMM, enhancing overall scalability. @zhiqiangdon (#3650, #3685, #3735)
Other Enhancements¶
Added the option
hf_text.use_fastfor customizing fast tokenizer usage inhf_textmodels. @zhiqiangdon (#3379)Added fallback evaluation/validation metric, supporting
f1_macrof1_micro, andf1_weighted. @FANGAreNotGnu (#3696)Supported multi-GPU inference with the DDP strategy. @zhiqiangdon (#3445, #3451)
Upgraded torch to 2.0. @zhiqiangdon (#3404)
Upgraded lightning to 2.0 @zhiqiangdon (#3419)
Upgraded torchmetrics to 1.0 @zhiqiangdon (#3422)
Code Improvements¶
Refactored AutoMM with the learner class for improved design. @zhiqiangdon (#3650, #3685, #3735)
Refactored FT-Transformer. @taoyang1122 (#3621, #3700)
Refactored the visualizers of object detection, semantic segmentation, and NER. @zhiqiangdon (#3716)
Other code refactor/clean-up: @zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
Bug Fixes/Doc Improvements¶
Fixed HPO for focal loss. @suzhoum (#3739)
Fixed one ONNX export issue. @AnirudhDagar (#3725)
Improved AutoMM introduction for clarity. @zhiqiangdon (#3388 #3726)
Improved AutoMM API doc. @zhiqiangdon @AnirudhDagar (#3772 #3777)
Other bug fixes @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
Other doc improvements @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
TimeSeries¶
Highlights¶
AutoGluon 1.0 features numerous usability and performance improvements to the TimeSeries module. These include automatic handling of missing data and irregular time series, new forecasting metrics (including custom metric support), advanced time series cross-validation options, and new forecasting models. AutoGluon produces state-of-the-art results in forecast accuracy, achieving 70%+ win rate compared to other popular forecasting frameworks.
New features¶
Support for custom forecasting metrics @shchur (#3760, #3602)
New forecasting metrics
WAPE,RMSSE,SQL+ improved documentation for metrics @melopeo @shchur (#3747, #3632, #3510, #3490)Improved robustness:
TimeSeriesPredictorcan now handle data with all pandas frequencies, irregular timestamps, or missing values represented byNaN@shchur (#3563, #3454)New models: intermittent demand forecasting models based on conformal prediction (
ADIDA,CrostonClassic,CrostonOptimized,CrostonSBA,IMAPA);WaveNetandNPTSfrom GluonTS; new baseline models (Average,SeasonalAverage,Zero) @canerturkmen @shchur (#3706, #3742, #3606, #3459)Advanced cross-validation options: avoid retraining the models for each validation window with
refit_every_n_windowsor adjust the step size between validation windows withval_step_sizearguments toTimeSeriesPredictor.fit@shchur (#3704, #3537)
Enhancements¶
Enable Ray Tune for deep-learning forecasting models @canerturkmen (#3705)
Support passing multiple evaluation metrics to
TimeSeriesPredictor.evaluate@shchur (#3646)Static features can now be passed directly to
TimeSeriesDataFrame.from_pathandTimeSeriesDataFrame.from_data_frameconstructors @shchur (#3635)
Performance improvements¶
Much more accurate forecasts at low time limits thanks to new presets and updated logic for splitting the training time across models @shchur (#3749, #3657, #3741)
Faster training and prediction + lower memory usage for
DirectTabularandRecursiveTabularmodels (#3740, #3620, #3559)Enable early stopping and improve inference speed for GluonTS models @shchur (#3575)
Reduce import time for
autogluon.timeseriesby moving import statements inside model classes (#3514)
Bug Fixes / Code and Doc Improvements¶
Improve log messages @shchur (#3721)
Add reference to the publication on AutoGluon-TimeSeries to README @shchur (#3482)
Align API of
TimeSeriesPredictorwithTabularPredictor, remove deprecated methods @shchur (#3714, #3655, #3396)General bug fixes and improvements @shchur(#3758, #3756, #3755, #3754, #3746, #3743, #3727, #3698, #3654, #3653, #3648, #3628, #3588, #3560, #3558, #3536, #3533, #3523, #3522, #3476, #3463)
EDA¶
The EDA module will be released at a later time, as it requires additional development effort before it is ready for 1.0.
We will make an announcement when EDA is ready for release. For now, please continue to use "autogluon.eda==0.8.2".
Deprecations¶
General¶
autogluon.core.spaceshas been deprecated. Please useautogluon.common.spacesinstead @Innixma (#3701)
Tabular¶
Tabular will log warnings if using the deprecated methods. Deprecated methods are planned to be removed in AutoGluon 1.2 @Innixma (#3701)
autogluon.tabular.TabularPredictorpredictor.get_model_names()->predictor.model_names()predictor.get_model_names_persisted()->predictor.model_names(persisted=True)predictor.compile_models()->predictor.compile()predictor.persist_models()->predictor.persist()predictor.unpersist_models()->predictor.unpersist()predictor.get_model_best()->predictor.model_bestpredictor.get_pred_from_proba()->predictor.predict_from_proba()predictor.get_oof_pred_proba()->predictor.predict_proba_oof()predictor.get_oof_pred()->predictor.predict_oof()predictor.get_model_full_dict()->predictor.model_refit_map()predictor.get_size_disk()->predictor.disk_usage()predictor.get_size_disk_per_file()->predictor.disk_usage_per_file()predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to FalseSame for
predictor.evaluate()andpredictor.evaluate_predictions()
AutoMM¶
Deprecated the
FewShotSVMPredictorin favor of the newfew_shot_classificationproblem type @zhiqiangdon (#3699)Deprecated the
AutoMMPredictorin favor ofMultiModalPredictor@zhiqiangdon (#3650)autogluon.multimodal.MultiModalPredictorDeprecated the
configargument in the fit API. @zhiqiangdon (#3679)Deprecated the
init_scratchandpipelinearguments in the init API @zhiqiangdon (#3668)
TimeSeries¶
autogluon.timeseries.TimeSeriesPredictorDeprecated argument
TimeSeriesPredictor(ignore_time_index: bool). Now, if the data contains irregular timestamps, either convert it to regular frequency withdata = data.convert_frequency(freq)or provide frequency when creating the predictor asTimeSeriesPredictor(freq=freq).predictor.evaluate()now returns a dictionary (previously returned a float)predictor.score()->predictor.evaluate()predictor.get_model_names()->predictor.model_names()predictor.get_model_best()->predictor.model_bestMetric
"mean_wQuantileLoss"has been renamed to"WQL"predictor.leaderboard()silentargument deprecated, replaced bydisplay, defaults to FalseWhen setting
hyperparametersto a string inpredictor.fit(), supported values are now"default","light"and"very_light"
autogluon.timeseries.TimeSeriesDataFramedf.to_regular_index()->df.convert_frequency()Deprecated method
df.get_reindexed_view(). Please see deprecation notes forignore_time_indexunderTimeSeriesPredictorabove for information on how to deal with irregular timestamps
Models
All models based on MXNet (
DeepARMXNet,MQCNNMXNet,MQRNNMXNet,SimpleFeedForwardMXNet,TemporalFusionTransformerMXNet,TransformerMXNet) have been removedStatistical models from Statmodels (
ARIMA,Theta,ETS) have been replaced by their counterparts from StatsForecast (#3513). Note that these models now have different hyperparameter names.DirectTabularis now implemented usingmlforecastbackend (same asRecursiveTabular), most hyperparameter names for the model have changed.
autogluon.timeseries.TimeSeriesEvaluatorhas been deprecated. Please use metrics available inautogluon.timeseries.metricsinstead.autogluon.timeseries.splitter.MultiWindowSplitterandautogluon.timeseries.splitter.LastWindowSplitterhave been deprecated. Please usenum_val_windowsandval_step_sizearguments toTimeSeriesPredictor.fitinstead (alternatively, useautogluon.timeseries.splitter.ExpandingWindowSplitter).
Papers¶
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting¶
We have published a paper on AutoGluon-TimeSeries at AutoML Conference 2023 (Paper Link, YouTube Video). In the paper, we benchmarked AutoGluon and popular open-source forecasting frameworks (including DeepAR, TFT, AutoARIMA, AutoETS, AutoPyTorch). AutoGluon produces SOTA results in point and probabilistic forecasting, and even achieves 65% win rate against the best-in-hindsight combination of models.
TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications¶
We have published a paper on Tabular Zeroshot-HPO ensembling simulation to arXiv (Paper Link, GitHub). This paper is key to achieving the performance improvements seen in AutoGluon 1.0, and we plan to continue to develop the code-base to support future enhancements.
XTab: Cross-table Pretraining for Tabular Transformers¶
We have published a paper on tabular Transformer pre-training at ICML 2023 (Paper Link, GitHub). In the paper we demonstrate state-of-the-art performance for tabular deep learning models, including being able to match the performance of XGBoost and LightGBM models. While the pre-trained transformer is not yet incorporated into AutoGluon, we plan to integrate it in a future release.
Learning Multimodal Data Augmentation in Feature Space¶
Our paper on learning multimodal data augmentation was accepted at ICLR 2023 (Paper Link, GitHub). This paper introduces a plug-and-play module to learn multimodal data augmentation in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that it can (1) improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data. This work is not yet incorporated into AutoGluon, but we plan to integrate it in a future release.
Data Augmentation for Object Detection via Controllable Diffusion Models¶
Our paper on generative object detection data augmentation has been accepted at WACV 2024 (Paper and GitHub link will be available soon). This paper proposes a data augmentation pipeline based on controllable diffusion models and CLIP, with visual prior generation to guide the generation and post-filtering by category-calibrated CLIP scores to control its quality. We demonstrate that the performance improves across various tasks and settings when using our augmentation pipeline with different detectors. Although diffusion models are currently not integrated into AutoGluon, we plan to incorporate the data augmentation techniques in a future release.
Adapting Image Foundation Models for Video Understanding¶
We have published a paper on how to efficiently adapt image foundation models for video understanding at ICLR 2023 (Paper Link, GitHub). This paper introduces spatial adaptation, temporal adaptation and joint adaptation to gradually equip a frozen image model with spatiotemporal reasoning capability. The proposed method achieves competitive or even better performance than traditional full finetuning while largely saving the training cost of large foundation models.